Intro
Multi-modal Learning은 말그대로 여러개의 modality, 즉 여러개의 데이터 형식으로부터 학습하는 인공지능을 말한다. 예를들어 이미지+텍스트를 input으로 넣어서 사람의 표정과 그 상황을 기반으로 더 정확한 감성분석을 진행할 수 있겠다.

흔히 modality의 종류는 VARK(Visual, Auditory, Read/Write, Kinesthetic) 4가지정도로 추려진다.
멀티모달의 종류
멀티모달에는 크게 Early Fusion, Late Fusion, Joint or Intermediate Fusion 3가지 종류가 있다.
Early Fusion은 다양한 모달리티의 데이터를 입력 단계에서 결합한다. 여러 유형의 데이터를 하나의 통합된 특성 벡터로 변환해 모델에 입력하는 방식이다. 이 방법은 다양한 데이터 소스 간의 상호 작용을 모델이 더 쉽게 학습할 수 있게 해주지만, 각 데이터 유형의 고유한 특성을 잃어버릴 수 있는 단점이 있다.
Late Fusion은 모델의 출력 단계에서 여러 모달리티로부터의 예측 결과를 결합한다. 각 모달리티를 독립적으로 처리하며, 최종적인 결정은 이들 모델의 예측을 조합해 이루어진다. 이 방법은 각 모달리티가 독립적으로 중요한 특성을 학습할 수 있게 해주지만, 모델이 데이터 간의 복잡한 상호 작용을 학습하는 데 한계가 있을 수 있다.
Joint or Intermediate Fusion은 모델의 중간 단계에서 여러 모달리티의 정보를 결합한다. Early Fusion과 Late Fusion의 장점을 결합한 형태로, 여러 모달리티에서 추출된 특성을 결합해 더 복잡한 표현을 학습할 수 있다. 이 접근법은 모델이 데이터 간의 상호 작용을 더 효과적으로 학습할 수 있도록 해주지만, 구현이 더 복잡할 수 있다.
최근 연구에서는 딥러닝과 거의 함께 사용하기 때문에 feature를 한번에 학습시키기 위해 extract된 feature를 concat해서 neural network에 input으로 넣는 방식이 많이 채택된다.
Feature vector concatation
Concat하는 방식이 하나로 정해진 것이 아니기에 상황에 맞는 방식으로 concat을 적절히 하는 것이 모델의 성능에 큰 영향을 미친다. 우선 음성과 이미지를 이용하여 음성 향상을 시켜 음성 신호의 노이즈를 줄이는 논문(Audio-visual speech enhancement using multimodal deep convolutional neural networks)에서 사용한 방식을 살펴보자.
음성 신호와 입의 모양을 입력으로 받는 구조이다. 각각 Convolution layer를 통과한 후에 각 network에서 나온 feature vector를 simple concatenation 후에 merged layer로 변환한다. fully connected layer를 추가하여 object function을 통해 전체 parameter를 학습하고 각각의 결과를 복원 예측하여 학습하는 방식을 이용한다. 오토인코더와 유사하게 layer를 통과하여 원본을 복원하고 그 차이를 이용하여 학습하는 방식이기에 아래와 같은 함수를 이용한다.
Automatic driver stress level classification using multimodal deep learning
다음 참고할 논문은 차량 사고에 큰 영향을 주는 주행 중 운전자의 스트레스 수준을 분석하고 감지하는 것을 목표로 하는 논문으로 운전자의 스트레스에 영향을 주는 데이터는 ECG 신호, 차량 데이터(스티어링 휠, 브레이크 페달 등), 상황 데이터 (기상데이터 등)이며 이를 딥러닝 방법으로 융합하여 우수한 성능 냈다.
위 구조에서 볼 수 있듯이 다양한 데이터를 CNN에 통과시키고 fusion된 feature에서 LSTM을 통해 sequential한 특징도 찾아내는 시도를 하였다.
AVEF(Audio-Visual emotion fusion)
다음 논문은 multi-modal learning이 가장 많이 사용되는 도메인중 하나인 감정분류 관련 논문이다. audio, video 데이터를 통해 인간의 감정 인식 모델을 구축한 모델이 제안되었다.
오디오는 Mel-Spectogram이라는 형태로 변환되어 음성이 제거된 영상과 함께 CNN layer를 통과시켰다. Mel-Spectogram은 2D CNN을, 영상은 시간축이 추가된 3D CNN을 이용했다. 이때 미리 나누어둔 segment 별로 학습을 진행하고 fusion network를 통해 합치는 과정을 거쳤다.
나온 결과를 average pooling을 하여 하나의 값으로 합쳐주고 SVM을 이용하여 감정분류를 진행하였다.
Tensor fusion network for multimodal sentiment analysis
다음은 똑같이 감정분류를 하는 논문이나 언어, 비디오, 오디오 총 3가지 modality를 이용했다는 특징이 있다. 기존에는 모두 같은 형식의 layer를 이용하여 특징을 추출하고 fusion했다면 이 논문에서는 언어 모델로는 GLoVe와 LSTm, 비디오 모델로는 FACET network, 마지막으로 오디오 모델로는 COVAREP network가 쓰인 것이 특징이다.
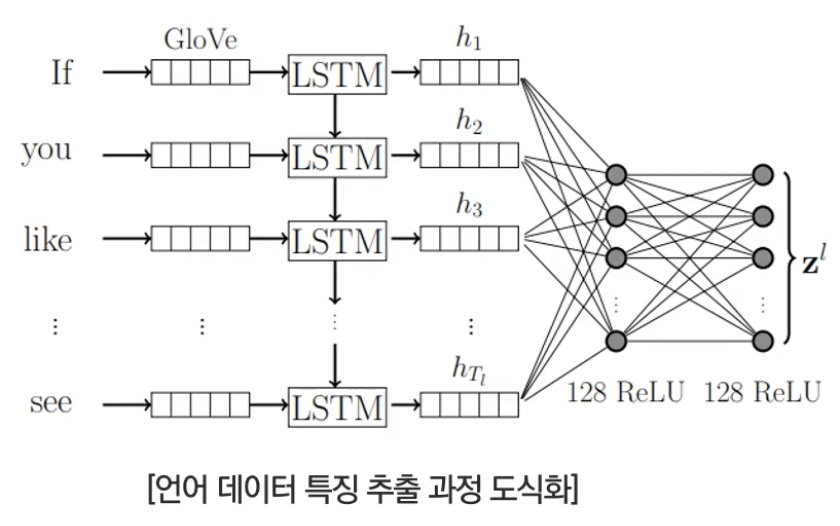
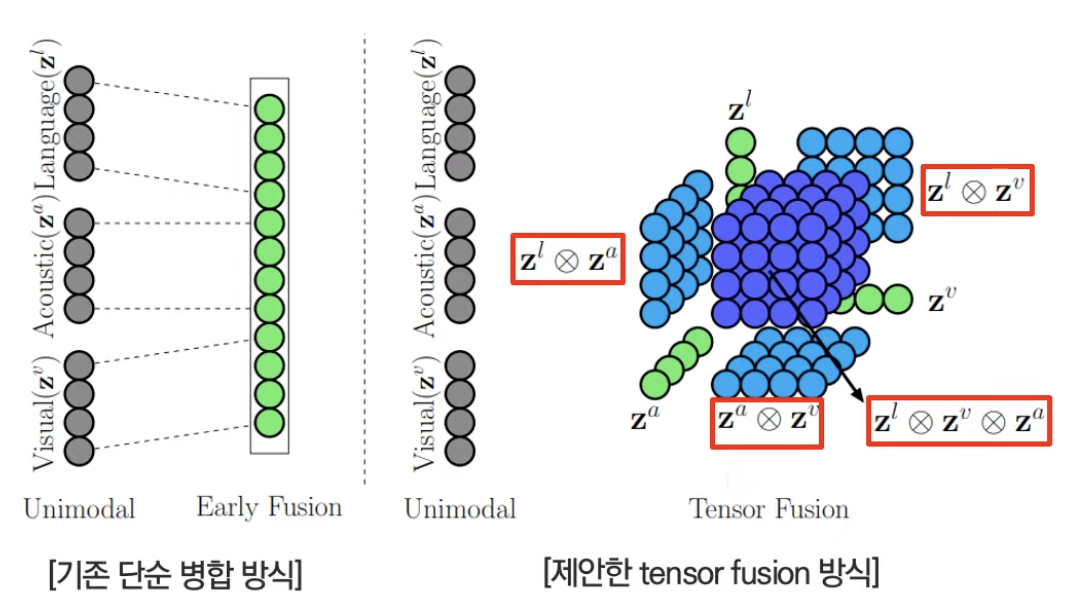
또한 fusion방식으로 채택된 tensor fusion은 bimodal 뿐만아니라 trimodal의 특징을 모두 잡을 수 있는 방식이다.
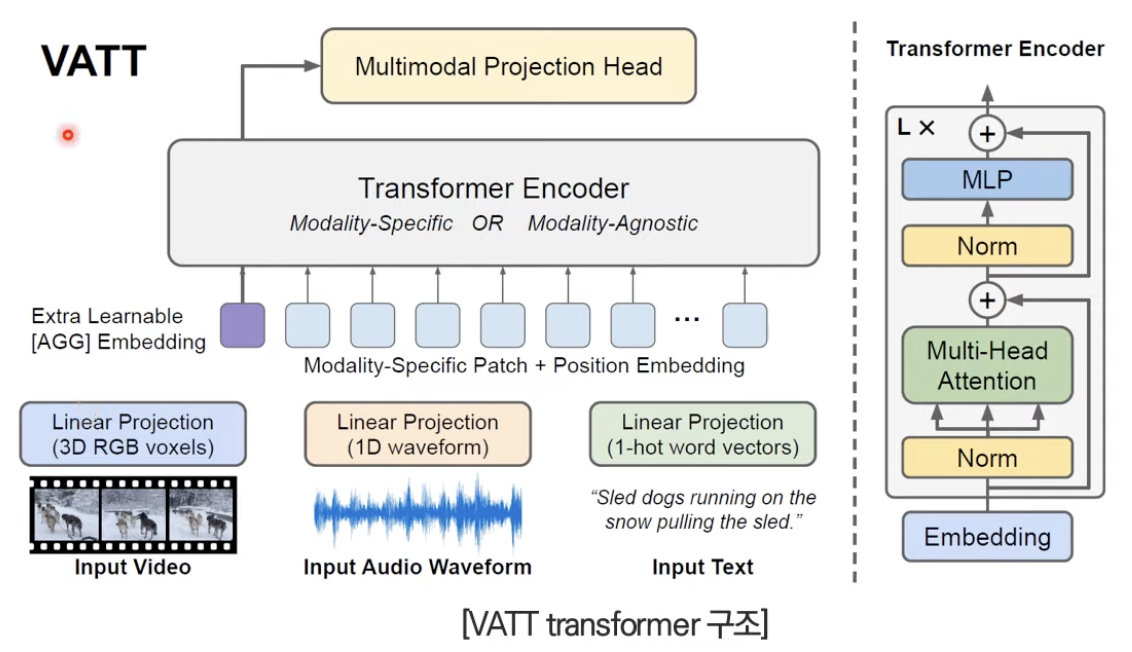
VATT
Vatt: Transformers for multimodal self-supervised learning from raw video, audio and text 논문은 논문 제목 그대로 video, audio, text를 이용한 trimodal deep learning 모델이다. 가장 큰 특징은 각 모달의 데이터를 토큰화하고 linear projection을 통해 나온 값을 transformer encoder의 입력으로 사용한 것이다.
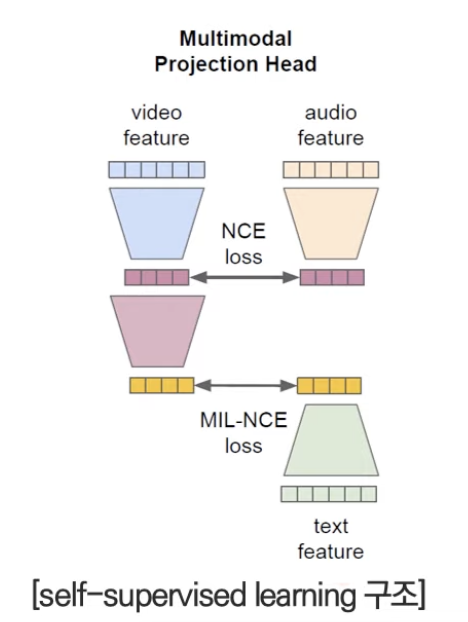
Transformer에서 추출된 각각의 특징 벡터를 contrastive learning 기반으로 학습시킨다. 이때 아래와 같이 Video-Audio pair, Video-Text pair로 조합해 각각 NCE loss, MIL-NCE loss를 사용한다.
아래는 loss function 계산 과정과 이를 통해 최종적으로 어떤 값을 기반으로
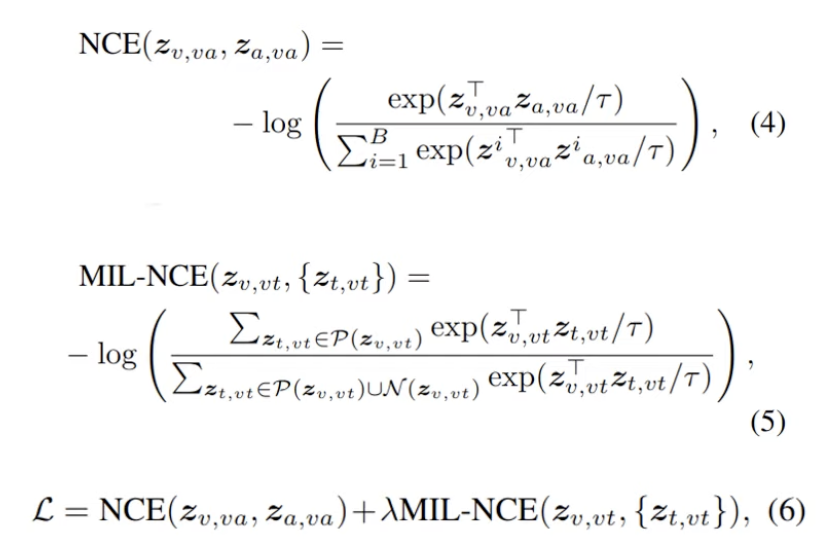
예시 코드
import warnings
warnings.filterwarnings('ignore')
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import os
import joblib
import random
from tqdm import tqdm
# 오디오 데이터처리
import librosa
import librosa.display
import IPython.display as ipd
from imblearn.over_sampling import SMOTE
from sklearn.preprocessing import MinMaxScaler, StandardScaler
from sklearn.model_selection import train_test_split
# 모델
from copy import deepcopy
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision.transforms as transforms
from torch.utils.data import DataLoader, Dataset
from sklearn.ensemble import RandomForestClassifier
from sklearn.neural_network import MLPClassifier
from sklearn.metrics import accuracy_score# 오디오 데이터 처리하는데 필요한 변수
# 사람목소리는 대부분 16000 안에 포함됨
sample_rate = 16000
# mfcc coefficient 개수
n_mfcc = 30
# DNN 모델에 필요한 변수
n_epochs = 100
batch_size = 128
# gpu사용 변수
device = torch.device('cuda:3') if torch.cuda.is_available() else torch.device('cpu')
def get_meta_data(csv_path):
df = pd.read_csv(csv_path)
# 성별이 male, female로 적혀있어서 숫자로 변경
df['gender'] = np.where(df['gender']=='male', 0, 1)
return df
train_df = get_meta_data('../../data/covid19/train_data.csv')
test_df = get_meta_data('../../data/covid19/test_data.csv')
# 오디오 확인
ipd.Audio('../../data/covid19/train/00001.wav')
def get_data(data_path, df, train=True):
ids = []
labels = []
ages = []
genders = []
respiratories = []
fever_or_muscle = []
mfccs = []
for file in tqdm(os.listdir(data_path)):
if 'wav' in file:
data_id = int(file[:-4])
ids.append(data_id)
wav_path = os.path.join(data_path, file)
data, sr = librosa.load(wav_path, sr=sample_rate)
mfcc = librosa.feature.mfcc(y=data, sr=sr, n_mfcc=n_mfcc)
age = int(df[df.id==int(file[:-4])].age)
ages.append(age)
gen = int(df[df.id==int(file[:-4])].gender)
genders.append(gen)
resp = int(df[df.id==int(file[:-4])].respiratory_condition)
respiratories.append(resp)
pain = int(df[df.id==int(file[:-4])].fever_or_muscle_pain)
fever_or_muscle.append(pain)
mean_mfcc = []
for m in mfcc:
mean_mfcc.append(np.mean(m))
mfccs.append(mean_mfcc)
if train:
label = int(df[df.id==int(file[:-4])].covid19)
labels.append(label)
# break
if train:
meta_data = {'id':ids,
'label':labels,
'age':ages,
'gender':genders,
'respiratory':respiratories,
'fever_or_muscle':fever_or_muscle
}
df_meta = pd.DataFrame(meta_data)
return df_meta, mfccs
else:
meta_data = {'id':ids,
'age':ages,
'gender':genders,
'respiratory':respiratories,
'fever_or_muscle':fever_or_muscle
}
df_meta = pd.DataFrame(meta_data)
return df_meta, mfccsdef make_train_mfcc_df(data_path, df):
df_meta, mfccs = get_data(data_path, df, train=True)
df_mfcc = pd.DataFrame(mfccs, columns=['mfcc' + str(i+1) for i in range(n_mfcc)])
df = df_meta.join(df_mfcc)
df.to_csv('../../data/covid19/result/train_mfcc.csv', index=False)
return df
def make_test_mfcc_df(data_path, df):
df_meta, mfccs = get_data(data_path, df, train=False)
df_mfcc = pd.DataFrame(mfccs, columns=['mfcc' + str(i+1) for i in range(n_mfcc)])
df = df_meta.join(df_mfcc)
df.to_csv('../../data/covid19/result/test_mfcc.csv', index=False)
return df
train_mfcc = make_train_mfcc_df('../../data/covid19/train', train_df)
test_mfcc = make_test_mfcc_df('../../data/covid19/test', test_df)오디오 특성 시각화
# 시각화 예시
y, sr = librosa.load('../../data/covid19/train/00001.wav', sr=sample_rate, duration=10)
fig, ax = plt.subplots(nrows=2, sharex=True)
librosa.display.waveshow(y, sr=sr, ax=ax[0])
ax[0].set(title='Envelope view, mono')
ax[0].label_outer()
y_harm, y_perc = librosa.effects.hpss(y)
librosa.display.waveshow(y_harm, sr=sr, alpha=0.5, ax=ax[1], label='Harmonic')
librosa.display.waveshow(y_perc, sr=sr, color='r', alpha=0.5, ax=ax[1], label='Percussive')
ax[1].set(title='Multiple waveforms')
ax[1].legend()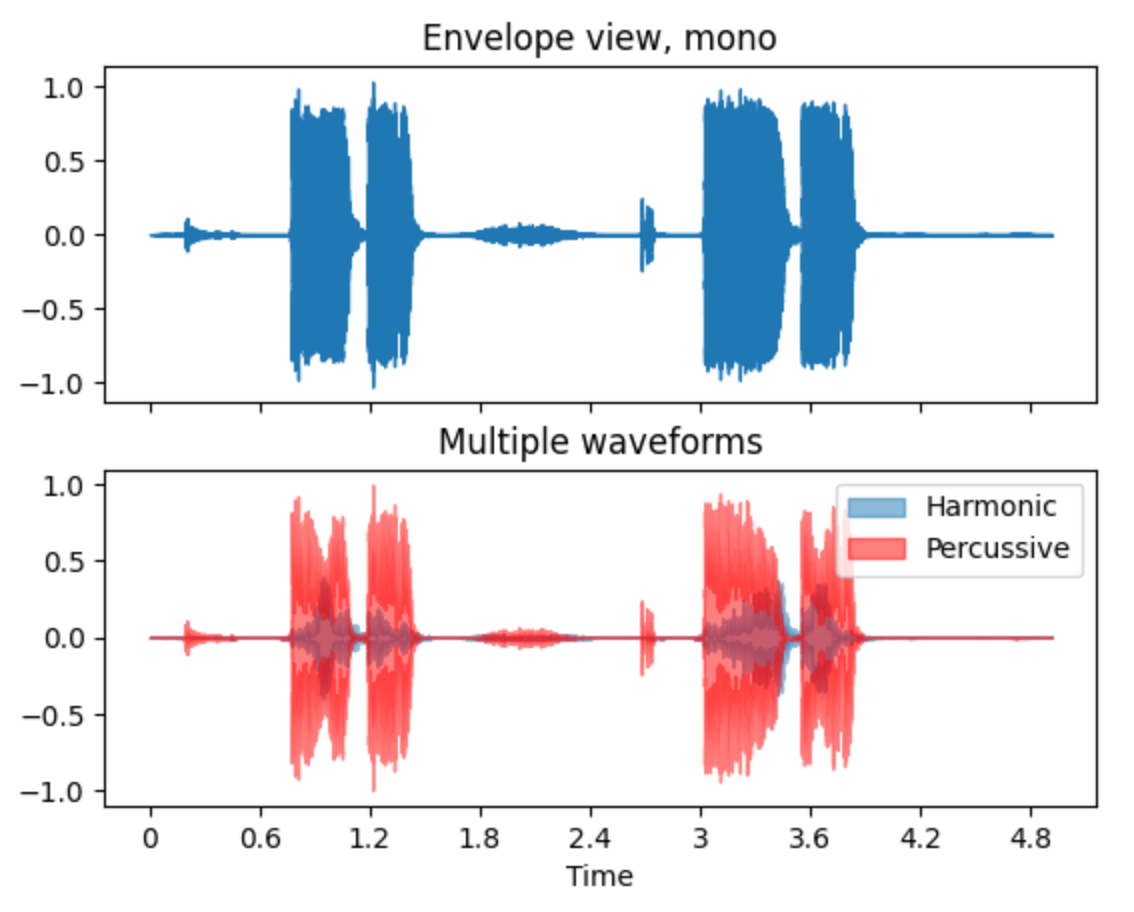

#Over Sampling
#라벨의 개수를 보면 정상 3499개, 비정상 306개로 데이터 불균형이 심각하다.
#SMOTE 라는 오버샘플링 기법을 사용해 데이터 불균형 문제를 일부 해소해준다.
X = train_mfcc.drop(['id', 'label'], axis=1)
y = train_mfcc['label']
sampler = SMOTE(random_state=100)
X_sample, y_sample = sampler.fit_resample(X, y)
print('-----Over Sampling-----')
print(y.value_counts())
print(y_sample.value_counts())
X_train, X_val, y_train, y_val = train_test_split(X_sample, y_sample, test_size=0.2, random_state=100, stratify=y_sample)
print('-----Train Valid Split-----')
print(X_train.shape, y_train.shape, X_val.shape, y_val.shape)# random forest
model = RandomForestClassifier(random_state=100)
model.fit(X_train, y_train)
joblib.dump(model, 'SMOTE_RF.pkl')
val_pred = model.predict(X_val)
rf_accuracy = accuracy_score(y_val, val_pred)
rf_accuracy
#0.95
딥러닝 이용
class MyModel(nn.Module):
def __init__(self, input_size):
super(MyModel, self).__init__()
self.input_size = input_size
self.layer1 = torch.nn.Sequential(nn.Linear(self.input_size, 16),
nn.LeakyReLU())
self.layer2 = torch.nn.Sequential(nn.Linear(16, 8),
nn.LeakyReLU())
self.layer3 = nn.Linear(8, 1)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.sigmoid(x)
return x
loss_fn = nn.BCELoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
losses = []
best_loss = 1
dnn_accuracy = 0.0000000001
for epoch in range(n_epochs):
model.train()
running_loss = 0
for x, y in data_loader:
x = x.to(device)
y = y.to(device)
y = y.unsqueeze(1)
y_pred = model(x)
loss = loss_fn(y_pred, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
running_loss += loss.item()
loss = running_loss/len(data_loader)
losses.append(loss)
output = (y_pred >= 0.5).float()
accuracy = (output == y).float().mean()
if accuracy > dnn_accuracy:
dnn_accuracy = accuracy
best_model = deepcopy(model)
best_loss = loss
if epoch % 10 == 0:
print(f'Epoch {epoch}/{n_epochs} \tLoss {loss:.6f} \tAccuracy {accuracy}')
torch.save(best_model, 'SMOTE_DNN.pth')
torch.save(best_model.state_dict(), 'SMOTE_DNN_state_dict.pth')# 간단한 Linear 딥러닝 모델로 예측
model = torch.load('./SMOTE_DNN.pth')
model.load_state_dict(torch.load('./SMOTE_DNN_state_dict.pth'))
model.eval()
# test 데이터 tensor 변환
x = torch.tensor(test_mfcc.values).float()
x = x.to(device)
# 모델 예측
preds = model(x)
preds = preds.detach().cpu().numpy()
preds테스트해볼 코드를 올려주신 "Sona"님 글을 참고했습니다.
'Robotics & AI > DeepLearning' 카테고리의 다른 글
| Building Distance Estimation (0) | 2024.08.14 |
|---|---|
| 딥러닝 직접 구현하기 - (word2vec 보충) (0) | 2024.02.04 |
| 딥러닝 직접 구현하기 - (word2vec 학습) (0) | 2024.02.02 |
| 딥러닝 직접 구현하기 - (word2vec) (0) | 2024.02.01 |
| 딥러닝 직접 구현하기 - (추론 기반 기법) (0) | 2024.02.01 |



