오차역전파법
오차역전파법(Backpropagation)은 신경망을 훈련시키기 위한 핵심적인 알고리즘 중 하나이다. 이 방법은 신경망에서 발생하는 오차를 각 뉴런의 가중치에 역으로 전파함으로써 가중치를 조정하는 과정을 포함한다. 오차역전파법은 주로 다음의 단계들로 구성된다.
전방향 전파(Forward Propagation): 입력 데이터가 신경망을 통해 앞으로 전파되며, 각 층의 뉴런은 활성화 함수를 통해 출력값을 생성한다. 이 과정은 입력층에서 시작해 출력층에서 끝난다.
손실 함수 계산: 신경망의 출력과 실제 목표값 사이의 차이를 측정하는 손실 함수(loss function)를 계산한다. 이 손실은 신경망이 얼마나 잘못된 예측을 하고 있는지를 나타내는 지표이다.
역방향 전파(Backward Propagation): 손실 함수의 그래디언트(변화율)를 계산하고, 이를 신경망을 거슬러 올라가며 전파한다. 이 과정에서 각 뉴런의 가중치에 대한 오차의 기여도가 계산된다.
가중치 업데이트: 계산된 그래디언트(미분값)를 사용하여 신경망의 가중치를 조정한다. 이때 학습률(learning rate)이라는 매개변수가 사용되며, 이는 가중치 조정의 크기를 결정한다.
반복: 이러한 과정을 여러 데이터에 대해 반복하며 신경망의 가중치를 점차 최적화한다.
이 알고리즘의 핵심은 신경망이 잘못된 예측을 할 때마다, 오차를 줄이기 위해 가중치를 조정한다는 점이다. 이를 통해 신경망은 데이터에서 패턴을 학습하고, 시간이 지남에 따라 더 정확한 예측을 할 수 있게 된다. 오차역전파법은 딥러닝 모델의 효율적인 훈련을 위해 필수적인 방법이다.
곱셈 계층
모든 계층은 forward()와 backward()를 포함하는데 각각 순전파와 역전파를 처리한다.
class MulLayer:
def __init__(self):
self.x = None
self.y = None
def forward(self, x, y):
self.x = x
self.y = y
out = x * y
return out
def backward(self, dout):
dx = dout * self.y # x와 y를 바꾼다.
dy = dout * self.x
return dx, dy__init__()에서는 인스턴스 변수 x,y를 초기화한다. forward()에서는 x와 y를 인수로 받고 두 값을 곱해서 반환하고 backward()에서는 상류에서 넘어온 미분(dout)에 순전파 때의 값을 서로 바꿔 곱한 후 하류로 흘린다.
100원짜리 사과를 2개 구입하고 10% 소비세가 붙는 과정을 표현해보자.
apple = 100
apple_num = 2
tax = 1.1
#계층들
mul_apple_layer = MulLayer()
mul_tax_layer = MulLayer()
#순전파
apple_price = mul_apple_layer.forward(apple, apple_num)
price = mul_tax_layer.forward(apple_price, tax)
print(price) #220덧셈 계층
class AddLayer:
def __init__(self):
pass
def forward(self, x, y):
out = x + y
return out
def backward(self, dout):
dx = dout * 1
dy = dout * 1
return dx, dy덧셈 계층에서는 초기화가 필요 없어 __init__()에서 pass라는 아무것도 하지 말라는 명령어를 이용한다.
이번엔 덧셈 계층과 곱셈 계층을 함께 이용하여 사과 2개와 귤 3개를 사는 과정을 구현해보자.
apple = 100
apple_num = 2
orange = 150
orange_num = 3
tax = 1.1
# 계층들
mul_apple_layer = MulLayer()
mul_orange_layer = MulLayer()
add_apple_orange_layer = AddLayer()
mul_tax_layer = MulLayer()
# 순전파
apple_price = mul_apple_layer.forward(apple, apple_num) # (1)
orange_price = mul_orange_layer.forward(orange, orange_num) # (2)
all_price = add_apple_orange_layer.forward(apple_price, orange_price) # (3)
price = mul_tax_layer.forward(all_price, tax) # (4)
# 역전파
dprice = 1
dall_price, dtax = mul_tax_layer.backward(dprice) # (4)
dapple_price, dorange_price = add_apple_orange_layer.backward(dall_price) # (3)
dorange, dorange_num = mul_orange_layer.backward(dorange_price) # (2)
dapple, dapple_num = mul_apple_layer.backward(dapple_price) # (1)
print("price:", int(price))
print("dApple:", dapple)
print("dApple_num:", int(dapple_num))
print("dOrange:", dorange)
print("dOrange_num:", int(dorange_num))
print("dTax:", dtax)
price: 715
dApple: 2.2
dApple_num: 110
dOrange: 3.3000000000000003
dOrange_num: 165
dTax: 650ReLU 계층
활성화함수로 사용되는 ReLU의 수식은 다음과 같다.
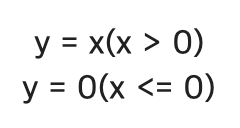
그리고 이를 x에 대한 y의 미분은 아래와 같이 구한다.
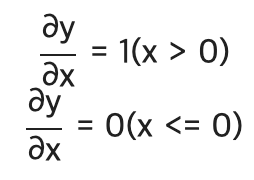
이를 기반으로 ReLU계층을 구현하면 아래와 같다.
class Relu:
def __init__(self):
self.mask = None
def forward(self, x):
self.mask = (x <= 0)
out = x.copy()
out[self.mask] = 0
return out
def backward(self, dout):
dout[self.mask] = 0
dx = dout
return dxReLU 클래스는 mask라는 인스턴스 변수를 가진다. mask는 True/False로 구성된 넘파이 배열로 순전파의 입력인 x의 원소 값이 0 이하인 인덱스는 True이고 그 외는 False로 유지한다.
import numpy as np
x = np.array([[1.0, 0.5], [-2.0, 3.0]])
print(x)
[[ 1. 0.5]
[-2. 3. ]]
mask = (x <= 0)
print(mask)
[[False False]
[ True False]]
out = x.copy()
out[mask] = 0
out
array([[ 1. , 0.5],
[ 0. , 3. ]])순전파 때의 입력값이 0이하면 역전파 때의 값이 0이되는 것을 볼 수 있다. 역전파 때는 순전파 때 만들어둔 mask를 참고하여 mask의 원소가 True인 곳에는 상류에서 전파된 dout을 0으로 설정한다.
Sigmoid 계층
다음은 시그모이드 함수이다.
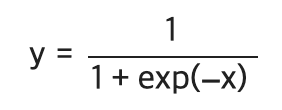
1. y=1/x를 미분하면 아래와 같다.
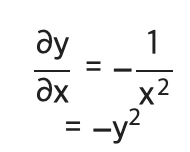
2. 상류의 값을 여과없이 하류로 보냄
3. y=exp(x) 연산을 수행
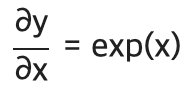
4. 곱하기 노드는 순전파 때의 값을 '서로 바꿔' 곱한다.
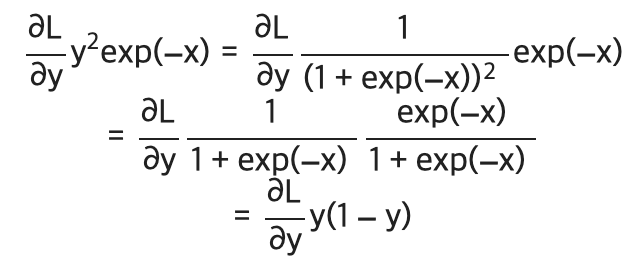
이를 구현하면 아래와 같다.
class Sigmoid:
def __init__(self):
self.out = None
def forward(self, x):
out = 1 / (1 + np.exp(-x))
self.out = out
return out
def backward(self, dout):
dx = dout * (1.0 - self.out) * self.out
return dx순전파의 출력을 인스턴스 변수 out에 보관했다가 역전파 계산 때 그 값을 사용한다.
Affine 계층
신경망의 순전파에서는 가중치 신호의 총합을 계산하기 위해 행렬의 내적(np.dot())을 사용한다.
X = np.random.rand(2) # 입력
W = np.random.rand(2,3) # 가중치
B = np.random.rand(3) # 편향
print(X.shape) # (2,)
print(W.shape) # (2, 3)
print(B.shape) # (3,)
Y = np.dot(X, W) + B
(2,)
(2, 3)
(3,)행렬을 사용한 역전파 전개식은 아래와 같다.
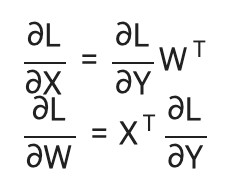
역전파에서의 변수 형상은 해당 변수명 옆에 표기한다.
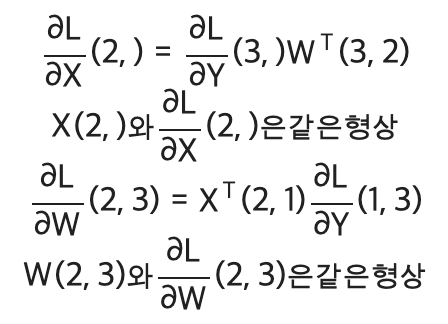
배치용 Affine 계층의 계산 그래프는 아래와 같다.

X_dot_W = np.array([[0, 0, 0], [10, 10, 10]])
B = np.array([1, 2, 3])
X_dot_W
array([[ 0, 0, 0],
[10, 10, 10]])
X_dot_W + B
array([[ 1, 2, 3],
[11, 12, 13]])순전파의 편향 덧셈은 각각의 데이터(1번째 데이터, 2번째 데이터)에 더해진다. 역전파 때는 각 데이터의 역전파 값이 편향의 원소에 모여야 한다.
dY = np.array([[1, 2, 3], [4, 5, 6]])
dY
array([[1, 2, 3],
[4, 5, 6]])
dB = np.sum(dY, axis=0)
dB
array([5, 7, 9])Affine 계층을 구현하면 아래와 같다.
class Affine:
def __init__(self, W, b):
self.W = W
self.b = b
self.x = None
self.dW = None
self.db = None
def forward(self, x):
self.x = x
out = np.dot(x, self.W) + self.b
return out
def backward(self, dout):
dx = np.dot(dout, self.W.T)
self.dW = np.dot(self.x.T, dout)
self.db = np.sum(dout, axis=0)
return dxSoftmax-with-Loss 계층
정답 레이블이 (0,1,0)일 때 Softmax계층이 (0.3, 0.2, 0.5)를 출력하면 정답의 인덱스는 1인데 출력에서 이때의 확률은 겨우 0.2이다. 이 경우 Softmax 계층의 역전파는 (0.3, -0.8, 0.5)라는 커다란 오차를 전파한다. 만약 Softmax 계층이 (0.01, 0.99, 0)을 출력한 경우 역전파가 보내는 오차는 비교적 작은 (0.01, -0.01, 0)이다. 이를 구현하면 아래와 같다.
class SoftmaxWithLoss:
def __init__(self):
self.loss = None # 손실
self.y = None # softmax의 출력
self.t = None # 정답 레이블(원-핫 벡터)
def forward(self, x, t):
self.t = t
self.y = softmax(x)
self.loss = cross_entropy_error(self.y, self.t)
return self.loss
def backward(self, dout=1):
batch_size = self.t.shape[0]
dx = (self.y - self.t) / batch_size
return dx오차역전파법 구현
import numpy as np
#from common.layers import *
#from common.gradient import numerical_gradient
from collections import OrderedDict
# https://github.com/WegraLee/deep-learning-from-scratch/blob/master/common/functions.py
def softmax(x):
if x.ndim == 2:
x = x.T
x = x - np.max(x, axis=0)
y = np.exp(x) / np.sum(np.exp(x), axis=0)
return y.T
x = x - np.max(x) # 오버플로 대책
return np.exp(x) / np.sum(np.exp(x))
# https://github.com/WegraLee/deep-learning-from-scratch/blob/master/common/gradient.py 참고
def numerical_gradient(f, x):
h = 1e-4 # 0.0001
grad = np.zeros_like(x)
it = np.nditer(x, flags=['multi_index'], op_flags=['readwrite'])
while not it.finished:
idx = it.multi_index
tmp_val = x[idx]
x[idx] = float(tmp_val) + h
fxh1 = f(x) # f(x+h)
x[idx] = tmp_val - h
fxh2 = f(x) # f(x-h)
grad[idx] = (fxh1 - fxh2) / (2*h)
x[idx] = tmp_val # 값 복원
it.iternext()
return grad
class TwoLayerNet:
def __init__(self, input_size, hidden_size, output_size, weight_init_std = 0.01):
# 가중치 초기화
self.params = {}
self.params['W1'] = weight_init_std * np.random.randn(input_size, hidden_size)
self.params['b1'] = np.zeros(hidden_size)
self.params['W2'] = weight_init_std * np.random.randn(hidden_size, output_size)
self.params['b2'] = np.zeros(output_size)
# 계층 생성
self.layers = OrderedDict() ###
self.layers['Affine1'] = Affine(self.params['W1'], self.params['b1']) ###
self.layers['Relu1'] = Relu() ###
self.layers['Affine2'] = Affine(self.params['W2'], self.params['b2']) ###
self.lastLayer = SoftmaxWithLoss() ###
def predict(self, x):
for layer in self.layers.values(): ###
x = layer.forward(x) ###
return x
# x : 입력 데이터, t : 정답 레이블
def loss(self, x, t):
y = self.predict(x)
return self.lastLayer.forward(y, t)
def accuracy(self, x, t):
y = self.predict(x)
y = np.argmax(y, axis=1)
if t.ndim != 1 : t = np.argmax(t, axis=1)
accuracy = np.sum(y == t) / float(x.shape[0])
return accuracy
# x : 입력 데이터, t : 정답 레이블
def numerical_gradient(self, x, t):
loss_W = lambda W: self.loss(x, t)
grads = {}
grads['W1'] = numerical_gradient(loss_W, self.params['W1'])
grads['b1'] = numerical_gradient(loss_W, self.params['b1'])
grads['W2'] = numerical_gradient(loss_W, self.params['W2'])
grads['b2'] = numerical_gradient(loss_W, self.params['b2'])
return grads
def gradient(self, x, t):
# forward
self.loss(x, t) ###
# backward
dout = 1 ###
dout = self.lastLayer.backward(dout) ###
layers = list(self.layers.values()) ###
layers.reverse() ###
for layer in layers: ###
dout = layer.backward(dout) ###
# 결과 저장
grads = {}
grads['W1'], grads['b1'] = self.layers['Affine1'].dW, self.layers['Affine1'].db
grads['W2'], grads['b2'] = self.layers['Affine2'].dW, self.layers['Affine2'].db
return grads신경망의 계층을 OrderedDict에 보관한다. OrderedDict은 순서가 있는 딕셔너리로 딕셔너리에 추가한 순서를 기억하는 것이다. 그렇기 때문에 순전파 때는 추가한 순서대로 각 계층의 forward() 메서드를 호출하기만 하면되고 역전파 때는 계층을 반대 순서로 호출하기만 하면된다.
수치미분은 구현하기는 쉬우나 오차역전파법에 비해 느리다. 따라서 오차역전파법을 이용할 것인데 수치미분은 오차역전파법이 제대로 구현되었는지 확인할 때 쓰인다. 이 기울기 확인 과정을 구현하면 아래와 같다.
import sys, os
sys.path.append(os.pardir)
import numpy as np
from dataset.mnist import load_mnist
# 데이터 읽기
(x_train, t_train), (x_test, t_test) = load_mnist(normalize=True, one_hot_label=True)
network = TwoLayerNet(input_size=784, hidden_size=50, output_size=10)
x_batch = x_train[:3]
t_batch = t_train[:3]
grad_numerical = network.numerical_gradient(x_batch, t_batch)
grad_backprop = network.gradient(x_batch, t_batch)
# 각 가중치의 절대 오차의 평균을 구한다.
for key in grad_numerical.keys():
diff = np.average( np.abs(grad_backprop[key] - grad_numerical[key]) )
print(key + ":" + str(diff))
b2:1.20126118774e-10
W1:2.80100167994e-13
W2:9.12804904606e-13
b1:7.24036213471e-13이제 오차역전파법을 사용한 학습을 구현하면 아래와 같다.
import sys, os
sys.path.append(os.pardir)
import numpy as np
from dataset.mnist import load_mnist
from two_layer_net import TwoLayerNet
# 데이터 읽기
(x_train, t_train), (x_test, t_test) = load_mnist(normalize=True, one_hot_label=True)
network = TwoLayerNet(input_size=784, hidden_size=50, output_size=10)
iters_num = 10000
train_size = x_train.shape[0]
batch_size = 100
learning_rate = 0.1
train_loss_list = []
train_acc_list = []
test_acc_list = []
iter_per_epoch = max(train_size / batch_size, 1)
for i in range(iters_num):
batch_mask = np.random.choice(train_size, batch_size)
x_batch = x_train[batch_mask]
t_batch = t_train[batch_mask]
# 기울기 계산
#grad = network.numerical_gradient(x_batch, t_batch) # 수치 미분 방식
grad = network.gradient(x_batch, t_batch) # 오차역전파법 방식(훨씬 빠르다)
# 갱신
for key in ('W1', 'b1', 'W2', 'b2'):
network.params[key] -= learning_rate * grad[key]
loss = network.loss(x_batch, t_batch)
train_loss_list.append(loss)
if i % iter_per_epoch == 0:
train_acc = network.accuracy(x_train, t_train)
test_acc = network.accuracy(x_test, t_test)
train_acc_list.append(train_acc)
test_acc_list.append(test_acc)
print(train_acc, test_acc)
0.1359 0.1349
0.898666666667 0.9015
0.921233333333 0.9229
0.935483333333 0.9355
0.946366666667 0.9449
0.95215 0.9502
0.956916666667 0.9527
0.96005 0.9557
0.9626 0.9573
0.966833333333 0.9597
0.968366666667 0.9616
0.9704 0.9622
0.971483333333 0.963
0.974283333333 0.9663
0.976 0.9669
0.977116666667 0.967
0.978 0.9677각각의 최소단위 메서드를 구현해두고 모듈화해두니 신경망의 계층으 자유롭게 조합하여 원하는 신경망을 쉽게 만들고 학습시킬 수 있었다.
'Drawing (AI) > DeepLearning' 카테고리의 다른 글
| 딥러닝 직접 구현하기 - (Optimizer) (1) | 2024.01.08 |
|---|---|
| Udemy - 딥러닝의 모든 것(볼츠만 머신 구축하기) (0) | 2024.01.08 |
| Udemy - 딥러닝의 모든 것(볼츠만 머신) - (2) (0) | 2024.01.07 |
| Udemy - 딥러닝의 모든 것(볼츠만 머신) - (1) (0) | 2024.01.05 |
| Udemy - 딥러닝의 모든 것(SOM)-(2) (1) | 2024.01.03 |



