Introduction
간단한 프로젝트를 진행하기 위해 사회적으로 문제가 되는 이슈를 해결해보고자 한다. 가짜뉴스는 최근 몇년간 더욱 그 문제가 부각되고있다. 왜냐하면 디지털 시대에 우리는 정보에 쉽게 접근할 수 있지만, 그만큼 거짓 정보와 혼란스러운 소식에 노출되기 때문이다. 특히 가짜 뉴스는 사회적 분열과 혼란을 일으키며, 개인과 사회의 안녕을 위협한다. 이러한 상황에서 진실을 매도하고 극심하게 확산되는 가짜 뉴스를 탐지하는 혁신적인 솔루션을 필요로 한다고 생각했다.
Data Analysis
아래의 데이터들을 조합하여 새로운 데이터셋을 만들어서 하나의 데이터 셋의 스타일에 overfitting되는 것을 방지하고자 하였다.

import pandas as pd
SEED = 10
# Load the WELFake_Dataset
df_WELFake = pd.read_csv('WELFake_Dataset.csv')
df_WELFake = df_WELFake.sample(frac=0.5, random_state=SEED) # Take a random sample of half the data
# Save the new data set
df_WELFake.to_csv('fake_true.csv', index=False)
# Load the True.csv and Fake.csv
df_true = pd.read_csv('True.csv')
df_fake = pd.read_csv('Fake.csv')
# Take a random sample of half the data
df_true = df_true.sample(frac=0.5, random_state=SEED)
df_fake = df_fake.sample(frac=0.5, random_state=SEED)
# Reorder the columns and add the labels
df_true = df_true[['subject', 'title', 'text', 'date']]
df_fake = df_fake[['subject', 'title', 'text', 'date']]
df_true['label'] = 1
df_fake['label'] = 0
# Add the data to the WELFake dataset
df_WELFake = pd.concat([df_WELFake, df_true, df_fake])
# Load the fake_or_real_news dataset
df_fake_or_real = pd.read_csv('fake_or_real_news.csv')
# Take a random sample of half the data
df_fake_or_real = df_fake_or_real.sample(frac=0.5, random_state=SEED)
# Rename the label to be consistent with the other data
df_fake_or_real['label'] = df_fake_or_real['label'].replace({'TRUE': 0, 'FAKE': 1})
# Add the data to the WELFake dataset
df_WELFake = pd.concat([df_WELFake, df_fake_or_real])
# Save the new dataset
df_WELFake.to_csv('WELFake_Dataset.csv', index=False)길게는 3000자까지도 길어지는 데이터셋이었지만 512자 이상부터는 프로그램의 성능이 크게 차이가 나지 않아서 512자로 제한하고 프로그램을 만들었다.
가짜뉴스와 진짜뉴스의 특징을 대략적으로 살펴보기 위해서 빈도수 상위 30개의 단어를 wordcloud로 출력해보았는데 겹치는 단어가 너무 많아서 특징을 살펴보기가 쉽지 않았다.
따라서 상위 30개 단어중에 겹치는 단어들을 제외하고 살펴보니 조금더 특징이 잘 보였다.
상위 30개 단어 출력
import pandas as pd
from collections import Counter
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize
import matplotlib.pyplot as plt
from wordcloud import WordCloud
from tqdm import tqdm
import seaborn as sns
# Load data
df = pd.read_csv('fake_true.csv')
df.dropna(subset = ['text', 'title'], inplace = True)
df['text'] = df['title'] + ' ' + df['text']
# Add num_words column to the dataframe
df['num_words'] = df['text'].apply(lambda x: len(word_tokenize(x)))
plt.figure(figsize = (10,6))
sns.countplot(x = df['label'], alpha = 0.8)
plt.title('Distribution of Fake - 0 /Real - 1 News')
plt.show()
plt.figure(figsize = (20,6))
sns.histplot(df['num_words'], bins = range(1, 3000, 50), alpha = 0.8)
plt.title('Distribution of the News Words count')
plt.show()
# Define stopwords
stop_words = set(stopwords.words('english'))
def get_top_n_words(corpus, n=50):
# Initialize a Counter object
freq_dist = Counter()
for text in tqdm(corpus, desc="Processing text"):
# Convert text to lowercase
text = text.lower()
# Tokenize and filter out stopwords
tokens = word_tokenize(text)
tokens = [word for word in tokens if word.isalpha()]
tokens = [word for word in tokens if word not in stop_words]
# Update the frequency distribution
freq_dist.update(tokens)
return freq_dist.most_common(n)
# Separate fake and true news
fake_news = df[df['label'] == 0]['text']
true_news = df[df['label'] == 1]['text']
# Get top 20 words
top_fake = get_top_n_words(fake_news)
top_true = get_top_n_words(true_news)
print("Top 30 words in fake news:")
print(top_fake)
print("\nTop 30 words in true news:")
print(top_true)
def create_wordcloud(words, title):
print(f"Creating wordcloud: {title}")
wordcloud = WordCloud(width=800, height=500, random_state=21, max_font_size=300).generate_from_frequencies(dict(words))
plt.figure(figsize=(10, 7))
plt.imshow(wordcloud, interpolation="bilinear")
plt.axis('off')
plt.title(title)
plt.show()
# Create word clouds
create_wordcloud(top_fake, "Fake News")
create_wordcloud(top_true, "True News")no_overlap
import pandas as pd
from collections import Counter
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize
import matplotlib.pyplot as plt
from wordcloud import WordCloud
from tqdm import tqdm
import seaborn as sns
# Load data
df = pd.read_csv('fake_true.csv')
df.dropna(subset = ['text', 'title'], inplace = True)
df['text'] = df['title'] + ' ' + df['text']
# Define stopwords
stop_words = set(stopwords.words('english'))
def get_top_n_words(corpus, n=100):
# Initialize a Counter object
freq_dist = Counter()
for text in tqdm(corpus, desc="Processing text"):
# Convert text to lowercase
text = text.lower()
# Tokenize and filter out stopwords
tokens = word_tokenize(text)
tokens = [word for word in tokens if word.isalpha()]
tokens = [word for word in tokens if word not in stop_words]
# Update the frequency distribution
freq_dist.update(tokens)
return freq_dist.most_common(n)
# Separate fake and true news
fake_news = df[df['label'] == 0]['text']
true_news = df[df['label'] == 1]['text']
# Get top 100 words
top_fake = dict(get_top_n_words(fake_news, 100))
top_true = dict(get_top_n_words(true_news, 100))
# Remove overlapping words
unique_fake = {word: freq for word, freq in top_fake.items() if word not in top_true}
unique_true = {word: freq for word, freq in top_true.items() if word not in top_fake}
# Match the length of lists
len_min = min(len(unique_fake), len(unique_true))
unique_fake = dict(sorted(unique_fake.items(), key=lambda item: item[1], reverse=True)[:len_min])
unique_true = dict(sorted(unique_true.items(), key=lambda item: item[1], reverse=True)[:len_min])
print("Top words in fake news (no overlap):")
print(list(unique_fake.keys()))
print("\nTop words in true news (no overlap):")
print(list(unique_true.keys()))
def create_wordcloud(words, title):
print(f"Creating wordcloud: {title}")
wordcloud = WordCloud(width=800, height=500, random_state=21, max_font_size=300).generate_from_frequencies(words)
plt.figure(figsize=(10, 7))
plt.imshow(wordcloud, interpolation="bilinear")
plt.axis('off')
plt.title(title)
plt.show()
# Create word clouds
create_wordcloud(unique_fake, "Fake News")
create_wordcloud(unique_true, "True News")Classification with LSTM
import pandas as pd
import numpy as np
import matplotlib as plt
import seaborn as sns
import tensorflow as tf
from keras.utils import pad_sequences
from keras.layers import Input, Dense, Bidirectional, Dropout, Embedding
from sklearn.model_selection import train_test_split
from keras.preprocessing.text import Tokenizer
from keras.callbacks import EarlyStopping
from sklearn.model_selection import train_test_split
from sklearn.metrics import confusion_matrix, classification_report
import matplotlib.pyplot as plt
import pickle
tf.compat.v1.logging.set_verbosity(tf.compat.v1.logging.ERROR)
SEED = 10
df = pd.read_csv('fake_true.csv')
df.dropna(subset = ['text', 'title'], inplace = True)
df['text'] = df['title'] + ' ' + df['text']
X = df['text']
y = df['label']
df['num_words'] = df['text'].apply(lambda x: len(x.split()))
#split the dataset into training and test sets
X_train, X_test, y_train, y_test = train_test_split(X, y, stratify = y, random_state = SEED)
#define Keras Tokenizer
tok = Tokenizer()
tok.fit_on_texts(X_train)
#return sequences
sequences = tok.texts_to_sequences(X_train)
test_sequences = tok.texts_to_sequences(X_test)
#print size of the vocabulary
print(f'Train vocabulary size: {len(tok.word_index)}')
#maximum sequence length (512 to prevent memory issues and speed up computation)
MAX_LEN = 512
#padded sequences
X_train_seq = pad_sequences(sequences,maxlen=MAX_LEN)
X_test_seq = pad_sequences(test_sequences,maxlen=MAX_LEN)
X_train_seq.shape[1]
#define the model
model = tf.keras.Sequential([
Input(name='inputs',shape=[MAX_LEN]),
Embedding(len(tok.word_index)+1, 128, mask_zero=True),
Bidirectional(tf.keras.layers.LSTM(128, return_sequences=True)),
Bidirectional(tf.keras.layers.LSTM(64)),
Dense(16, activation='relu'),
Dropout(0.5),
Dense(1, activation='sigmoid')
])
#compile model
model.compile(loss=tf.keras.losses.BinaryCrossentropy(),
optimizer=tf.keras.optimizers.Adam(0.01),
metrics=['accuracy'])
#model summary
model.summary()
history = model.fit(X_train_seq, y_train, epochs=5,
validation_split = 0.2, batch_size = 64, callbacks=[EarlyStopping(monitor='val_accuracy',mode='max', patience=3, verbose=False,restore_best_weights=True)])
# 모델 저장
model.save('my_model.h5')
with open('tokenizer.pickle', 'wb') as handle:
pickle.dump(tok, handle, protocol=pickle.HIGHEST_PROTOCOL)
#plot the train/validation loss and accuracy
def plot_graphs(history, metric):
plt.plot(history.history[metric])
plt.plot(history.history['val_'+metric], '')
plt.xlabel("Epochs")
plt.ylabel(metric)
plt.legend([metric, 'val_'+metric])
plt.figure(figsize=(16, 6))
plt.subplot(1, 2, 1)
print(plot_graphs(history, 'accuracy'))
plt.subplot(1, 2, 2)
print(plot_graphs(history, 'loss'))
test_loss, test_acc = model.evaluate(X_test_seq, y_test)
y_hat = model.predict(X_test_seq)
print('Test Loss:', test_loss)
print('Test Accuracy:', test_acc)
## print classification report
print(classification_report(y_test, np.where(y_hat >= 0.5, 1, 0)))
#plot the confusion matrix
plt.figure(figsize = (8,6))
sns.heatmap(confusion_matrix(y_test, np.where(y_hat >= 0.5, 1, 0)), annot=True,
fmt='', cmap='Blues')
plt.xlabel('Predicted Labels')
plt.ylabel('Real Labels')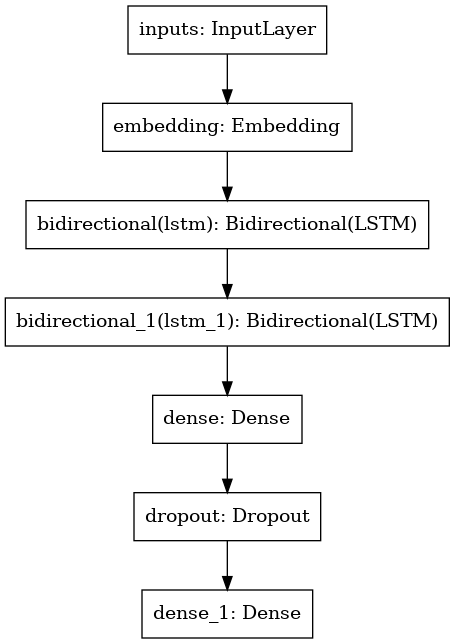
위 코드에서 sequential 모델은 위와 같이 BiLSTM을 이용했다.
Result and Prediction
우선 테스트 결과를 살펴보았다.
Test Loss: 0.07639668881893158
Test Accuracy: 0.9743360280990601
precision recall f1-score support
0 0.98 0.97 0.97 8757
1 0.97 0.98 0.97 9128
overfitting이 제대로 해결이 되었는지 확인하기 위하여 아예 새로운 데이터셋에 성능평가를 다시 진행하였다.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import tensorflow as tf
from keras.utils import pad_sequences
from keras.models import load_model
from sklearn.metrics import confusion_matrix
import pickle
tf.compat.v1.logging.set_verbosity(tf.compat.v1.logging.ERROR)
SEED = 10
# Load the saved tokenizer
with open('tokenizer.pickle', 'rb') as handle:
tok = pickle.load(handle)
# Load the saved model
model = load_model('my_model.h5')
# Load the new data for prediction
df_new = pd.read_csv('test_data.csv')
df_new.dropna(subset=['text', 'title'], inplace=True)
df_new['text'] = df_new['title'] + ' ' + df_new['text']
# Reduce the data size to 1/10
df_new = df_new.sample(frac=0.1, random_state=SEED)
X_new = df_new['text']
y_new = df_new['class']
# Preprocess the new data
MAX_LEN=700
sequences_new = tok.texts_to_sequences(X_new)
X_new_seq = pad_sequences(sequences_new, maxlen=MAX_LEN)
# Perform prediction on the new data
y_pred = model.predict(X_new_seq)
# Convert predictions to labels
y_pred_labels = np.where(y_pred >= 0.5, 'Fake', 'Real')
# Calculate evaluation metrics
confusion = confusion_matrix(y_new, y_pred_labels)
precision = confusion[1, 1] / (confusion[1, 1] + confusion[0, 1])
recall = confusion[1, 1] / (confusion[1, 1] + confusion[1, 0])
f1_score = 2 * (precision * recall) / (precision + recall)
type1_error = confusion[0, 1] / (confusion[0, 0] + confusion[0, 1])
type2_error = confusion[1, 0] / (confusion[1, 0] + confusion[1, 1])
# Print the evaluation metrics
print("Confusion Matrix:")
print(confusion)
print("Precision:", precision)
print("Recall:", recall)
print("F1-Score:", f1_score)
print("Type 1 Error:", type1_error)
print("Type 2 Error:", type2_error)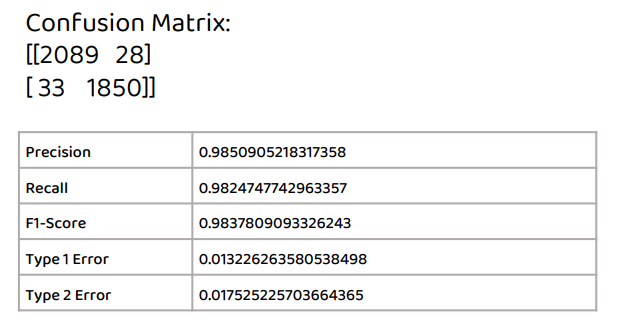
내 프로그램이 어떤 방식으로 real과 fake를 판단하는지 보기 위해 LIME알고리즘을 이용했다.
Transformer를 이용하지 않아서 Attention알고리즘은 이용할 수 없어서 최대한 간단한 알고리즘을 이용해서 알아보았다.
LIME
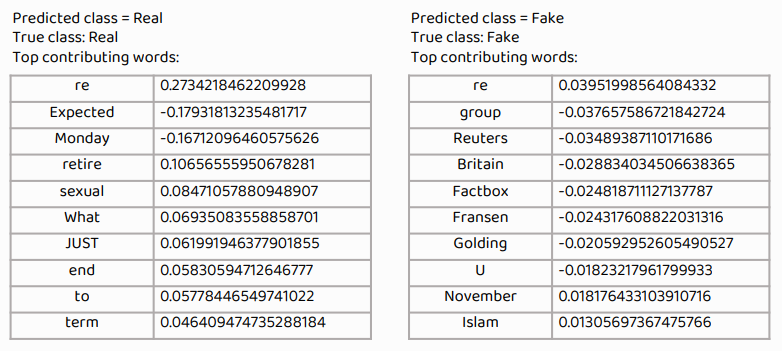
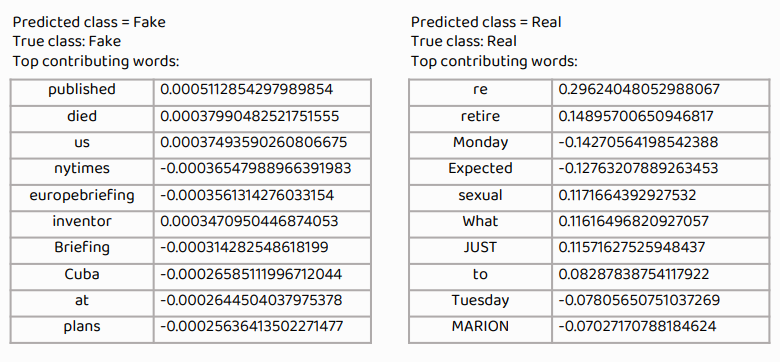
여기서 재밌는 것을 발견하였다. re라는 단어가 real news로 판단하도록하는 굉장히 큰 양의 가중치값을 갖고 있는 것이다. 직접 알아보니 Re라는 것이 후속기사를 의미하는 것이었다. 보통 후속기사를 쓸정도의 기사들은 real news인 경우가 굉장히 많기 때문에 큰 가중치를 가진 단어임을 알게 되었다. Reuters라는 단어는 큰 음의 가중치를 가진 단어였는데 이는 로이터라는 신문사가 애초에 신뢰도가 그닥 높지 않은데 대부분의 찌라시 나르기식의 fake news들이 '로이터발' 이런식의 제목이나 글이 있기 때문으로 추측되었다.
Conclusion
사실 위의 내용들만 보면 굉장히 성능이 좋은 프로그램 같이 보이지만 실제 최신 CNN 뉴스를 input으로 넣었을때는 정확도가 40%정도로 저조했다. 이는 데이터 셋이 모두 2015년에서 2017년 사이의 데이터이므로 해당 년도의 뉴스 데이터에 대해서는 정확도가 꾀나 높지만 최신 데이터가 전혀 학습되지 못하였기에 최신 데이터에는 굉장히 취약한 것을 알 수 있다.
그럼에도 굉장히 유익하고 재밌는 프로젝트였다. 인간이 해결하기 어려운 사회적인 문제를 딥러닝 기술을 이용하여 해결할 수 있다는 사실이 내가 인공지능 공부를 하는 것에 의미를 더욱 부여해주는 느낌이 들었다.
'Drawing (AI) > Models' 카테고리의 다른 글
| OpenAI 숨바꼭질 전문(?) AI (0) | 2023.02.19 |
|---|---|
| 체중 감소 예측 프로그램 (딥러닝) (1) | 2023.02.07 |

