Bert: Pre-training of deep bidirectional transformers for language understanding
Jacob Devlin, Ming-Wei Chang, Kenton Lee, Kristina Toutanova
Google AI Language
Background
Pre-trained Language Model

2015년 구글은 'Semi-supervised Sequence Learning'라는 논문에서 LSTM 언어 모델을 학습하고나서 이렇게 학습한 LSTM을 텍스트 분류에 추가 학습하는 방법을 보였다. 이 방법은 우선 LSTM 언어 모델을 학습합니다. 언어 모델은 주어진 텍스트로부터 이전 단어들로부터 다음 단어를 예측하도록 학습하므로 기본적으로 별도의 레이블이 부착되지 않은 텍스트 데이터로도 학습 가능하다. 사전 훈련된 워드 임베딩과 마찬가지로 사전 훈련된 언어 모델의 강점은 학습 전 사람이 별도 레이블을 지정해줄 필요가 없다는 점이다. 그리고 이렇게 레이블이 없는 데이터로 학습된 LSTM과 가중치가 랜덤으로 초기화 된 LSTM 두 가지를 두고, 텍스트 분류와 같은 문제를 학습하여 사전 훈련된 언어 모델을 사용한 전자의 경우가 더 좋은 성능을 얻을 수 있다는 가능성을 보였다. 방대한 텍스트로 LSTM 언어 모델을 학습해두고, 언어 모델을 다른 태스크에서 높은 성능을 얻기 위해 사용하는 방법으로 ELMo와 같은 아이디어도 존재하다. 이는 간단히만 보고 자세히는 다음에 다뤄보도록 하자.
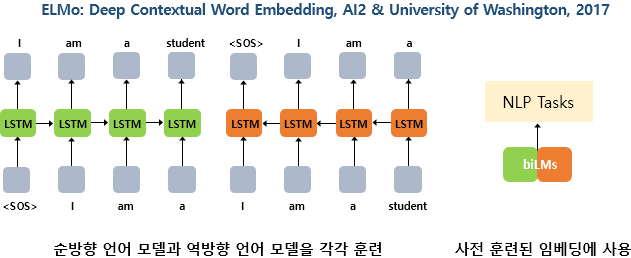
ELMo는 순방향 언어 모델과 역방향 언어 모델을 각각 따로 학습시킨 후에, 이렇게 사전 학습된 언어 모델로부터 임베딩 값을 얻는다는 아이디어였다. 이러한 임베딩은 문맥에 따라서 임베딩 벡터값이 달라지므로, 기존 워드 임베딩인 Word2Vec이나 GloVe 등이 다의어를 구분할 수 없었던 문제점을 해결할 수 있었다. 이어 언어 모델은 RNN 계열의 신경망에서 탈피하기 시작했다. 트랜스포머가 번역기와 같은 인코더-디코더 구조에서 LSTM을 뛰어넘는 좋은 성능을 얻자, LSTM이 아닌 트랜스포머로 사전 훈련된 언어 모델을 학습하는 시도가 등장했다.

위의 그림에서 Trm은 트랜스포머(Transformer)의 약자이다. 트랜스포머의 디코더는 LSTM 언어 모델처럼 순차적으로 이전 단어들로부터 다음 단어를 예측한다. Open AI는 트랜스포머 디코더로 총 12개의 층을 쌓은 후에 방대한 텍스트 데이터를 학습시킨 언어 모델 GPT-1을 만들었다. Open AI는 GPT-1에 여러 다양한 태스크를 위해 추가 학습을 진행하였을 때, 다양한 태스크에서 높은 성능을 얻을 수 있음을 입증했다. NLP의 주요 트렌드는 사전 훈련된 언어 모델을 만들고 이를 특정 태스크에 추가 학습시켜 해당 태스크에서 높은 성능을 얻는 것으로 접어들었고, 언어 모델의 학습 방법에 변화를 주는 모델들이 등장했다.

위의 좌측 그림에 있는 단방향 언어모델은 전형적인 언어 모델이다. 시작 토큰 <SOS>가 들어가면, 다음 단어 I를 예측하고 그리고 그 다음 단어 am을 예측한다. 반면, 우측에 있는 양방향 언어 모델은 지금까지 본 적 없던 형태의 언어 모델이다. 실제로 이렇게 구현하는 경우는 거의 없는데 그 이유가 무엇일까? 가령, 양방향 LSTM을 이용해서 우측과 같은 언어 모델을 만들었다고 해보자. 초록색 LSTM 셀은 순방향 언어 모델로 <sos>를 입력받아 I를 예측하고, 그 후에 am을 예측한다. 그런데 am을 예측할 때, 출력층은 주황색 LSTM 셀인 역방향 언어 모델의 정보도 함께 받고있다. 그런데 am을 예측하는 시점에서 역방향 언어 모델이 이미 관측한 단어는 a, am, I 이렇게 3개의 단어이다. 이미 예측해야하는 단어를 역방향 언어 모델을 통해 미리 관측한 셈이므로 언어 모델은 일반적으로 양방향으로 구현하지 않는다.
하지만 언어의 문맥이라는 것은 실제로는 양방향이다. 텍스트 분류나 개체명 인식 등에서 양방향 LSTM을 사용하여 모델을 구현해서 좋은 성능을 얻을 수 있었던 것을 생각해보면 된다. 하지만 이전 단어들로부터 다음 단어를 예측하는 언어 모델의 특성으로 인해 위의 그림과 같은 양방향 언어 모델을 사용할 수 없으므로, 그 대안으로 ELMo에서는 순방향과 역방향이라는 두 개의 단방향 언어 모델을 따로 준비하여 학습하는 방법을 사용했던 것이다. 이와 같이 기존 언어 모델로는 양방향 구조를 도입할 수 없으므로, 양방향 구조를 도입하기 위해서 2018년에는 새로운 구조의 언어 모델이 탄생했는데 바로 마스크드 언어 모델이다.
마스크드 언어 모델(Masked Language Model)
마스크드 언어 모델은 입력 텍스트의 단어 집합의 15%의 단어를 랜덤으로 마스킹(Masking)한다. 여기서 마스킹이란 원래의 단어가 무엇이었는지 모르게 한다는 뜻이다. 그리고 인공 신경망에게 이렇게 마스킹 된 단어들을(Masked words) 예측하도록 한다. 문장 중간에 구멍을 뚫어놓고, 구멍에 들어갈 단어들을 예측하게 하는 식이다. 우리가 영어 시험을 볼 때 종종 마주하는 빈칸 채우기 문제에 비유할 수 있습니다. 예를 들어 '나는 [MASK]에 가서 그곳에서 빵과 [MASK]를 샀다'를 주고 [MASK]에 들어갈 단어를 맞추게 한다. META의 Vision 분야 최신 논문을 보면 VIT를 이용하고 마스킹을 하여 사진의 일부를 가리면 모델이 예측하는 과정을 통해 학습을 시켜 좋은 성능을 내는 것을 볼 수 있다.
'Robotics & AI > Paper review' 카테고리의 다른 글
| BERT(3) (0) | 2023.08.20 |
|---|---|
| BERT(2) (0) | 2023.08.13 |
| [논문 리뷰] Attention is all you need (2) (0) | 2023.07.25 |
| [논문 리뷰] Attention is all you need(1) (1) | 2023.07.19 |
| [논문 리뷰] AutoRec: Autoencoders Meet Collaborative Filtering (0) | 2023.07.10 |



