AutoRec: Autoencoders Meet Collaborative Filtering
Suvash Sedhain, Aditya Krishna Menon, Scott Sanner, Lexing Xie
Abstract
이 논문에서는 collaborative filtering(CF)을 위한 새로운 autoencoder 프레임워크인 AutoRec를 제안한다. 실증적으로, AutoRec를 이용하여 적절하게 설계된 모델은 Movielens와 Netflix 데이터셋을 이용한 CF 기술에서 SOTA를 달성했다.
Background
Collaborative Filtering
협업 필터링(Collaborative Filtering)은 사용자와 아이템 간의 상호 관계(interaction)를 기반으로 사용자들에게 적절한 추천을 제공하는 머신 러닝 기반의 추천 시스템 방법이다. 따라서 유저, 아이템의 profile을 만들어서 유저가 선호하는 아이템의 profile과 유사한 profile을 갖고 있는 아이템을 추천해주는 컨텐츠 기반 필터링과 달리 profile 없이, 평점과 방문기록 등의 과거 상호관계에 기반하여 추천을 제공한다. 예를들어 CF는 "유저 A와 B가 아이템 1에 대하여 비슷한 평가를 내렸다면, 유저 A가 선호하는 다른 아이템인 2에 대해서도 유저 B가 비슷한 선호도를 가지고 있지 않을까?" 라는 아이디어를 차용한 것이다. 아래의 그림을 보면 이해하는데 큰 도움이 된다.


Auto Encoder
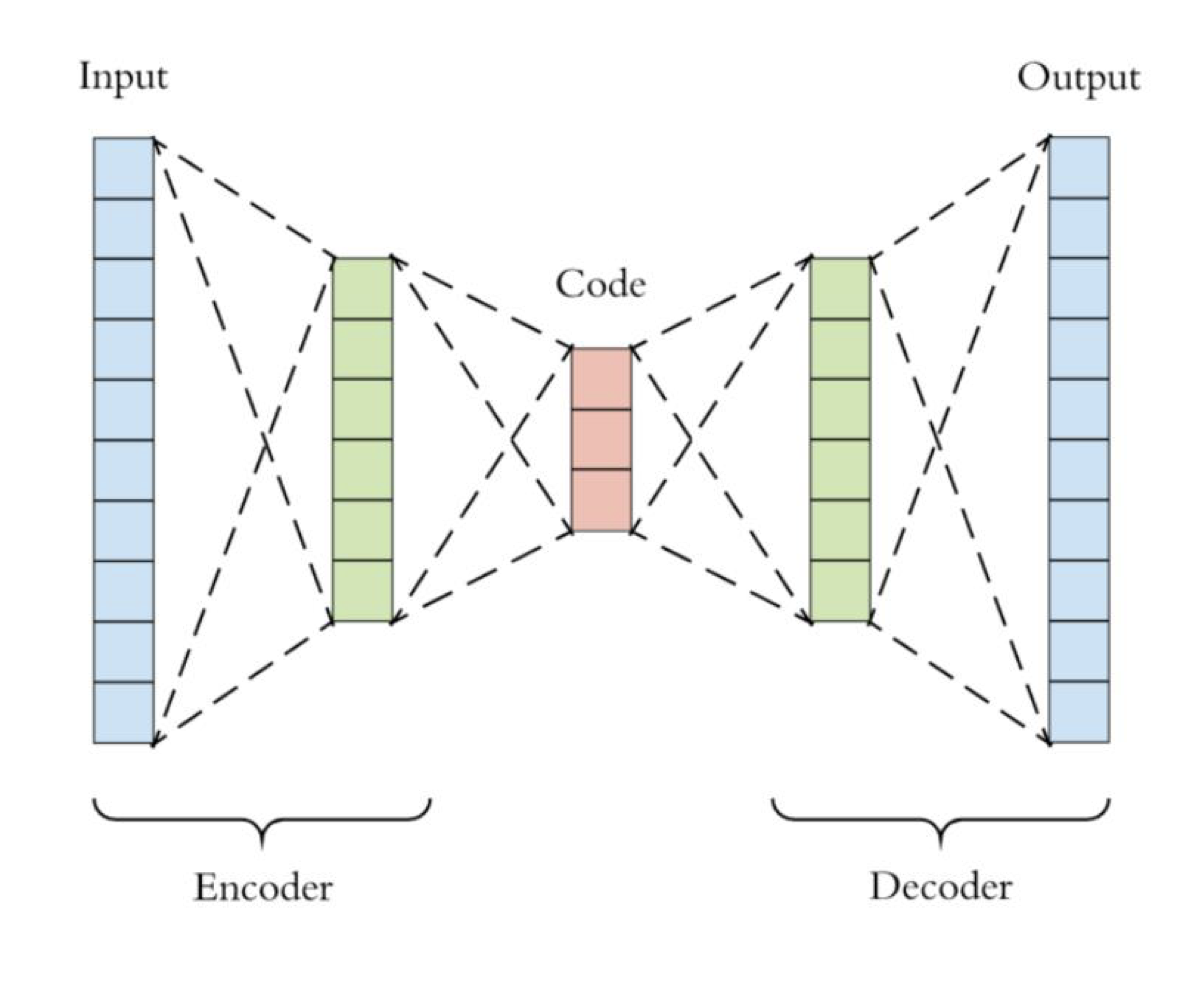
오토인코더(Autoencoder)는 신경망을 기반으로 한 비지도 학습 알고리즘이다. 오토인코더의 핵심 목적은 입력 데이터의 표현을 압축하고, 복원력이 있는 저차원 잠재 공간(Latent Space)을 학습하는 것이다. 이를 통해 데이터 압축, 차원 축소, 노이즈 제거 등 다양한 응용 분야에 활용할 수 있다. 오토인코더는 크게 두 가지 구성 요소로 나뉜다.
인코더(Encoder): 입력 데이터를 잠재 공간으로 mapping하는 함수이다. 인코더는 입력 데이터의 차원을 축소하면서도 원본 데이터 핵심 특성을 보존하려는 목표를 갖는다.
디코더(Decoder): 잠재 공간에서 원본 입력 데이터를 재구성하는 함수이다. 디코더의 목표는 원본 데이터를 최대한 정확하게 복원하려는 것이다.
학습은 일반적으로 아래와 같은 모델 Output과 Input 사이의 RMSE를 최소화하는 방향으로 진행된다.

AutoRec
협업 필터링에서는 m명의 사용자와 n개의 아이템이 있으며, m x n 크기의 부분적으로 채워진 사용자-아이템 평가 행렬 R이 존재한다. 각 사용자 u는 n개의 아이템에 대해 평가를 한 부분적으로 채워진 벡터 r(u)로 나타낼 수 있으며, 각 아이템 i는 m명의 사용자들이 한 부분적으로 채워진 평가 행렬에서 i번째 열을 추출하여 얻은 벡터 r(i)로 나타낼 수 있다. 이러한 문제를 해결하기 위해서 부분적으로 채워진 r(i) 또는 r(u)를 입력으로 받아, 낮은 차원의 잠재 공간으로 투영한 후 다시 출력 공간에서 원래 벡터를 재구성하여 빠짐없이 평가된 경우를 추측한다. 이렇게 추측된 평가는 추천을 위한 기반 자료로 사용된다.

위는 Item-based AutoRec모델을 설명하는 그림이다. Item-based AutoRec 모델은 각 아이템을 대상으로 하나의 신경망을 생성하여 모든 아이템에 대한 예측을 수행한다. 이 때, "plate notation"이라는 표기법을 사용해서 각각의 신경망 copy를 나타낸다. Plate notation은 반복적으로 나타난 유사한 변수를 하나의 그룹으로 묶어서 나타내는 방식으로, AutoRec 논문에서는 각각의 아이템에 대응하는 하나의 그룹으로 나타내어 각 신경망에 대한 표기를 간단히 한다. 위 그림에서의 W와 V는 모든 copies에서 더 이상 독립적인 매개변수가 아닌, 모든 copies간에 Tie된 매개변수를 의미한다. 이러한 구조로 인하여 학습해야 할 매개변수의 개수를 줄일 수 있으며, 이로 인해 모델의 일반화 능력을 더욱 향상시킬 수 있다는 장점이 있다.
이때 각각의 r(i)가 부분적으로 관측되었다는 것을 고려하여, 행렬 인수분해 및 RBM(Restricted Boltzman Machine, 추후에 자세히 다루도록하자) 접근 방식에서 일반적으로 일어나는 것처럼 관측된 입력과 관련된 가중치만을 업데이트하여 backpropagation을 수행하고 관측된 평가에서의 과적합을 방지하기 위해 학습된 매개변수를 규제한다.
Result
모델에 비선형성을 부여하는 sigmoid 함수가 성능향상에 크게 도움이 됨을 확인할 수 있다.

기존의 Baseline 모델들과의 성능 비교를 하면 I-AutoRec이 가장 낮은 RMSE를 달성하여 SOTA를 달성하였음을 알 수 있다.

Hidden unit의 수가 커져서 AutoRec이 깊어짐에 따른 RMSE의 성능을 비교한 결과이다.

깊은 AutoRec의 성능이 더 좋음을 알 수 있다.
'Drawing (AI) > Paper review' 카테고리의 다른 글
| BERT(1) (0) | 2023.08.02 |
|---|---|
| [논문 리뷰] Attention is all you need (2) (0) | 2023.07.25 |
| [논문 리뷰] Attention is all you need(1) (1) | 2023.07.19 |
| [논문 리뷰] Long Short-Term Memory (0) | 2023.03.12 |
| [논문 리뷰] Deep Sparse Rectifier Neural Networks (2) | 2023.02.05 |



