Intro
다른 Knowledge distillation 기반의 Anomaly Detection과 마찬가지로 Teacher-Student 구조로 Anomaly Detection를 수행한다. Student의 undesired Generalization 문제를 해결하기 위해 Teacher-Student 간 비대칭 구조 제안한다. OOD input에 대해 민감하게 반응할 수 있도록 Teacher 모델로 Normalizing flow를 사용한다. 2D RGB 데이터 뿐만 아니라 3D data까지 Anomaly Detection을 확장할 수 있다.

Background
Image Anomaly Detection은 Input 이미지 내 이상치 포함 여부를 판단하는 Task로 크게 Image-level, Pixel-level로 나눌 수 있다. 다른 anomaly detection 방법들과 비슷하게 비정상 데이터를 확보하기 어려운 상황을 가정하여 정상 데이터로만 학습을 하며, 정상 데이터의 특징을 잘 학습하는 것이 중요하다. 학습한 Feature(정상 Feature)와는 다른 Feature를 가질 경우 비정상으로 판별한다.
Image-level anomaly detection은 image 전체를 기준으로 Normal - Anomaly를 결정 지어서 이미지 내 Anomaly region이 있으면 해당 이미지는 Anomaly라 판별한다.

Pixel-level anomaly detection은 Pixel 별로 Normal- Anomaly를 결정 지는 방법으로 Anomaly Localization이라고도 불린다. 이미지 내 모든 픽셀에 대하여 Normal-Anomaly을 판별한다.

Anomaly Detection의 대표적인 방법론
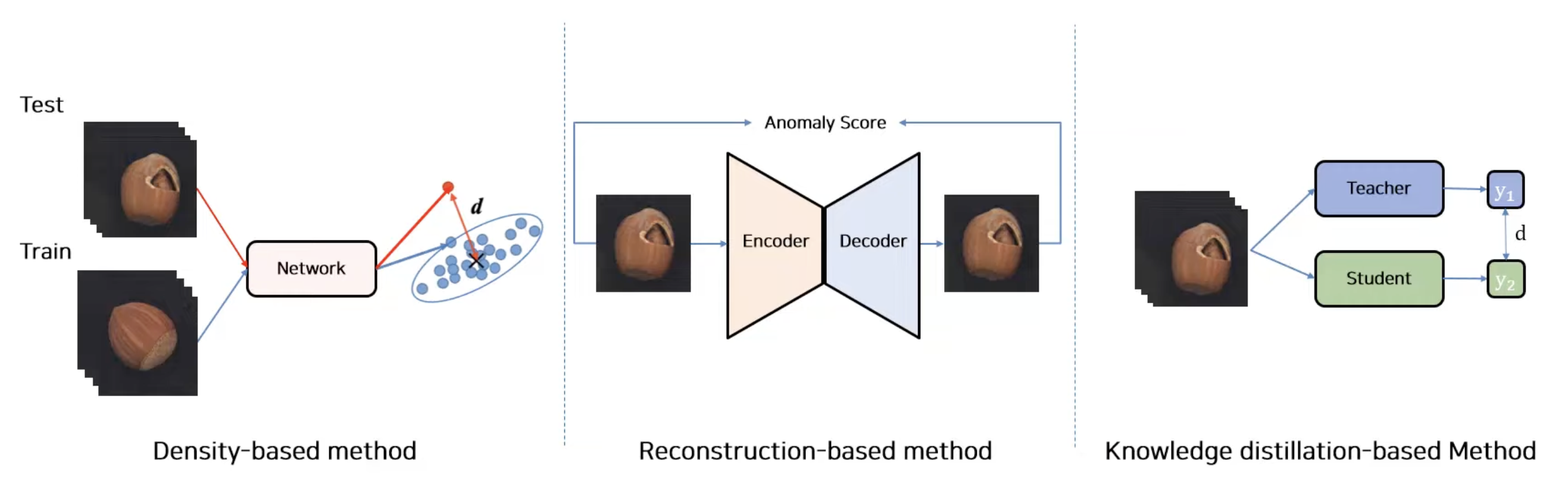
Density-based method
정상 데이터의 분포를 학습한 뒤 분포를 벗어나는 정도를 Anomaly score로 정의 하여 비정상 데이터를 탐지한다.
Reconstruction-based method
정상 데이터만을 복원하도록 학습하여 비정상 데이터를 추론할때 재구축된 결과와의 차이로 비정상 데이터 탐지한다.
Knowledge Distillation-based method
Teacher와 Student 간의 output 차이를 이용하여 비정상 데이터 탐지
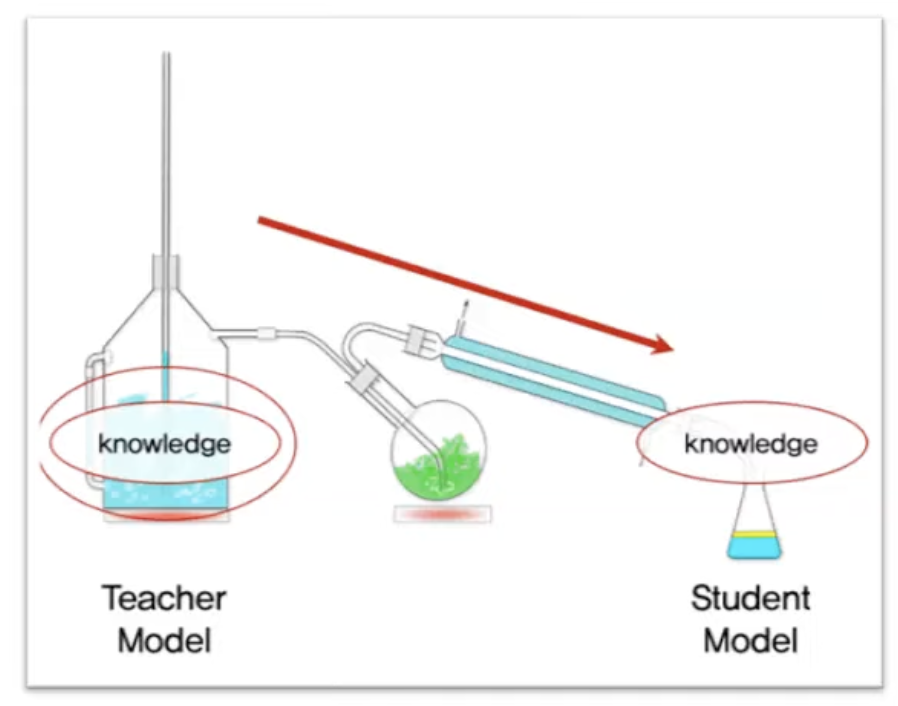
Knowledge distillation이란 2014년 “Distiling the Knowledge in a Neural Network" 에서 제안된 개념으로 잘 학습된 큰 네트워크(Teacher)의 지식을 실제로 사용하고자 하는 작은 네트워크(Student)에 전달하는 것이 목적이다. Teacher model의 성능은 최대한 유지한 채 모델의 크기를 줄이는 것이 주 목적이며 Student가 Teacher's soft label을 맞추도록 학습을 한다. Anomaly Detection에서는 Student가 Normal data에 대한 Teacher의 지식을 학습하고자 해당 구조 사용한다.

Anomaly Detection을 하기 위해 Knowledge Distillation를 사용할떄는 아래와 같은 방식으로 학습을 시킨다.

Student는 Teacher로 부터 Normal data에 대한 output만 학습했기 때문에 Teacher와 Student 간의 Output 차이는 크지 않다.
하지만 Anomaly data에 대해서 student는 Teacher로 부터 학습되지 않았기 때문에 Output 간의 차이가 발생한다.
따라서 Teacher 와 Student의 Output 간의 차이를 이용하여 Anomaly Detection / Localization을 수행한다.
TS 차이가 작다는 것은 Student가 Teacher와 유사한 Feature를 추출했다는 것이므로 Normal로 결과가 나오고 TS 차이가 크다는 것은 Student가 Teacher와 다른 Feature를 추출했다는 것으로 Abnormal하다고 판단하게 된다.
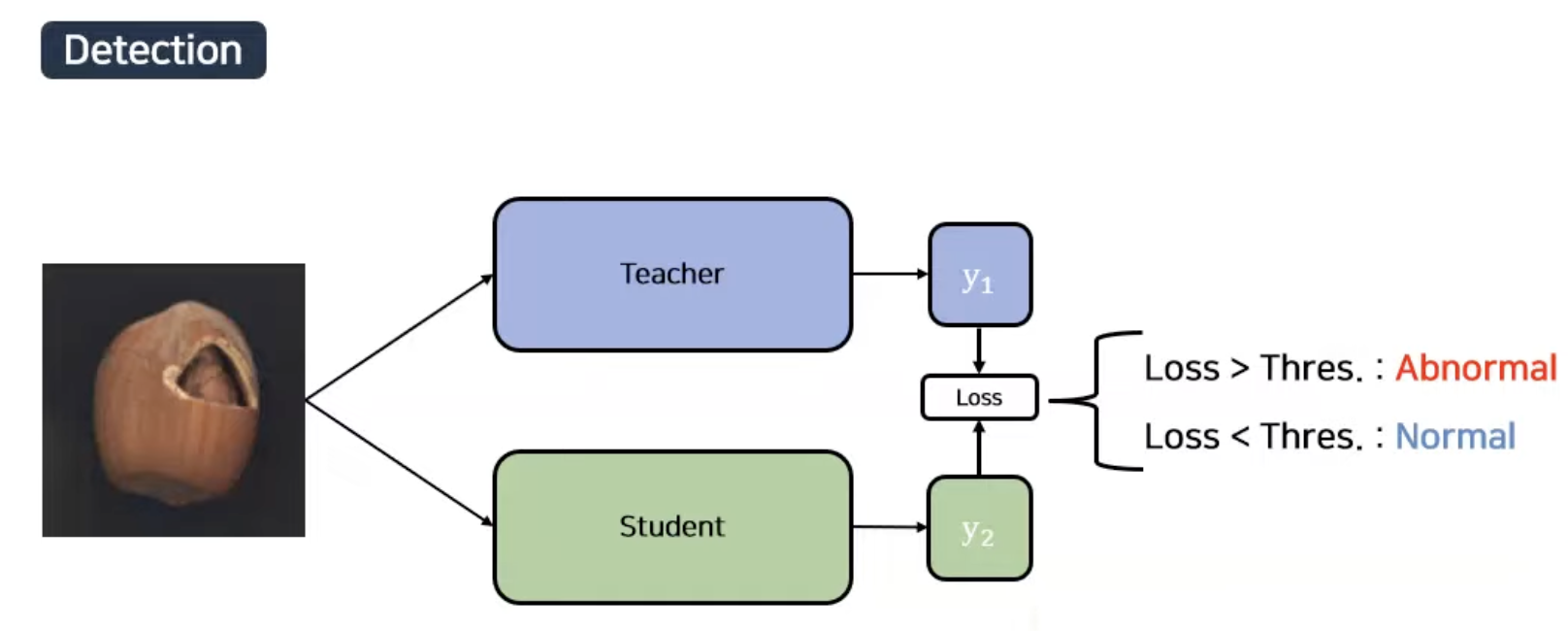
Detection은 loss의 크기를 이용하여 판단하게 되는 것이다.

Localization은 각 region마다 추출된 feature의 거리가 멀면 anomaly region으로 판단한다.
Multiresolution Knowledge Distillation for Anomaly Detection이라는 논문에서 제안된 Method를 추가적으로 살펴보자.
Knowledge distillation 학습 과정에서 더 나은 Information transfer를 위해 Multi resolution feature map 사용한다. 이를 통해 Student가 Normal data의 low-level, High-level information을 잘 학습할 수 있는 결과가 나왔다.
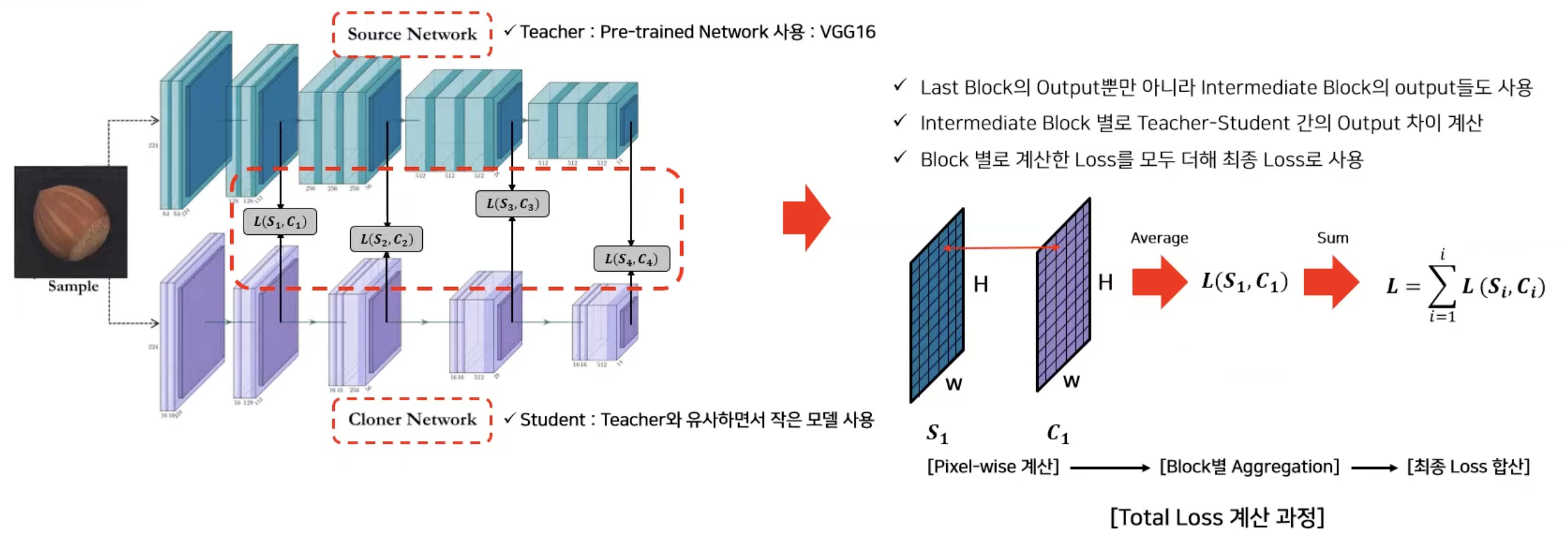
이때 학습할때 사용된 Loss function은 아래와 같다.

Detection시에는 Total Loss를 Anomaly Score로 사용한다.
Localization할때는 Input 데이터 Loss의 gradients를 이용해 Attribution map을 구하고 이를 Localization map으로 이용한다.
Gaussian filtering과 Normalization후 원본 사이즈로 Interpolation 해주고 얻어진 Localization map을 이용하여 Anomaly localization을 수행한다.
Normalizing Flow는 Deep Generative model 방법론 중 하나로 tractable density 라는 특징이 있는 모델이다. 변수 변환 공식 (The Change of Variables formula)의 아이디어에 기반하여 어떤 쉬운 분포(gaussian) 2에 invertible 한transformation function f 를 이용해 복잡한 확률 분포 p(x)를 모델링 한다. Input 데이터를 Gaussian latent space로 매핑하는 함수 f를 학습하고 f의 역함수를 이용해 Gaussian latent space로 부터 Input 데이터 샘플 생성한다.
변수 변환 공식에 대해서 살펴보자면 분포를 알고 있는 확률 변수 2가 있을 때 매핑 함수를 이용해 미지의 확률 변수(x) 를 계산하는 방법이다. 미지의 확률 변수가 x이고 T 분포를 갖는 확률 변수가 z 그리고 매핑 함수를 f라 할 때 아래와 같이 식이 정의된다.

여러개의 변수 변환 공식을 이용해서 Input data x를 latent space z로 변환하는 방식인다.

이때 Input 데이터의 분포를 학습하는 것이 목표 이므로 x의 likelihood를 최대화 하는 것을 목적 함수로 사용한다.
Affine Coupling layer는 Transformation function이 역함수를 취해 역추적이 가능해야하기에 가역적이어야 하고 matrix 크기가 커질 경우 행렬식 계산의 연산량이 많아지기 때문에 determinant 계산이 간단해야한다는 조건을 만족시키기 위해 고안된 방법이다.
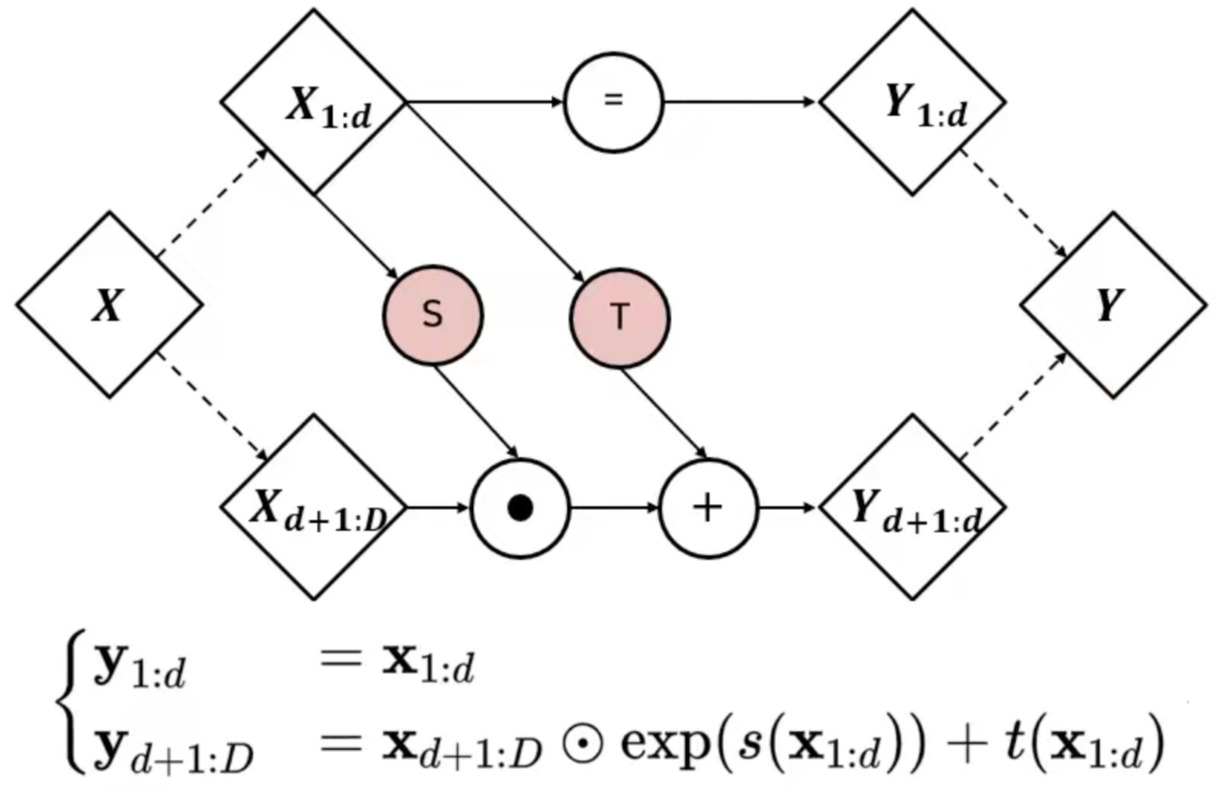
이름처럼 Affine transformation을 활용하는데 위처럼 계산이 된다. x를 channel에 따라 X(1:d)와 X(d+1:D) 두개로 분할 한다. Scaling(S), Translation(S)는 CNN 또는 MLP와 같이 Non-linear한 복잡한 함수로 구성된다. X1:d는 그대로 가져가며 Xd+1:D는 sub network S와 t를 통해 Affine transformation의 scaling, shift parameter 계산하는 데 사용된다.

Affine transformation을 역함수 취하면 변수의 위치만 바꿔주면 되기 때문에 가역적인 계산이라는 것을 알 수 있다.
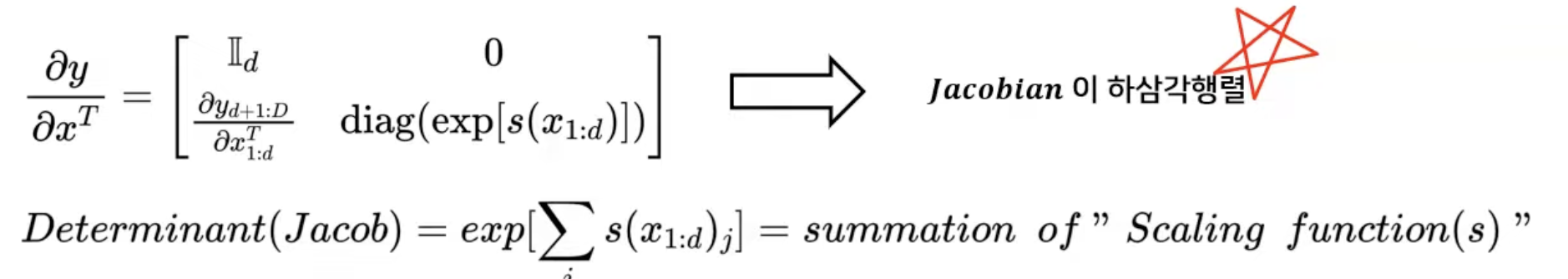
또한 Jacobian이 하삼각행렬 형태이기 때문에 Determinant가 단순한 덧셈으로 계산이 된다.
Normalizing Flow는 latent z의 likelihood를 input data x의 likelihood로 간주할 수 있다. Anomaly Detection의 경우 Normal data로 학습하기 때문에 Inference 단계에서 Normal data는 High Likelihood가 할당 된다. 반면 Anomaly data의 경우 Low likelihood가 할당 된다. 따라서 Likelihood를 직접 Anomaly Score로 사용하여 Anomaly Detection을 수행하면 된다. 하지만 vision분야에서 문제가 발생한다. 그 문제는 Normalizing Flow에 Input Image를 그대로 사용할 수 없다는 것이다. 그대로 사용할 경우 local-pixel correlation에 영향을 크게 받아 semantic content를 반영할 수 없어 likelihood를 최대화 하는 것에 한계가 존재 한다. 대신 사전학습 모델을 feature extractor로 사용하여 semantic content를 반영한 후 Normalizing Flow에 사용한다.

Image의 global, local context를 포함하는 fine-grained representation을 다루기 위해 다양한 scale의 multiple feature map을 활용하는 CS-Flow기법이 존재한다. Feature extractor로 부터 추출된 feature matrix를 그대로 Normalizing Flow의 input으로 사용하고 Normal feature의 likelihood를 최대화 하도록 Normalizing flow를 학습한다. Low-likelihood가 할당되는 것을 Anomaly로 판별한다.

다음은 C-Flow라는 방법론이다. Input data의 Positional 정보를 condition으로 사용하여 conditional Normalizing Flow를 수행하는 특징이 있다.

배경지식 공부할 것만 너무 많았지만 그중 일부만 넣었다. Anomaly Detection에 대해서 자세히 알아가는 중이라 당분간 고생좀 해야할 것이다. 본격적인 내용은 다음 글에서 정리하려한다.
'Robotics & AI > Paper review' 카테고리의 다른 글
| [논문 리뷰] YOLO-World: Real-Time Open-Vocabulary Object Detection 리뷰 (0) | 2024.04.04 |
|---|---|
| [논문 리뷰]Asymmetric Student-Teacher Networks for Industrial Anomaly Detection(2) (0) | 2024.04.01 |
| [논문리뷰] Deep Learning for Anomaly Detection: A Review (0) | 2024.03.28 |
| [논문 리뷰] DDPM (Denoising Diffusion Probabilistic Models) (2) | 2024.03.12 |
| [논문 리뷰] Auto-Encoding Variational Bayes(VAE) (1) | 2024.03.09 |



