Validation

Training set과 test set을 이용해 모델 개발을 반복하는 방식은 반복할때마다 학습 데이터를 학습하고 테스트 데이터를 평가하여 그 평가 결과를 사용하여 learning rate와 feature과 같은 다양한 모델 초매개변수의 선택 및 변경사항을 결정한다. 이러한 반복은 비용이 많이 발생하지만 모델 개발에서 중요한 부분이다. 초매개변수 설정은 모델 품질을 크게 향상할 수 있으며, 가능한 한 최상의 품질을 얻을 수 있도록 항상 시간과 컴퓨팅 리소스에 예산을 투자해야 한다.
그러나 여기에는 문제가 있다. Training set에 반복하여 학습할 경우 과적합의 위험이 점점 증가한다는 것이다. 따라서 이러한 문제를 방지하기 위해 Validation set(검증데이터)를 구축한다.
Validation set
모집단에서 위와 같이 3번째 데이터 세트인 Validation Set을 만들어둔다.
학습데이터로 학습만 시키고 데이터를 평가할 때는 검증데이터만 사용하는 개선된 프로토콜이다.
검증 데이터에서 좋은 결과가 나올때까지 반복하고 매개변수와 모델을 수정하는 과정을 거친후에 최종 테스트 데이터를 대상으로 테스트를 진행한다.
이때 나온 결과가 검증데이터에서 테스트했을때의 결과와 다르다면 검증데이터에 과적합된 모델일 가능성이 높다.
Representation
머신러닝 모델은 입력 예를 직접 보거나 듣거나 감지할 수 없다. 대신 데이터의 represtation을 만들어 모델에 데이터의 핵심 품질을 나타내는 유용한 시점을 제공해야 한다. 즉, 모델을 학습시키려면 데이터를 가장 잘 나타내는 특성 집합을 선택해야 한다.
Feature engineering
왼쪽은 입력 데이터 소스의 원시 데이터를 보여주며, 오른쪽은 데이터 세트의 예를 구성하는 부동 소수점 값 집합인 특성 벡터를 보여준다. 특성 추출은 원시 데이터를 특성 벡터로 변환하는 과정을 의미한다. 많은 머신러닝 모델은 특성을 실수 벡터로 표현해야 한다. 이 특성 값에 모델 가중치를 곱해야 하기 때문이다.
정수와 부동 소수점 데이터에는 숫자 가중치를 곱할 수 있으므로 특수 인코딩이 필요하지 않다. 다음과 같이 원시 정수 값 6을 특성 값 6.0으로 변환하는 것은 간단한 작업이다.
범주형 데이터는 이전에도 많이 다뤄본 one-hot-encoding을 이용한다. 각각의 데이터에 0,1,2,3,4와 같은 특성 숫자를 부여하지 않는것은 가중치 연산을 진행해야하기 때문이다.
Sparse Representation
이전에 Rectifier function에 대한 논문을 리뷰할때 참 많이 헷갈렸던 개념이다.
예를들어 데이터 세트에 1,000,000개의 서로 다른 거리 이름이 street_name의 값으로 포함한다고 가정하면다. 1개 또는 2개 요소만 참인 1,000,000개 요소로 구성된 바이너리 벡터를 명시적으로 만드는 것은 이러한 벡터를 처리할 때 스토리지와 계산 시간 측면에서 매우 비효율적인 표현이다. 이 상황에서 일반적인 방법은 0이 아닌 값만 저장되는 희소표현을 사용하는 것이다. 희소 표현에서는 위에서 설명한 대로 여전히 각 특성 값의 독립 모델 가중치가 학습된다.
다시말해 one-hot-encoding방식으로 인코딩이 진행된 데이터같은 대부분이 0인 데이터의 전체 데이터를 모두 사용하지 않고, 중요한 정보가 있는 일부분만을 선택하여 처리하면 계산 비용을 줄이고 성능을 향상시키는 방법이다. 이미지분류나 자연어처리 같은 작업에서 데이터를 다룰때도 유용하게 쓰이는 경우가 많다.
Qualities of Good Features
거의 사용되지 않는 개별 특성 값 피하기
좋은 특성값은 데이터 세트에 5번 이상 표시되어야 한다. 이렇게 하면 모델이 이 특성 값이 라벨과 어떤 관련이 있는지 학습할 수 있다. 즉, 동일한 개별 값을 가진 예를 많이 사용하면 모델이 다양한 설정에서 특성을 볼 수 있으며, 이를 통해 언제 라벨에 대한 좋은 예측자인지 판단할 수 있다. 예를 들어 house_type 특성에는 값이 victorian인 많은 예가 포함될 수 있다.
✔house_type: victorian반대로 특성 값이 한 번만 표시되거나 아주 드물게 나타나는 경우 모델이 이 특성을 기반으로 예측할 수 없다. 예를 들어 unique_house_id은 각 값이 한 번만 사용되기 때문에 모델이 좋지 않다. 모델이 모델을 통해 어떠한 것도 배울 수 없기 때문이다.
✘unique_house_id: 8SK982ZZ1242Z
명확하고 명확한 의미를 우선시
각 특성은 프로젝트의 모든 사람에게 명확하고 분명한 의미를 가져야 한다. 예를 들어 다음과 같은 좋은 특성에는 명확하게 이름이 지정되어 있고 값이 이름과 관련하여 의미가 있다.
✔house_age_years: 27반대로 다음 특성 값은 특성을 만든 엔지니어를 제외한 누구도 이해할 수 없다.
✘house_age: 851472000(나쁜 엔지니어링 선택이 아니라) 노이즈로 인해 데이터가 불분명한 경우가 있다. 예를 들어 다음 user_age_years는 적절한 값이 확인되지 않은 소스에서 발생했다.
✘user_age_years: 277
실제 데이터와 특이값을 조합하지 않기
좋은 부동 소수점 특성은 특수한 범위 밖에 있는 불연속성이나 특이값을 포함하지 않는다. 예를 들어 특성이 0과 1 사이의 부동 소수점 값을 보유한다고 가정해 보자. 따라서 다음과 같은 값은 괜찮다.
✔quality_rating: 0.82
quality_rating: 0.37
그러나 사용자가 quality_rating을 입력하지 않았다면 데이터 세트에서 다음과 같은 매직 값으로 데이터가 없음을 표현했을 수 있다.
✘quality_rating: -1
특이값을 이해할 수 있도록 표시하려면 quality_rating이 제공되었는지 여부를 나타내는 bool feature을 만든다. 이 bool feature에는 is_quality_rating_defined와 같은 이름을 지정한다. 원래 특성에서 다음과 같이 특이값을 바꾸는 것이 좋다.
- 유한한 값 집합을 갖는 변수 (개별 변수)의 경우 새로운 값을 집합에 추가하고 이 값을 사용하여 특성 값이 누락되었음을 표시한다.
- 연속 변수의 경우 특성 데이터의 평균 값을 사용하여 누락된 값이 모델에 영향을 미치지 않도록 한다.
업스트림 불안정성 고려
특성의 정의는 시간이 지남에 따라 변경되지 않아야 한다. 예를 들어 다음과 같은 값은 유용하다. 도시 이름은 잘 바뀌지 않기 때문이다. ("br/sao_paulo"와 같은 문자열은 one-hot 벡터로 변환해야 한다.)
✔city_id: "br/sao_paulo"
하지만 다른 모델에서 추론한 값을 수집하면 추가 비용이 발생한다. 값 '219"는 현재 상파울루를 나타낼 수 있지만, 다른 모델을 이후에 실행할 때 이 표현은 쉽게 변경될 수 있다.
✘inferred_city_cluster: "219"Cleaning Data
머신러닝 엔지니어는 질이 안좋은 데이터를 제거하는 것에 힘을 쏟아야한다. 잘못된 데이터 몇개가 모델 전체를 망칠수도 있기 때문이다.
Scaling feature values
Scaling은 부동 소수점 특성 값을 자연 범위 (예: 100~900)에서 표준 범위 (예: 0~1 또는 -1~+1)로 변환하는 것을 의미한다. 특성 세트가 단일 특성으로만 구성된 경우 조정 시 실질적인 이점이 거의 또는 전혀 없다. 그러나 특성 세트가 여러 특성으로 구성된 경우 특성 확장에는 다음과 같은 이점이 있다.
- 경사하강법이 더 빠르게 수렴하도록 돕는다.
- 모델의 한 숫자가 NaN이 되는 경우 (예: 학습 중에 값이 부동 소수점 정밀도 한도를 초과하는 경우) 그리고 수학 연산으로 인해 모델의 다른 모든 숫자도 결국 NaN이 되는 'NaN 트랩'을 방지할 수 있다.
- 모델이 각 특성에 적절한 가중치를 학습하는 데 도움이 된다. 특성 확장을 사용하지 않으면 모델이 더 광범위한 특성에 너무 많은 주의를 기울여야한다.
모든 부동 소수점 특성을 정확히 동일한 배율로 지정할 필요는 없다. 예를들어 특성 A가 -1에서 +1이 아니라 -3에서 +3으로 조정되더라도 다른 문제는 발생하지 않는다. 그러나 특성 B를 5000에서 100000으로 조정하면 모델의 결과가 좋지 않다.
Handling extreme outliers
극단점을 제거하는 과정이다. 다음 플롯은 캘리포니아 주택 데이터의 roomsPerPerson라는 특성을 나타냅니다. roomsPerPerson 값은 영역의 총 회의실 수를 그 지역의 인구로 나누어 계산했다. 플롯을 보면 캘리포니아의 대부분 지역에는 1인당 1~2개의 방이 있습니다. 하지만 x축을 살펴보면 이상한 지점이 있다.

이런 긴 꼬리를 갖는 데이터를 처리하기 위해 로그를 취해볼 수 있다.

그러나 여전히 꼬리를 남겨두기 때문에 그렇게 이상적이지 않다. 이때 채택되는 방법론은 바로 임의의 값(예:4.0)을 설정하여 해당값 이상의 값들을 전부 4.0으로 몰아버리는 것이다.

그래프를 보면 뭔가 웃긴 지점이 있는 것 같지만 이러한 언덕에도 불구하고 이런 방식으로 scaling된 feature set은 원본 데이터 보다 훨씬 유용하다.
Binning
다음 도표는 캘리포니아의 다양한 위도에서 주택의 상대적 분포를 보여준다. 클러스터링이다. 로스앤젤레스는 위도 34도 정도이고 샌프란시스코는 위도 38도 정도이다.
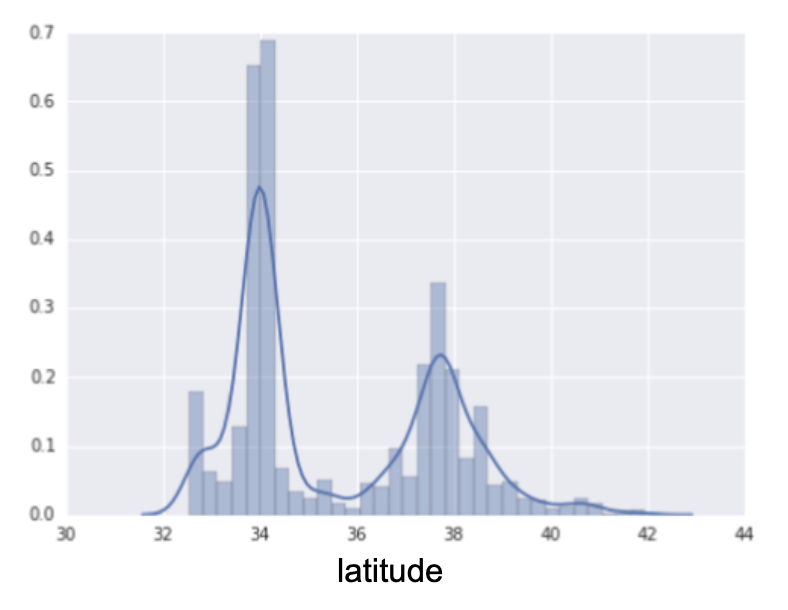
해당 도표를 다음과 같이 위도에 따라 분리를 한다.

부동 소수점 특성 하나를 사용하는 대신 이제 11개의 고유한 불리언 특성(LatitudeBin1, LatitudeBin2, ..., LatitudeBin11)이 있다. 11개의 개별 특성이 있으면 별로 중요하지 않으므로 단일 11 요소 벡터로 결합한다. 이렇게 하면 위도 37.4를 다음과 같이 표시할 수 있다.
[0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0]
비닝을 사용하면 모델이 각 위도에 대해 완전히 다른 가중치를 학습할 수 있다.
Scrubbing
지금까지는 학습 및 테스트에 사용되는 모든 데이터를 신뢰할 수 있다고 가정했다. 실무에서는 다음과 같은 이유로 데이터 세트의 여러 예가 불안정해진다.
- 누락된 값. 예를 들어 사용자가 주택의 연령 값을 입력하지 않았습니다.
- 중복 예시. 예를 들어 서버가 동일한 로그를 실수로 두 번 업로드했습니다.
- 잘못된 라벨입니다. 예를 들어 어떤 사람이 참나무 나무 사진을 메이플로 잘못 라벨을 지정했습니다.
- 잘못된 특성 값. 예를 들어 사용자가 숫자를 더 입력했거나 체온계가 햇빛에 노출되지 않은 경우입니다.
잘못된 사례가 감지되면 일반적으로 데이터 세트에서 삭제하여 잘못된 예를 해결한다. 생략된 값이나 중복 예시를 탐지하려면 간단한 프로그램을 작성하면 된다. 잘못된 특성 값 또는 라벨을 감지하는 것은 훨씬 더 어려울 수 있다.
부적합한 개별 사례를 감지할 뿐만 아니라 집계에서 잘못된 데이터도 감지해야 한다. 히스토그램은 집계에서 데이터를 시각화하는 데 유용한 메커니즘이다. 또한 다음과 같은 통계를 얻는 것이 도움이 될 수 있다.
- 최대 및 최소
- 평균 및 중앙값
- 표준 편차
불연속 특성의 가장 일반적인 값 목록을 생성하는 것이 좋다. 예를 들어 country:uk가 있는 예의 수가 예상과 일치하는지 확인한다. 데이터 세트에서 language:jp를 정말 자주 사용해야 하는지도 확인하면 좋다.
Know your data
다음 규칙을 따르면 좋다.
- 데이터가 어떻게 표시될지 생각해 본다.
- 데이터가 이러한 기대를 충족하는지 확인하고, 또는 충족하지 않는 이유를 설명할 수 있는지 확인하라.
- 학습 데이터가 대시보드와 같은 다른 소스와 일치하는지 다시 한번 확인한다.
모든 코드를 취급할 때는 주의를 기울여야 한다. 좋은 ML은 좋은 데이터에 의존하기 때문이다.
'Robotics & AI > Google' 카테고리의 다른 글
| Google ML crash course (9) (0) | 2024.02.19 |
|---|---|
| Google ML crash course (7) (1) | 2023.03.07 |
| Google ML crash course (6) (0) | 2023.02.27 |
| Google ML crash course (5) (1) | 2023.02.25 |
| Google ML crash course (4) (0) | 2022.12.26 |



