배치 정규화
이전에는 가중치의 초깃값을 적절히 설정하면 각 층의 활성화 값 분포가 적당히 퍼지면서 원활하게 학습이 진행됨을 확인했다. 이번에는 각층이 활성화를 적당히 퍼뜨리도록 강제하는 방법을 이용해보려한다. 이런 아이디어에서 시작된 방법을 배치 정규화(Batch Normalization)이라한다.
배치 정규화 알고리즘은 2015년 제안된 방법으로 나온지 얼마 안 된 기법임에도 현재 굉장히 많이 사용된다. 배치 정규화는 다음과 같은 장점이 존재한다.
1. 학습 속도 개선
2. 초깃값 선택에 크게 의존하지 않음
3. 오버피팅을 억제

위와 같이 Batch Normalization을 이용한다.
배치 정규화는 이름 그대로 학습 시 미니배치를 단위로 정규화한다. 정확히는 데이터 분포의 평균이 0, 분산이 1이 되도록 정규화한다. 식은 아래와 같다.
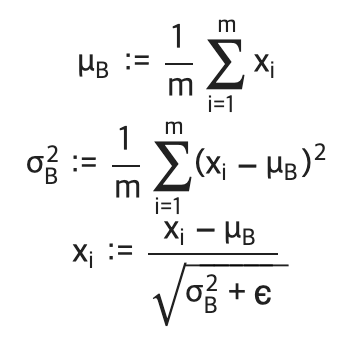
미니배치 B={x1, x2, ..., xm}라는 m개의 입력 데이터의 집합에 대해 평균과 분산을 구한다. 그 후에 입력 데이터를 평균이 0, 분산이 1이 되도록 정규화 한다. 이때 epsilon은 10e-7과 같이 굉장히 작은 값으로 0으로 나눠지는 사태를 방지하는 역할이다. 각 배치 정규화 계층마다 이 정규화된 데이터에 아래와 같은 고유한 scale과 shift 변환을 수행한다.

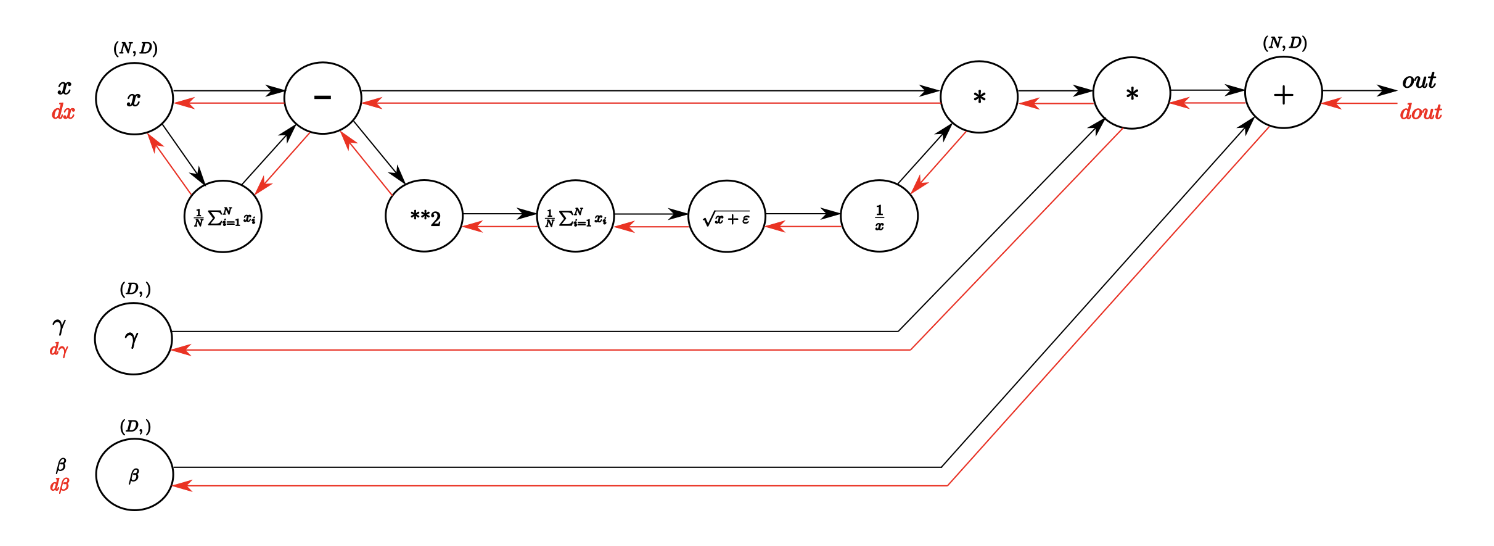
계산 그래프는 아래와 같이 그려진다.
배치 정규화 효과를 보기 위해 MNIST 데이터 셋을 사용하여 배치 정규화 계층을 사용할 때와 사용하지 않을 때 학습 진도를 비교해보자. 가중치 초기값의 표준편차를 다양하게 바꿔가며 학습 경과를 살펴보았다.
import numpy as np
import matplotlib.pyplot as plt
from dataset.mnist import load_mnist
from common.multi_layer_net_extend import MultiLayerNetExtend
from common.optimizer import SGD, Adam
(x_train, t_train), (x_test, t_test) = load_mnist(normalize=True)
# 학습 데이터를 줄임
x_train = x_train[:1000]
t_train = t_train[:1000]
max_epochs = 20
train_size = x_train.shape[0]
batch_size = 100
learning_rate = 0.01
def __train(weight_init_std):
bn_network = MultiLayerNetExtend(input_size=784, hidden_size_list=[100, 100, 100, 100, 100], output_size=10,
weight_init_std=weight_init_std, use_batchnorm=True)
network = MultiLayerNetExtend(input_size=784, hidden_size_list=[100, 100, 100, 100, 100], output_size=10,
weight_init_std=weight_init_std)
optimizer = SGD(lr=learning_rate)
train_acc_list = []
bn_train_acc_list = []
iter_per_epoch = max(train_size / batch_size, 1)
epoch_cnt = 0
for i in range(1000000000):
batch_mask = np.random.choice(train_size, batch_size)
x_batch = x_train[batch_mask]
t_batch = t_train[batch_mask]
for _network in (bn_network, network):
grads = _network.gradient(x_batch, t_batch)
optimizer.update(_network.params, grads)
if i % iter_per_epoch == 0:
train_acc = network.accuracy(x_train, t_train)
bn_train_acc = bn_network.accuracy(x_train, t_train)
train_acc_list.append(train_acc)
bn_train_acc_list.append(bn_train_acc)
#print("epoch:" + str(epoch_cnt) + " | " + str(train_acc) + " - " + str(bn_train_acc))
epoch_cnt += 1
if epoch_cnt >= max_epochs:
break
return train_acc_list, bn_train_acc_list
# 그래프 그리기==========
weight_scale_list = np.logspace(0, -4, num=16)
x = np.arange(max_epochs)
for i, w in enumerate(weight_scale_list):
#print( "============== " + str(i+1) + "/16" + " ==============")
train_acc_list, bn_train_acc_list = __train(w)
plt.subplot(4,4,i+1)
plt.title("W:" + str(w))
if i == 15:
plt.plot(x, bn_train_acc_list, label='Batch Normalization', markevery=2)
plt.plot(x, train_acc_list, linestyle = "--", label='Normal(without BatchNorm)', markevery=2)
else:
plt.plot(x, bn_train_acc_list, markevery=2)
plt.plot(x, train_acc_list, linestyle="--", markevery=2)
plt.ylim(0, 1.0)
if i % 4:
plt.yticks([])
else:
plt.ylabel("accuracy")
if i < 12:
plt.xticks([])
else:
plt.xlabel("epochs")
plt.legend(loc='lower right')
plt.show()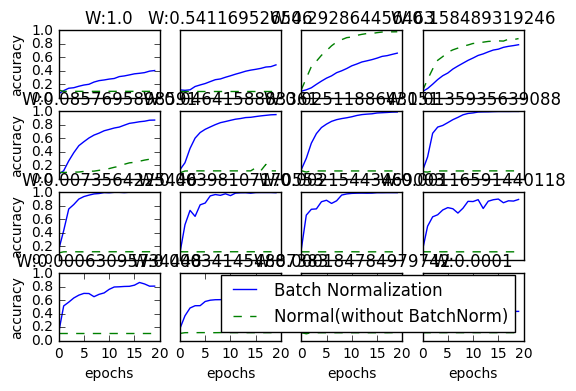
Batch Normalization이 효과를 보이는 것을 쉽게 확인할 수 있다.
'Drawing (AI) > DeepLearning' 카테고리의 다른 글
| 딥러닝 직접 구현하기 - (Training process) (1) | 2024.01.15 |
|---|---|
| Udemy - 딥러닝의 모든 것(AutoEncoders) - (2) (1) | 2024.01.11 |
| Udemy - 딥러닝의 모든 것(AutoEncoders) - (1) (1) | 2024.01.10 |
| 딥러닝 직접 구현하기 - (가중치 초기값) (0) | 2024.01.10 |
| 딥러닝 직접 구현하기 - (Optimizer) (1) | 2024.01.08 |



