Intro
Data Creator Camp의 미션 수행을 위한 공부 및 미션 수행 과정을 기록하고자 한다. 시작으로 이미지 분류를 위한 다양한 딥러닝 모델을 살펴보고자한다.
AlexNet
AlexNet은 2012년 ImageNet Large Scale Visual Recognition Challenge (ILSVRC)에서 우승하며 딥러닝과 CNN의 인기를 크게 높인 모델이다. 해당 모델을 소개하는 논문의 1저자의 이름이 Alex여서 이렇게 이름이 붙게 되었다.
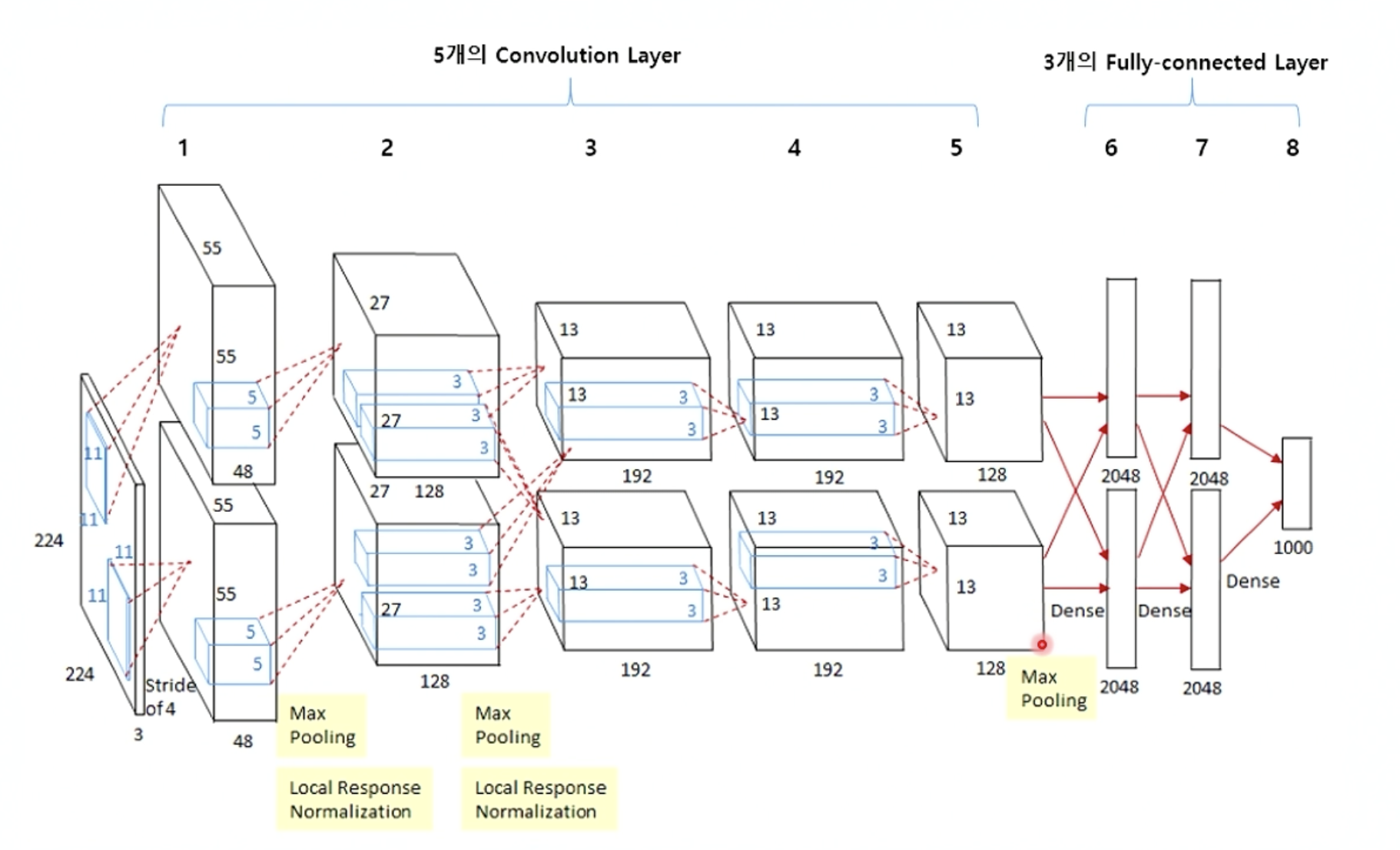
크게 봤을 때 5개의 Convolution layer이후에 3개의 Fully-connected layer로 이루어진 구조이다. 2,4,5번째 convolution layer는 전단계의 같은 채널의 feature map들과만 연결되어 있는 반면 3번째 convolution layer는 전단계의 두 채널의 feature map과 모두 연결되어 있다는 특징이 있다.
Layer에서의 작동 과정을 살펴보면 우선 input은 227x227x3사이즈의 데이터가 들어간다. 다시 말해서 227x227사이즈의 rgb 컬러 이미지 데이터가 들어간다고 할 수 있다. 여기서 activation function으로 ReLU가 이용되었다. 이는 기존의 방식인 tanh 함수를 이용하는 것에 비해 6배나 빠르다. 이 이후로 지금까지도 ReLU 함수가 activation function으로 선호되는 경향이 있다. 추가로 Fully-connected layer에서는 dropout이 사용되어 과적합을 방지하였다.
VGGNet
VGGNet은 Visual Geometry Group에서 개발한 딥러닝 모델로, 2014년 ImageNet Large Scale Visual Recognition Challenge (ILSVRC)에서 두 번째로 높은 성능을 보였다. VGGNet은 그 구조의 간결함과 규격화된 접근 방식으로 유명하다.

VGGNet은 굉장히 deep한 모델이다. VGG19은 19개, VGG16은 16개의 convolution layer로 구성이 되어있다. 모든 convolution layer에서 3X3의 작은 크기의 균일한 filter를 이용하여 비선형성을 증가시켰다. 또한 마지막에서 multi class classification을 위해 softmax 함수를 이용한 것 외의 모든 layer에서 activation function으로 ReLU 함수를 이용했다.

3X3 convolution을 3단을 쌓으면 7X7 convolution 연산을 하는것과 같은 성능을 내면서 parameter수는 줄여서 연산속도를 높이는 효과를 낸다.
ResNet
ResNet은 "Residual Network"의 줄임말로, 2015년에 Kaiming He, Xiangyu Zhang, Shaoqing Ren, 그리고 Jian Sun에 의해 제안되었다. ResNet은 ImageNet Large Scale Visual Recognition Challenge (ILSVRC)에서 우승한 모델로, 그 뒤로도 여러 연구 및 산업 분야에서 널리 사용되었다.
이는 microsoft에서 개발한 residual learning을 이용한 방법이다. residual learning이란 layer한칸을 건너뛴 값을 layer를 통과한 값에 더해주어 이전의 정보가 보다 잘 전달되도록 하는 방식이다. 이는 gradient vanishing, exploding문제를 해결하는데 도움을 주고 shorcut connection이라고도 부른다.

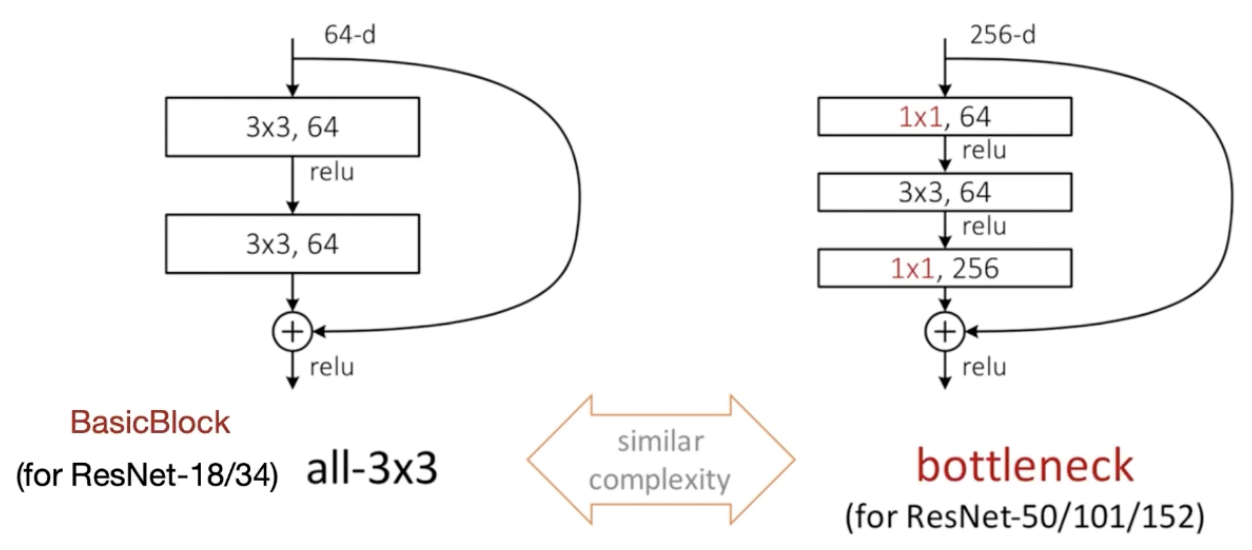
기본적으로 ResNet은 VGGNet의 구조와 유사하고 합성곱층과 shorcut connection을 추가해준 구조이다. 이후에는 계속해서 layer를 추가하여 수백, 수천개의 layer를 가진 구조도 만들었다.

위의 그림에서 실선은 입력으로부터 들어온 feature map의 크기를 바꾸지 않기 위해 stride와 zero padding을 1로 하고 1x1 크기인 shortcut connection을 뜻하고 점선은 feature map의 size를 줄이기 위한 shortcut connection이고 이는 network의 깊이가 2배가 되는 시점이 이용한다.
EfficientNet
이미지 처리 관련 Network가 발전함에 따라 모델의 크기를 키우려는 노력이 많았는데 모델의 크기를 키우는 방법은 3가지정도로 요약할 수 있다. Network의 깊이를 깊게 하기, 채널의 너비 즉 filter의 개수를 늘리기, input image의 해상도를 높이기가 그 3가지 방식이다. EfficientNet은 2019년에 Mingxing Tan 및 Quoc V. Le에 의해 Google AI에서 발표된 모델로, 네트워크의 깊이, 너비, 그리고 입력 이미지의 해상도를 AutoML을 이용하여 최적의 값을 찾아서 SOTA를 달성한 논문이다.

Backbone Model을 AutoML을 이용하여 작은 사이즈의 모델로 선정하였고 그것을 EfficientNet b0라고 부르고 이 모델을 다양한 방식으로 scaling하며 b1, b2... 이렇게 나아가며 결국 SOTA에 달성하였고 이를 EfficientNet이라 부른다.
GoogleLeNet
신경망 내부적으로 계산 자원의 효율을 높여서 신경망 층수를 늘린 inception이라는 특징이 있는 GoogleLeNet은 22개의 층으로 구성되어 있으나 parameter수는 13백만개로 VGGNet의 1/12밖에 안되지만 그 성능은 훨씬 뛰어났다.

고전적인 CNN구조를 따르면서도 Inception이라는 새로운 개념의 모듈을 이용했기 때문이다.
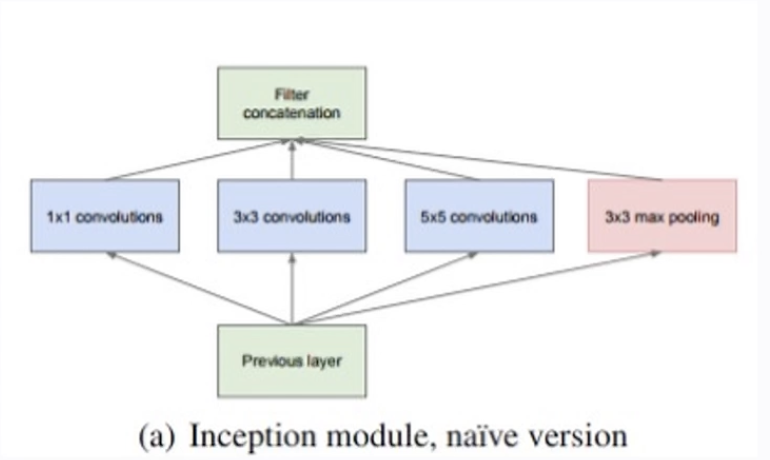
Inception module은 convolution층과 pooling층을 번갈아 가면서 쌓던 기존의 모델들과는 다르게 한 module에서 병렬로 통과 시키고 그 결과를 모으는 방식이다. 다만 이러한 module은 연산량이 너무 많아지기 때문에 차원 축소를 통해 그 연산량을 조절하였다.

이때 차원 축소를 어느정도 선만 넘지 않는다면 모델의 성능을 낮추지 않는 것도 확인되었다.
'Coloring (Additional Study) > Contest' 카테고리의 다른 글
| 대구 교통사고 피해 예측 AI 경진대회 - (1) (3) | 2023.11.19 |
|---|---|
| DCC 전이학습 (2) | 2023.11.03 |
| DCC 한국음식 분류 모델 (0) | 2023.10.29 |
| DCC Normalization (0) | 2023.10.29 |
| DCC 클래스별 시각화 (0) | 2023.10.13 |


