Intro
DDPM은 고품질 샘플을 생성할 수 있는 새로운 접근 방식으로 주목받는 생성 모델의 한획을 그은 논문이다. 순수한 노이즈에서 시작하여 점차적으로 구조를 추가하면서 신호를 점진적으로 제거하는 방식으로 작동한다. 이 과정은 일련의 노이즈 수준에 대한 학습된 분포에 의해 전개되기 때문에, 이 모델들은 샘플의 품질과 다양성에 영향을 받는다.
최근 VR기기와 XR시장이 커지면서 3D generative model도 굉장히 각광받는 시장일 것이라고 생각이 되어 이미지 생성형 모델의 시초가 되는 diffusion model에 대해서 공부해보고 싶었다.
Background Knowledge - VAE
VAE는 컴퓨터 비전 분야에 한 획을 그은 방법론이다. 특히 이미지 생성 분야에서는 그 임팩트가 엄청났다.

Diffusion을 이해하기 위한 수학적 개념이 담긴 초석같은 이론이다.
아래 글에서 VAE 논문에 대해 간단히 소개해두었다.
[논문 리뷰] Auto-Encoding Variational Bayes(VAE)
Intro 연속적인 또는 이산적인 독립변수 x를 N개 가지고 있는 Dataset X를 정의하고 이때 data는 관찰되지 않은 랜덤한 연속변수 z에 의해서 생성된다고 하자. 그렇다면 해당 process는 2단계로 이루어질
canvas4sh.tistory.com
Diffusion Model

Diffusion에서 중요한 개념은 바로 Stochastic Process이다. 이것은 time-dependent variables을 통해서 이루어진다는 것이다. Diffusion을 간략하게 살펴보면, Reverse, Forward process가 있다. Reverse process는 noise에서 이미지로 가는 것이고, Forward process는 이미지에서 noise로 가도록 하는 것 이다. 여기서 Reverse process를 training하는 것이 바로 Diffusion model인 것이다.
Forward process
DDPM의 forward process는 기본적인 diffusion model과 똑같이 data에 Gaussian noise를 더하는 형태로 정의된다. 이 때, 는 학습을 할 수도 있고, 어떤 함수로 정의할 수도 있지만 DDPM에서는 미리 정해진 상수로 정의한다. 그러므로 forward process에서는 별도의 학습이 필요하지 않다.

Reverse process
DDPM의 reverse process에서 우리는 다음 식에서의 와 를 학습해야 한다.

다음과 같은 loss function을 최소화하는 것을 목적으로 한다.

이 각각의 loss function을 DDPM에서 어떻게 최소화하는지를 알면, 우리가 어떻게 parameter를 학습해야할지도 알 수 있을 것이다. 이들 각각을 하나씩 살펴보자.
에서 우리는 와 를 각각 학습이 필요하지 않은 파라미터를 가지는 정규분포로 가정했기 때문에, 이를 최소화하기 위해서 우리가 학습해야하는 파라미터는 없다. 그러므로 학습하는 동안 이 loss는 무시가 가능하다.
−1
에서 우리는 이를 계산하기 위해서 첫 번째로 의 분포를 알아내고, 두 번째로 를 알아내기 위해 와 를 알아내야 한다. 이를 순서대로 하나씩 살펴보자.

p의 평균은 다음과 같이 정의한다.

를 얻어내면, 이를 활용해서 우리는 로부터 샘플링할 수 있다. 이 과정은 다음과 같은 알고리즘으로 표현할 수 있다.

또한 우리는 이렇게 얻어낸 파라미터들을 활용해 loss function을 다음과 같이 normal distribution 간의 KL divergence를 계산한 식으로 표현할 수 있다.

위의 loss function을 epsilon에 대한 식의 형태로 다시 한 번 표현할 수 있다. 이를 simplified objective function이라고 부르고, 이러한 loss function을 통해 training을 하면 학습이 좀 더 잘 된다는 것을 확인할 수 있다.
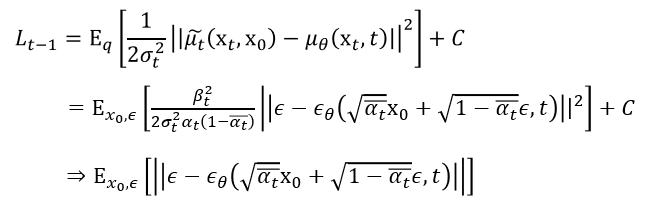
결론적으로 DDPM의 training 과정 알고리즘을 표현하면 아래와 같다.

마지막으로, loss function의 마지막 구성 요소인 L0 에 대해 알아보면 이는 그냥 간단한 두 normal 분포 사이의 KL divergence이기 때문에 다음과 같은 간단한 형태로 표현할 수 있다.
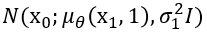
Experiments
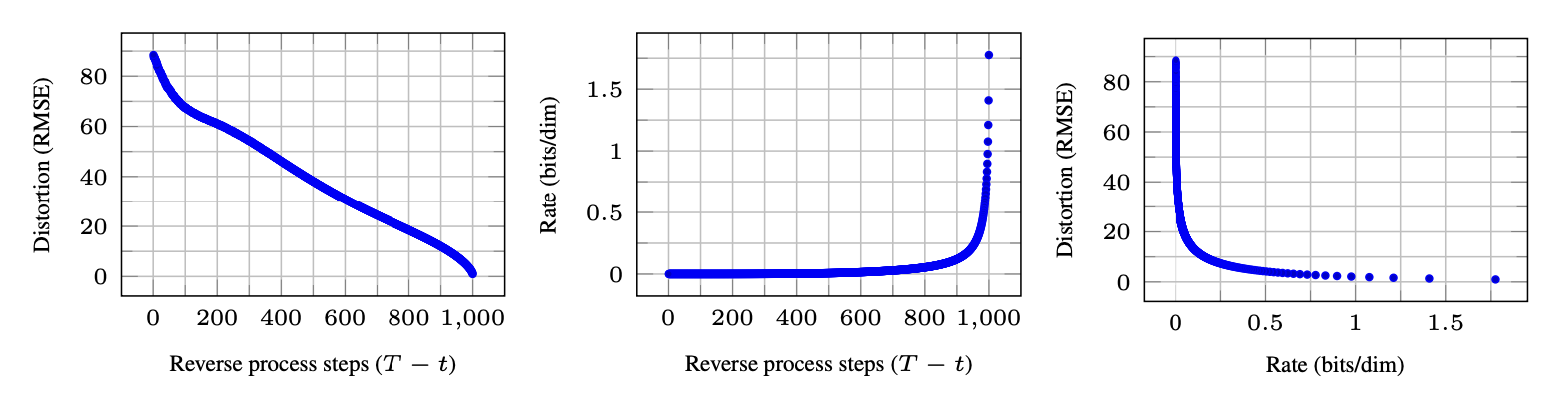
DDPM 논문의 핵심은 reverse process의 Lt−1 을 좋은 형태로 다시 정의한 것에 있다. 이렇게 forward process와 reward process를 정의하여 generative model을 구성하고, 이들로부터 사진 데이터를 만들어보면, 다음과 같이 좋은 퀄리티의 사진들을 만들어냄을 알 수 있다. 아래의 파라미터를 이용하여 결과를 보자.


CIFAR10 test set으로 진행한 결과 step에 따른 distortion, rate와 rate에 따란 distortion 결과이다.

진행 과정에 따라 완성된 이미지들이 생성되는 것을 볼 수 있다.

CelebA-HQ 데이터셋을 사용하여 특정 잠재 변수에 조건을 건 이미지 생성 과정이다.

500 timesteps of diffusion을 진행한 CelebA-HQ 256x256이미지의 interpolation들이다.
'Drawing (AI) > Paper review' 카테고리의 다른 글
| [논문 리뷰]Asymmetric Student-Teacher Networks for Industrial Anomaly Detection(1) (0) | 2024.03.31 |
|---|---|
| [논문리뷰] Deep Learning for Anomaly Detection: A Review (0) | 2024.03.28 |
| [논문 리뷰] Auto-Encoding Variational Bayes(VAE) (0) | 2024.03.09 |
| [논문 리뷰] NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis (0) | 2024.03.02 |
| BERT(3) (0) | 2023.08.20 |



