728x90
영화 추천 시스템
볼츠만 머신을 이용하여 Movie Lens 데이터를 이용하여 영화를 추천하는 모델을 구축해보도록 하자.
Movie Lens dataset은 주로 100K 데이터가 학습, 개발으로 쓰이고 20M데이터가 연구 벤치마크로 쓰인다고 한다. 100K데이터를 주로 다뤄보려한다.
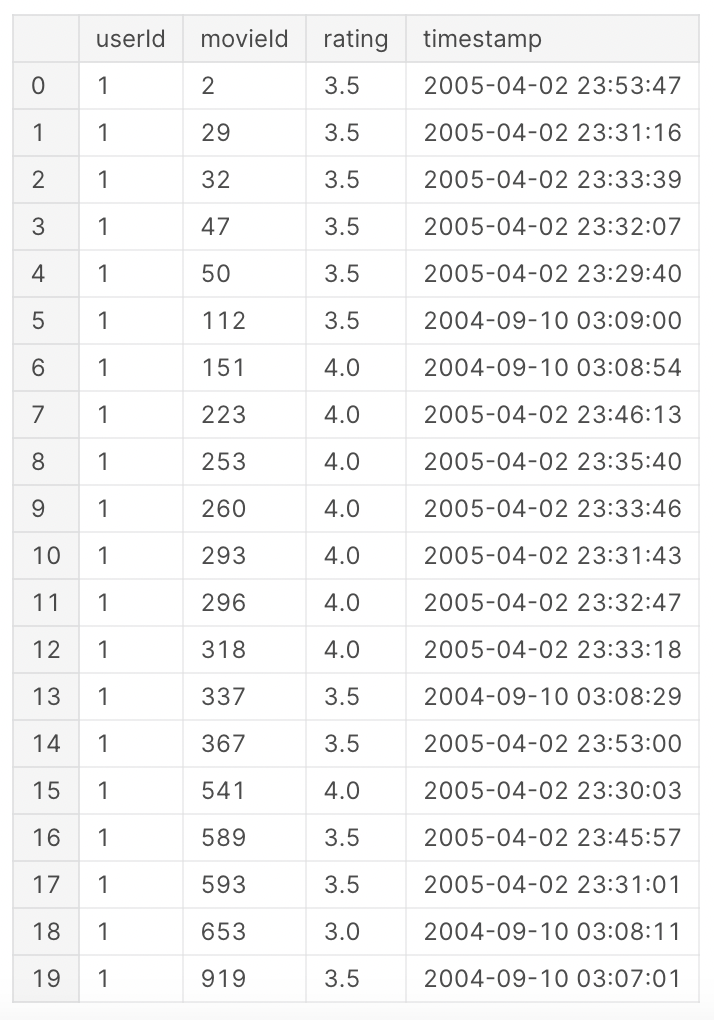
위와 같이 유저에 따른 영화에 매긴 평점이 데이터로 존재한다.
Movie Lens EDA 자료가 Kaggle에 있어 참고하보고자 한다. 처음 딥러닝 공부를 할때는 데이터 자체보다는 기술에 관심이 많았으나 다양한 과제와 대회에 참여하다보니 데이터의 특징을 파악하고 정제하고 다루는 것이 매우 중요함을 알게되어 데이터를 더 살펴보게 되는 습관이 생겼다.
참고: https://www.kaggle.com/code/salmaneunus/movie-lens-eda-visualization-cleaning
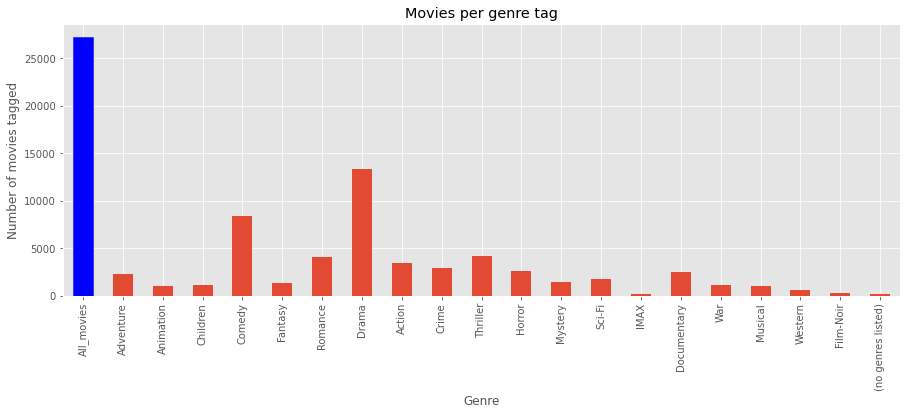
영화의 장르에 따른 비율을 살펴보니 Drama, Comedy의 비중이 높았다.
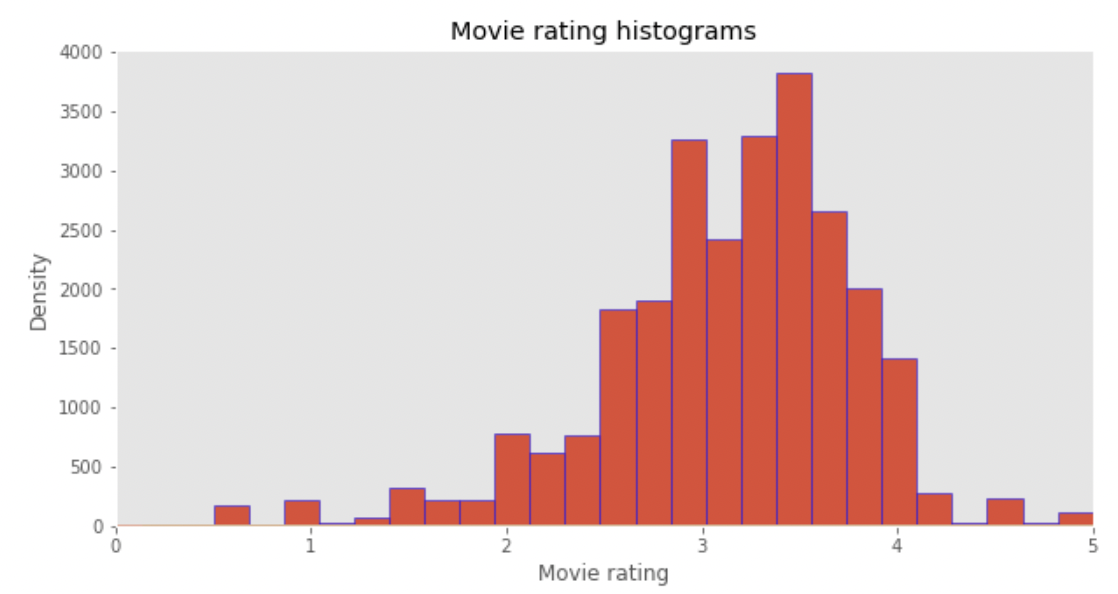
평점은 3점 중반이 가장 많았음을 알 수 있다.
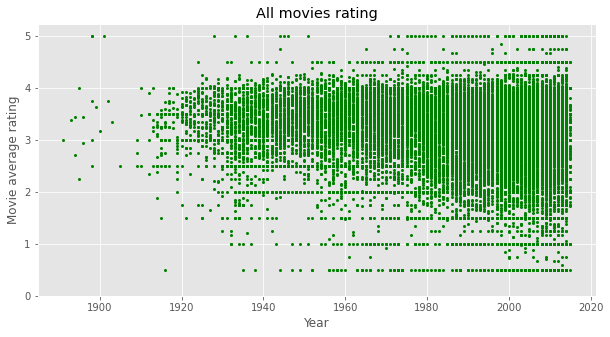
연도별 평가를 살펴보니 과거미화(?)가 되는 경향이 있는건지 좋은 영화만이 지금까지 남아서 평가를 받는건지 과거로 갈수록 평점이 낮은 영화를 찾기 어려웠다.
모델 구현
#Boltzmann Machine
##Downloading the dataset
###ML-100K
"""
!wget "http://files.grouplens.org/datasets/movielens/ml-100k.zip"
!unzip ml-100k.zip
!ls
"""###ML-1M"""
!wget "http://files.grouplens.org/datasets/movielens/ml-1m.zip"
!unzip ml-1m.zip
!ls
"""##Importing the libraries"""
import numpy as np
import pandas as pd
import torch
import torch.nn as nn
import torch.nn.parallel
import torch.optim as optim
import torch.utils.data
from torch.autograd import Variable
"""## Importing the dataset"""
# We won't be using this dataset.
movies = pd.read_csv('ml-1m/movies.dat', sep = '::', header = None, engine = 'python', encoding = 'latin-1')
users = pd.read_csv('ml-1m/users.dat', sep = '::', header = None, engine = 'python', encoding = 'latin-1')
ratings = pd.read_csv('ml-1m/ratings.dat', sep = '::', header = None, engine = 'python', encoding = 'latin-1')
"""## Preparing the training set and the test set"""
training_set = pd.read_csv('ml-100k/u1.base', delimiter = '\t')
training_set = np.array(training_set, dtype = 'int')
test_set = pd.read_csv('ml-100k/u1.test', delimiter = '\t')
test_set = np.array(test_set, dtype = 'int')
"""## Getting the number of users and movies"""
nb_users = int(max(max(training_set[:, 0], ), max(test_set[:, 0])))
nb_movies = int(max(max(training_set[:, 1], ), max(test_set[:, 1])))
"""## Converting the data into an array with users in lines and movies in columns"""
def convert(data):
new_data = []
for id_users in range(1, nb_users + 1):
id_movies = data[:, 1] [data[:, 0] == id_users]
id_ratings = data[:, 2] [data[:, 0] == id_users]
ratings = np.zeros(nb_movies)
ratings[id_movies - 1] = id_ratings
new_data.append(list(ratings))
return new_data
training_set = convert(training_set)
test_set = convert(test_set)
"""## Converting the data into Torch tensors"""
training_set = torch.FloatTensor(training_set)
test_set = torch.FloatTensor(test_set)
"""## Converting the ratings into binary ratings 1 (Liked) or 0 (Not Liked)"""
training_set[training_set == 0] = -1
training_set[training_set == 1] = 0
training_set[training_set == 2] = 0
training_set[training_set >= 3] = 1
test_set[test_set == 0] = -1
test_set[test_set == 1] = 0
test_set[test_set == 2] = 0
test_set[test_set >= 3] = 1
"""## Creating the architecture of the Neural Network"""
class RBM():
def __init__(self, nv, nh):
self.W = torch.randn(nh, nv)
self.a = torch.randn(1, nh)
self.b = torch.randn(1, nv)
def sample_h(self, x):
wx = torch.mm(x, self.W.t())
activation = wx + self.a.expand_as(wx)
p_h_given_v = torch.sigmoid(activation)
return p_h_given_v, torch.bernoulli(p_h_given_v)
def sample_v(self, y):
wy = torch.mm(y, self.W)
activation = wy + self.b.expand_as(wy)
p_v_given_h = torch.sigmoid(activation)
return p_v_given_h, torch.bernoulli(p_v_given_h)
def train(self, v0, vk, ph0, phk):
self.W += (torch.mm(v0.t(), ph0) - torch.mm(vk.t(), phk)).t()
self.b += torch.sum((v0 - vk), 0)
self.a += torch.sum((ph0 - phk), 0)
nv = len(training_set[0])
nh = 100
batch_size = 100
rbm = RBM(nv, nh)
"""## Training the RBM"""
nb_epoch = 10
for epoch in range(1, nb_epoch + 1):
train_loss = 0
s = 0.
for id_user in range(0, nb_users - batch_size, batch_size):
vk = training_set[id_user : id_user + batch_size]
v0 = training_set[id_user : id_user + batch_size]
ph0,_ = rbm.sample_h(v0)
for k in range(10):
_,hk = rbm.sample_h(vk)
_,vk = rbm.sample_v(hk)
vk[v0<0] = v0[v0<0]
phk,_ = rbm.sample_h(vk)
rbm.train(v0, vk, ph0, phk)
train_loss += torch.mean(torch.abs(v0[v0 >= 0] - vk[v0 >= 0]))
s += 1.
print('epoch: '+str(epoch)+' loss: '+str(train_loss/s))
'''
epoch: 1 loss: tensor(0.3446)
epoch: 2 loss: tensor(0.2168)
epoch: 3 loss: tensor(0.2445)
epoch: 4 loss: tensor(0.2458)
epoch: 5 loss: tensor(0.2490)
epoch: 6 loss: tensor(0.2498)
epoch: 7 loss: tensor(0.2468)
epoch: 8 loss: tensor(0.2488)
epoch: 9 loss: tensor(0.2497)
epoch: 10 loss: tensor(0.2462)
'''
"""## Testing the RBM"""
test_loss = 0
s = 0.
for id_user in range(nb_users):
v = training_set[id_user:id_user+1]
vt = test_set[id_user:id_user+1]
if len(vt[vt>=0]) > 0:
_,h = rbm.sample_h(v)
_,v = rbm.sample_v(h)
test_loss += torch.mean(torch.abs(vt[vt>=0] - v[vt>=0]))
s += 1.
print('test loss: '+str(test_loss/s))
'''
test loss: tensor(0.2359)
'''RBM을 사용하여 사용자의 영화 선호도를 모델링하는 전형적인 예이다. 해당 코드는 사용자의 과거 평점 데이터를 기반으로 하여, 사용자가 어떤 영화를 좋아할지 예측하는 데 사용될 수 있다.
728x90
'Robotics & AI > DeepLearning' 카테고리의 다른 글
| 딥러닝 직접 구현하기 - (가중치 초기값) (0) | 2024.01.10 |
|---|---|
| 딥러닝 직접 구현하기 - (Optimizer) (1) | 2024.01.08 |
| 딥러닝 직접 구현하기 - (오차역전파법) (1) | 2024.01.07 |
| Udemy - 딥러닝의 모든 것(볼츠만 머신) - (2) (0) | 2024.01.07 |
| Udemy - 딥러닝의 모든 것(볼츠만 머신) - (1) (0) | 2024.01.05 |



