특성 교차
특성 교차는 두 개 이상의 특성을 곱하여 (교차하여) 구성되는 합성 특성이다. 특성 조합을 교차하면 이러한 특성이 개별적으로 제공할 수 있는 것 이상의 예측 기능을 제공할 수 있다.

위와 같은 상태에서 선형 모델로 구분을 해내는 것은 불가능하다. 이떄 x1과 x2의 곱인 x3을 추가적인 feature로 이용하면 곱이 양수인 blue dot과 곱이 음수인 red dot을 구분해낼 수 있다. 선형 모델로 비선형성을 학습 시킬 수 있는 것이다. 이렇게 다른 변수의 곱으로 합성 특성을 만드는 과정을 일반적으로 특성 교차 곱이라고 부른다. 특성 교차와 대량의 데이터 사용은 매우 복잡한 모델을 학습할 수 있는 효율적인 전략 중 하나이다.
원-핫 벡터 교차
지금까지는 두 개의 개별 부동 소수점 특성을 특성 교차하는 데 집중했다. 실제로 머신러닝 모델에서 연속 특성이 거의 사용되는 경우는 거의 없다. 그러나 머신러닝 모델은 원-핫 특성 벡터를 교차하는 경우가 많다. 원-핫 특성 벡터의 특성 교차를 논리 결합이라고 생각하면 된다. 예를 들어 국가와 언어라는 두 가지 특성이 있다고 가정한다. 각각의 원-핫 인코딩은 country=USA, country=France 또는 language=English, language=Spanish로 해석될 수 있는 바이너리 특성이 있는 벡터를 생성한다. 그런 다음 이러한 원-핫 인코딩의 특성 교차를 수행하면 논리적 결합으로 해석될 수 있는 다음과 같은 바이너리 특성을 얻게 된다.
country:usa AND language:spanish
또 다른 예로, 위도와 경도를 비닝하여 별도의 원-핫 5개 요소 특징 벡터를 생성한다고 가정해 보겠다. 예를 들어 특정 위도 및 경도는 다음과 같이 나타낼 수 있다.
binned_latitude = [0, 0, 0, 1, 0]
binned_longitude = [0, 1, 0, 0, 0]
이 두 특성 벡터의 특성 교차를 만든다고 가정해 보자.
binned_latitude X binned_longitude
이 특성 교차는 25개 요소로 구성된 원-핫 벡터 (0은 24개, 1은 1개)이다. 교차에 있는 단일 1는 위도와 경도의 특정 결합을 식별한다. 그러면 모델이 이 결합에 대한 특정 연결을 학습할 수 있다. 위도 및 경도를 다음과 같이 훨씬 더 대략적으로 data binning한다고 가정하자.
binned_latitude(lat) = [
0 < lat <= 10
10 < lat <= 20
20 < lat <= 30
]
binned_longitude(lon) = [
0 < lon <= 15
15 < lon <= 30
]
대략적 특성 구간을 교차하는 특성 교차를 만들면 다음과 같은 의미를 갖는 합성 특성이 생성된다.
binned_latitude_X_longitude(lat, lon) = [
0 < lat <= 10 AND 0 < lon <= 15
0 < lat <= 10 AND 15 < lon <= 30
10 < lat <= 20 AND 0 < lon <= 15
10 < lat <= 20 AND 15 < lon <= 30
20 < lat <= 30 AND 0 < lon <= 15
20 < lat <= 30 AND 15 < lon <= 30
]
이제 모델이 다음 두 특성을 기반으로 개에 대한 만족도를 살펴볼 필요가 있다고 가정해 보자.
행동 유형 (짖는 소리, 울음, 껴안기 등), 시간의 두 특성에서 특성 교차를 구축하면 다음과 같은 결과가 나타난다.
[behavior type X time of day]
그러면 두 기능 자체보다 훨씬 더 예측 성능이 좋은 결과를 얻게 된다. 예를 들어 강아지가 주인이 퇴근 후 오후 5시에 애교를 부리면 주인이 아주 만족할 것이라고 긍정적인 예측을 할 것이다. 반면에 강아지가 오전에 새벽 3시에 짖어댄다고 하면 주인의 만족도를 예측할 때 강력한 부정적인 요인이 될 수 있다. 이 외에도 대규모 데이터 세트에서 특성 교차를 사용하는 것은 매우 복잡한 모델을 학습할 수 있는 효율적인 전략 중 하나이다.
실습
x1이나 x2만 사용한 결과 충분한 에폭동안 학습을 해도 loss가 줄지않는 것을 볼 수 있다.
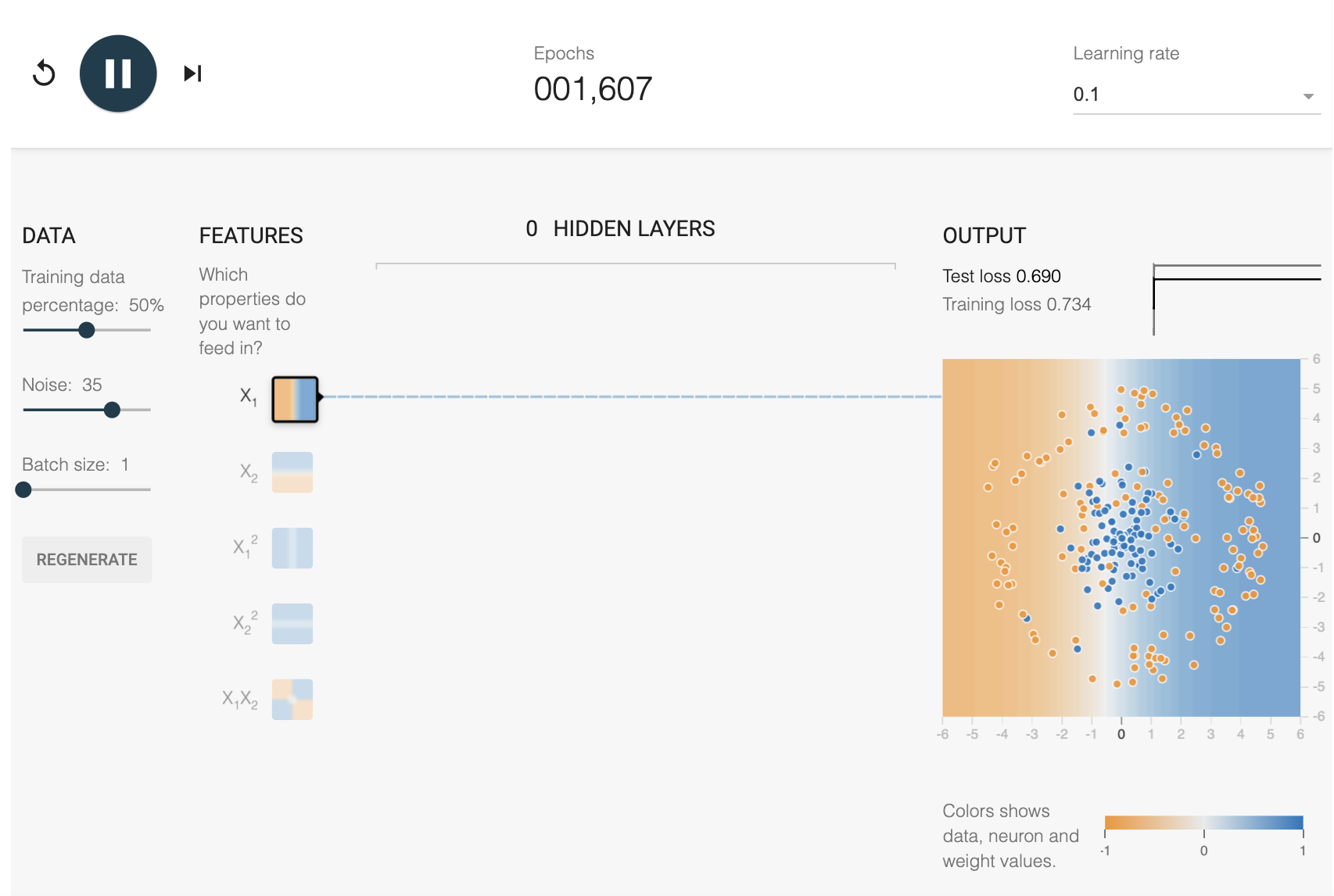

이때 비선형적인 feature를 이용하면 아래와 같이 적절한 결과를 낼 수 있다.
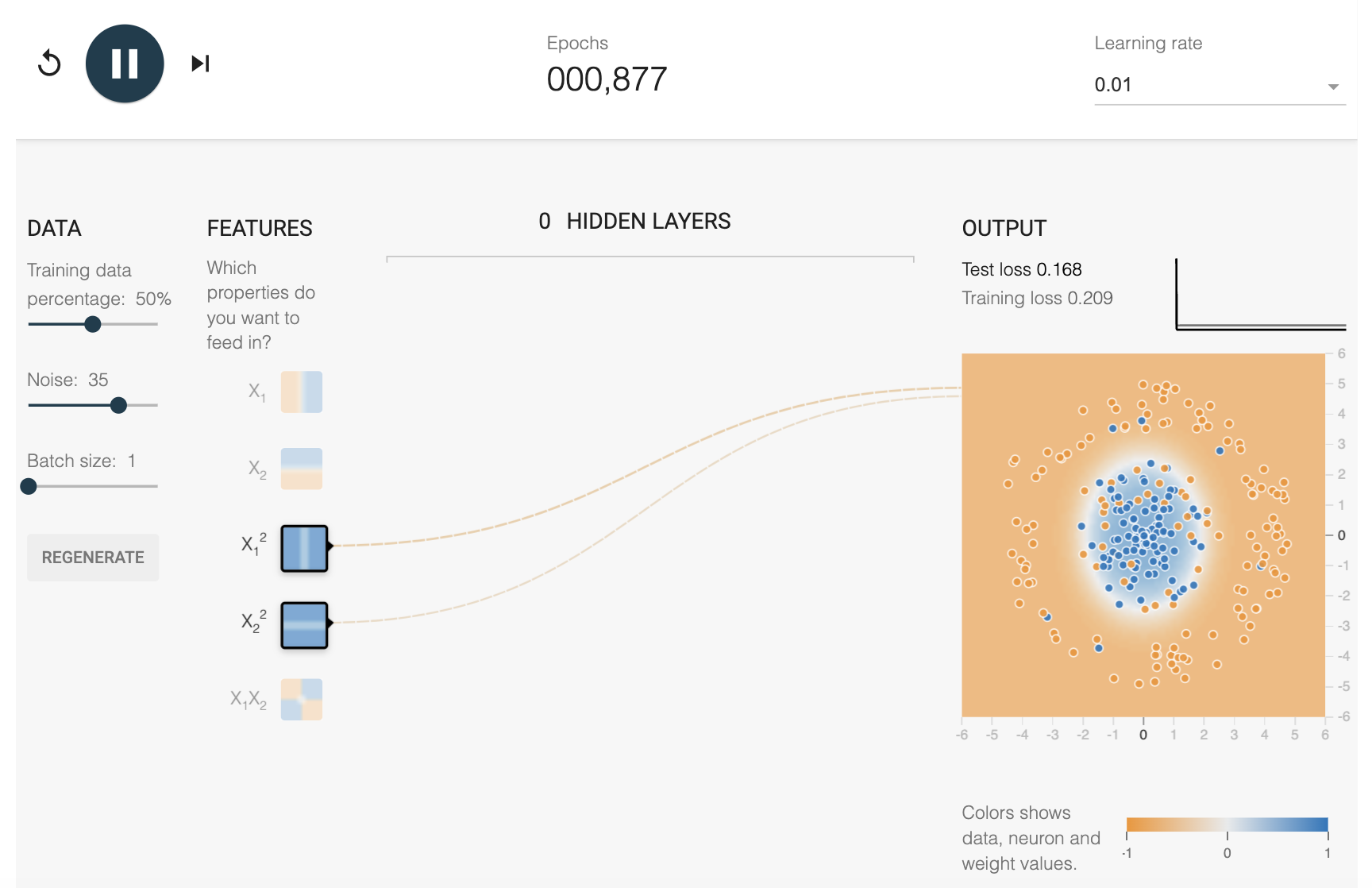
이때 xy곱을 이용하면 비션형 모델을 구현하여 단순선형모델보다 뛰어난 성능을 낼 수 있음을 볼 수 있다.

'Drawing (AI) > Google' 카테고리의 다른 글
| Google ML crash course (8) (0) | 2023.03.19 |
|---|---|
| Google ML crash course (7) (0) | 2023.03.07 |
| Google ML crash course (6) (0) | 2023.02.27 |
| Google ML crash course (5) (1) | 2023.02.25 |
| Google ML crash course (4) (0) | 2022.12.26 |



