학습 데이터 준비
word2vec에서 이용하는 신경망의 입력은 맥락이다. 그리고 정답 레이블은 맥락에 둘러싸인 중앙의 단어, 즉 타깃이다. 우리가 해야 할 일은 신경망에 맥락을 입력했을 때 타깃이 출현할 확률을 높이는 것이다. 말뭉치에서 맥락과 타깃을 만드는 작업을 진행해보자.

우선 말뭉치 텍스트를 단어 ID 로 변환해야 한다.
import sys
sys.path.append('..')
from common.util import preprocess
text = 'You say goodbye and I say hello.'
corpus, word_to_id, id_to_word = preprocess(text)
print(corpus)
print(id_to_word)그런 다음 단어 ID의 배열인 corpus로부터 맥락과 타깃을 만들어낸다. 아래 그림처럼 corpus를 주면 맥락과 타깃을 반환하는 함수를 만들자.
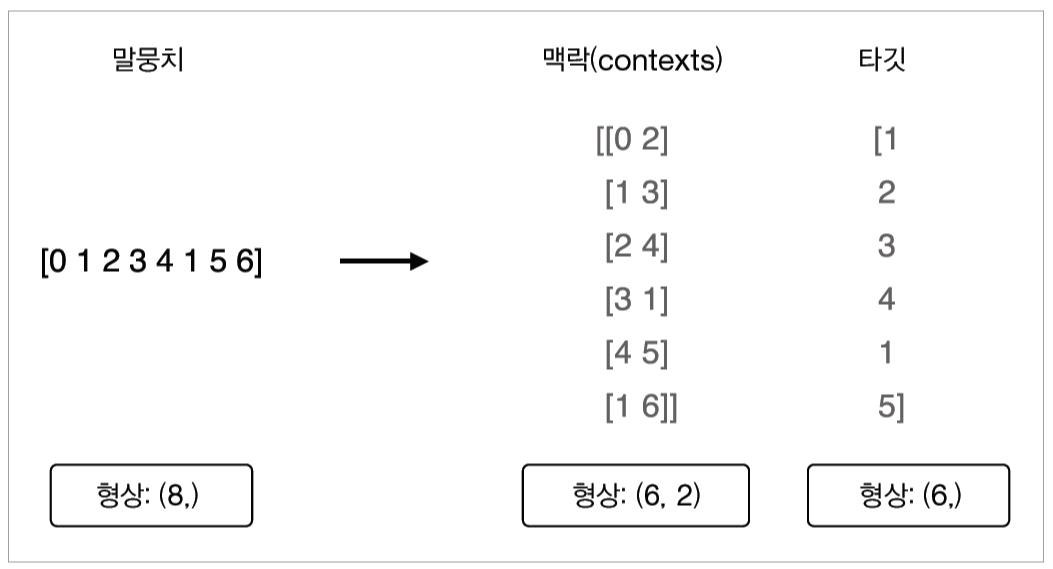
# common/util.py
def create_co_matrix(corpus, vocab_size, window_size=1):
'''동시발생 행렬 생성
:param corpus: 말뭉치(단어 ID 목록)
:param vocab_size: 어휘 수
:param window_size: 윈도우 크기(윈도우 크기가 1이면 타깃 단어 좌우 한 단어씩이 맥락에 포함)
:return: 동시발생 행렬
'''
corpus_size = len(corpus)
co_matrix = np.zeros((vocab_size, vocab_size), dtype=np.int32)
for idx, word_id in enumerate(corpus):
for i in range(1, window_size + 1):
left_idx = idx - i
right_idx = idx + i
if left_idx >= 0:
left_word_id = corpus[left_idx]
co_matrix[word_id, left_word_id] += 1
if right_idx < corpus_size:
right_word_id = corpus[right_idx]
co_matrix[word_id, right_word_id] += 1
return co_matrix위 함수에서 인수를 두 개 받는다. 하나는 단어 ID의 배열(corpus), 다른 하나는 맥락의 윈도우 크기(window_size)이다. 그리고 맥락과 타깃을 각각 넘파이 다차원 배열로 돌려준다. 이 함수를 사용하면 아래와 같이 나온다.
contexts, target = create_contexts_target(corpus, window_size=1)
print(contexts)
#[[0 2]
# [1 3]
# [2 4]
# [3 1]
# [4 5]
# [1 6]]
print(target)
# [1 2 3 4 1 5]one-hot으로 변환
아래 그림과 같이 맥락과 타깃을 원핫 표현으로 바꿔보자.
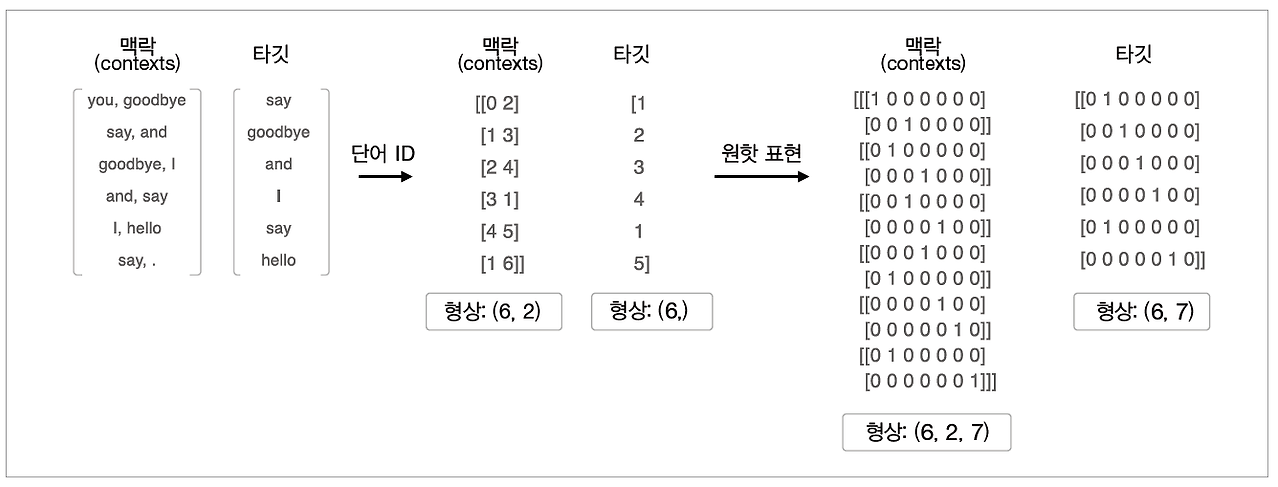
위 그림처럼 맥락과 타깃을 단어 ID에서 원핫 표현으로 변환하면 된다. 이때 각각의 다차원 배열의 형상에 주목해야 한다. 위 그림에서 단어 ID를 이용했을 때의 맥락의 형상은 (6,2)인데, 이를 one-hot 표현으로 변환하면 (6,2,7)이 된다.
convert_one_hot을 이용하여 변환을 하므로 해당 함수를 구현해보고 데이터 준비 과정을 진행하자.
# common/utill.py
def convert_one_hot(corpus, vocab_size):
'''원핫 표현으로 변환
:param corpus: 단어 ID 목록(1차원 또는 2차원 넘파이 배열)
:param vocab_size: 어휘 수
:return: 원핫 표현(2차원 또는 3차원 넘파이 배열)
'''
N = corpus.shape[0]
if corpus.ndim == 1:
one_hot = np.zeros((N, vocab_size), dtype=np.int32)
for idx, word_id in enumerate(corpus):
one_hot[idx, word_id] = 1
elif corpus.ndim == 2:
C = corpus.shape[1]
one_hot = np.zeros((N, C, vocab_size), dtype=np.int32)
for idx_0, word_ids in enumerate(corpus):
for idx_1, word_id in enumerate(word_ids):
one_hot[idx_0, idx_1, word_id] = 1
return one_hot# 데이터 준비 과정
import sys
sys.path.append('..') # 부모 디렉터리의 파일을 가져올 수 있도록 설정
from common.util import preprocess, create_contexts_target, convert_one_hot
text = 'You say goodbye and I say hello.'
corpus, word_to_id, id_to_word = preprocess(text)
contexts, target = create_contexts_target(corpus, window_size=1)
vocab_size = len(word_to_id)
target = convert_one_hot(target, vocab_size)
contexts = convert_one_hot(contexts, vocab_size)CBOW 모델 구현
구현해볼 모델은 아래와 같은 구조를 띄고 있다.
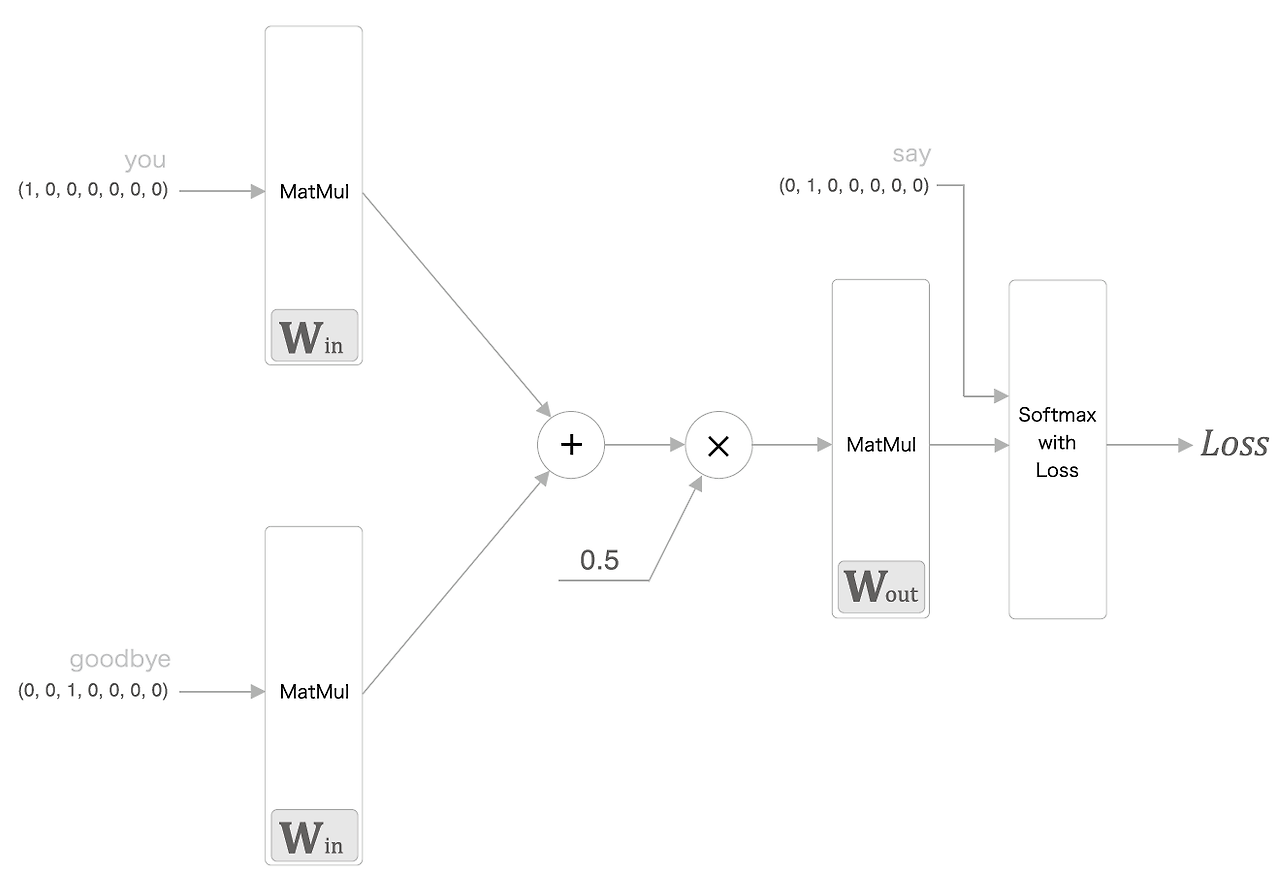
위 구조를 구현해보자.
# ch03/simple_cbow.py
import sys
sys.path.append('..')
import numpy as np
from common.layers import MatMul, SoftmaxWithLoss
class SimpleCBOW:
def __init__(self, vocab_size, hidden_size):
V, H = vocab_size, hidden_size
# 가중치 초기화
W_in = 0.01 * np.random.randn(V, H).astype('f')
W_out = 0.01 * np.random.randn(H, V).astype('f')
# 계층 생성
self.in_layer0 = MatMul(W_in)
self.in_layer1 = MatMul(W_in)
self.out_layer = MatMul(W_out)
self.loss_layer = SoftmaxWithLoss()
# 모든 가중치와 기울기를 리스트에 모은다.
layers = [self.in_layer0, self.in_layer1, self.out_layer]
self.params, self.grads = [], []
for layer in layers:
self.params += layer.params
self.grads += layer.grads
# 인스턴스 변수에 단어의 분산 표현을 저장한다.
self.word_vecs = W_in신경망의 순전파인 forward() 메서드를 구현한다.
def forward(self, contexts, target):
h0 = self.in_layer0.forward(contexts[:, 0])
h1 = self.in_layer1.forward(contexts[:, 1])
h = (h0 + h1) * 0.5
score = self.out_layer.forward(h)
loss = self.loss_layer.forward(score, target)
return loss마지막으로 역전파인 backward() 를 구현한다. 우선 역전파는 아래 그림의 구조를 통해 진행되고 이를 기반으로 구현해보자.
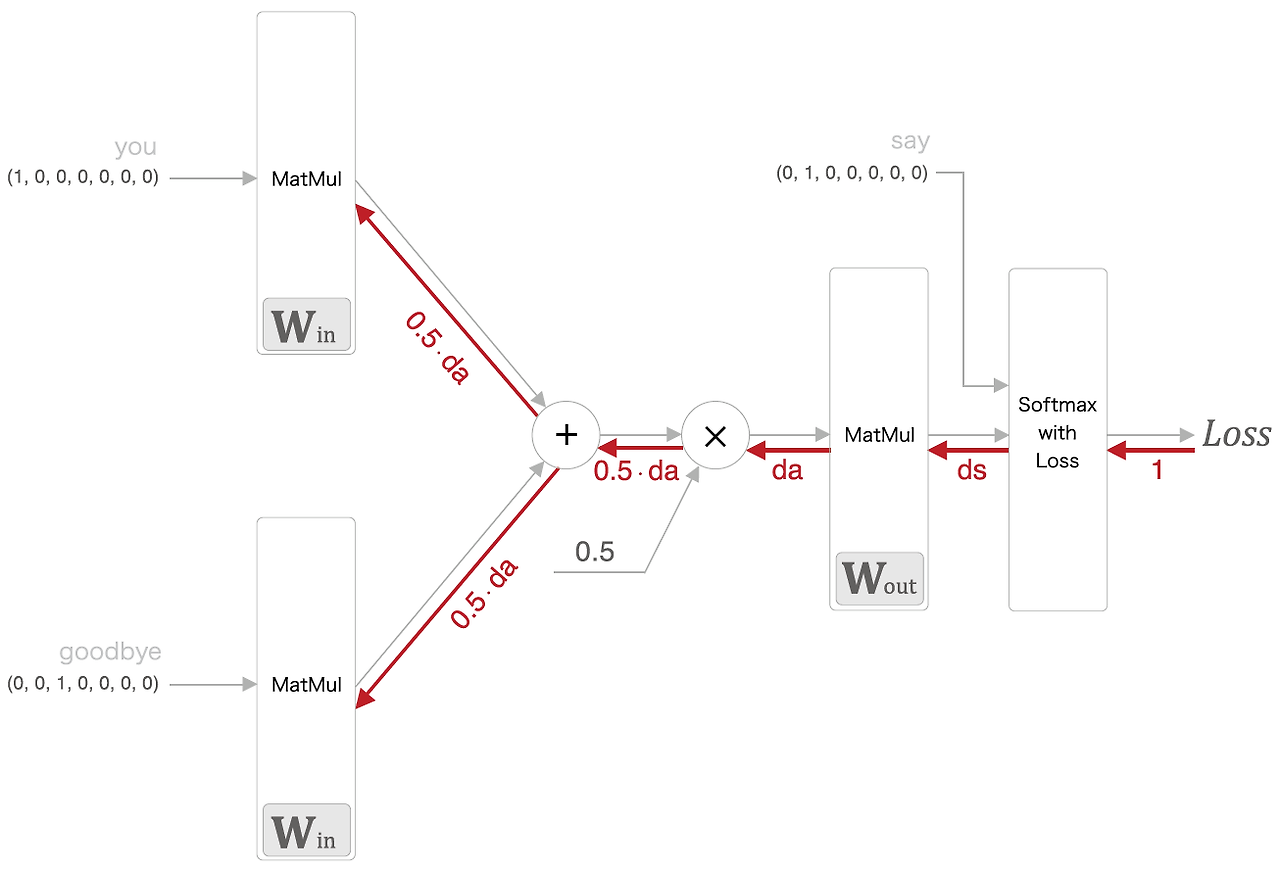
def backward(self, dout=1):
ds = self.loss_layer.backward(dout)
da = self.out_layer.backward(ds)
da *= 0.5
self.in_layer1.backward(da)
self.in_layer0.backward(da)
return None이미 각 매개변수의 기울기를 인스턴스 변수 grads에 모아뒀기 때문에 forward()를 호출하고 backward()를 실행하는 것만으로도 grads 리스트의 기울기가 갱신된다.
이제 학습 코드를 구현하자. CBOW 모델의 학습은 일반적인 싱경망의 학습과 완전히 같다. 학습 데이터를 준비해 신경망에 입력한 다음, 기울기를 구하고 가중치 매개변수를 순서대로 갱신해간다.
import sys
sys.path.append('..') # 부모 디렉터리의 파일을 가져올 수 있도록 설정
from common.trainer import Trainer
from common.optimizer import Adam
from simple_cbow import SimpleCBOW
from common.util import preprocess, create_contexts_target, convert_one_hot
window_size = 1
hidden_size = 5
batch_size = 3
max_epoch = 1000
text = 'You say goodbye and I say hello.'
corpus, word_to_id, id_to_word = preprocess(text)
vocab_size = len(word_to_id)
contexts, target = create_contexts_target(corpus, window_size)
target = convert_one_hot(target, vocab_size)
contexts = convert_one_hot(contexts, vocab_size)
model = SimpleCBOW(vocab_size, hidden_size)
optimizer = Adam()
trainer = Trainer(model, optimizer)
trainer.fit(contexts, target, max_epoch, batch_size)
trainer.plot()가장 흔히 쓰이는 Adam을 optimizer function으로 선택하였다. Train 코드에서는 학습 데이터로부터 미니배치를 선택한 다음, 신경망에 입력해 기울기를 구하고, 그 기울기를 Optimizer 에 넘겨 매개변수를 갱신하는 일련의 작업을 수행한다.
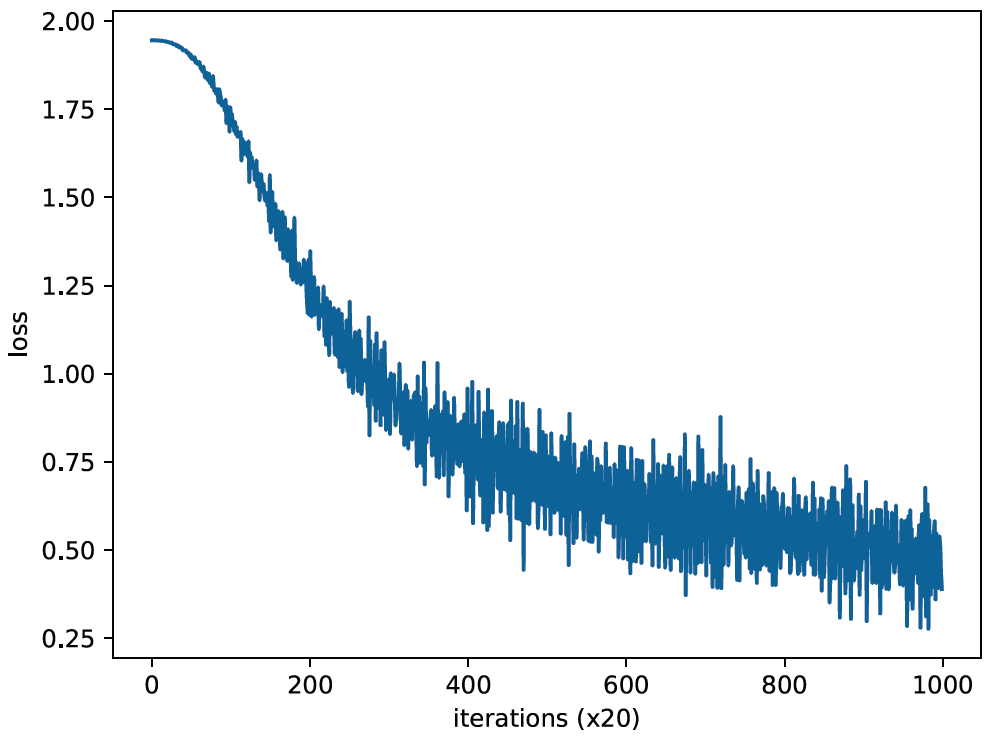
Loss function을 살펴보면 제대로 학습이 진행되며 loss가 줄어드는 것을 볼 수 있다. 이번에는 input Layer의 MatMul계층의 가중치를 꺼내 실제 값을 확인해보자.
word_vecs = model.word_vecs
for word_id, word in id_to_word.items():
print(word, word_vecs[word_id])you [ -0.9031807 -1.0374491 -1.4682057 -1.3216232 0.93127245]
say [ 1.2172916 1.2620505 -0.07845993 0.07709391 -1.2389531]
goodbye [ -1.0834033 -0.8826921 -0.33428606 -0.5720131 1.0488235 ]
and [ 1.0244362 1.0160093 -1.6284224 -1.6400533 -1.0564581 ]
i [ -1.0642933 -0.9162385 -0.31357735 -0.5730831 1.041875 ]
hello [ -0.9018145 -1.035476 -1.4629668 -1.3058501 0.9280102 ]
. [ 1.0985303 1.1642815 1.4365371 1.3974973 -1.0714306 ]
'Drawing (AI) > DeepLearning' 카테고리의 다른 글
| Multi-modal Learning (0) | 2024.03.20 |
|---|---|
| 딥러닝 직접 구현하기 - (word2vec 보충) (0) | 2024.02.04 |
| 딥러닝 직접 구현하기 - (word2vec) (0) | 2024.02.01 |
| 딥러닝 직접 구현하기 - (추론 기반 기법) (0) | 2024.02.01 |
| 딥러닝 직접 구현하기 - (통계 기반 기법 개선) (1) | 2024.01.29 |



