728x90
Simple Linear Regression
Regression의 이론적인 부분은 이전에 몇번 다뤄봤기에 간단하게 넘어가고 python을 통해 직접 다루는 것에 초점을 맞추고자 한다.
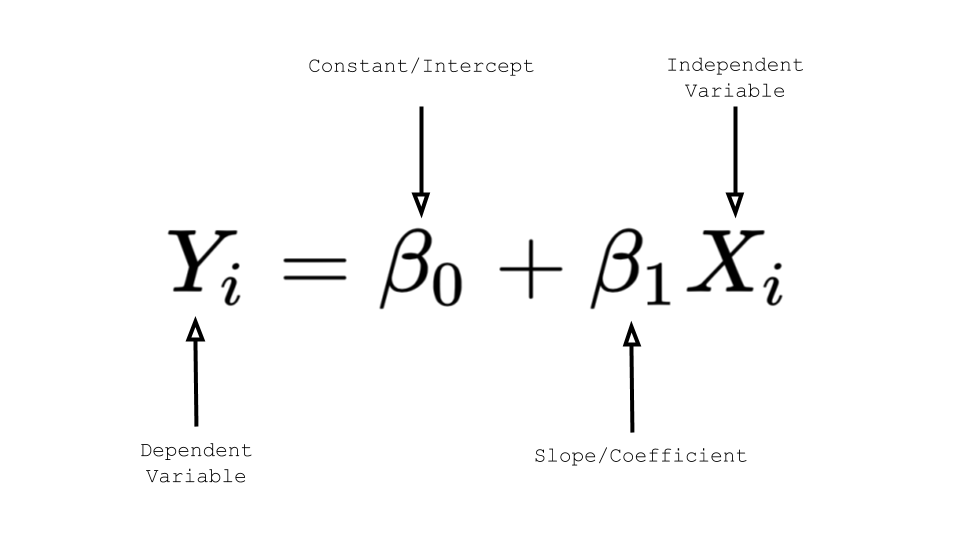
위와 같이 1차방정식 형태로 설명된다.
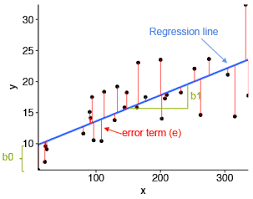
Simple Linear Regressin model
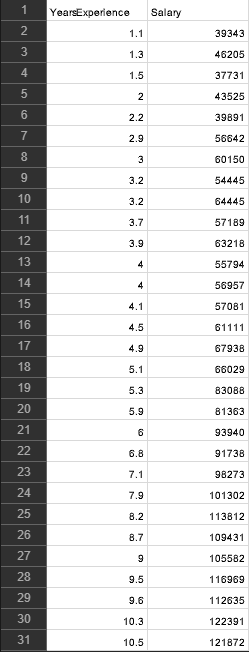
Experience vs Salary
#Importing the libraries
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
#Importing the dataset
dataset = pd.read_csv('Salary_Data.csv')
#데이터 이름인 첫줄 제외
X = dataset.iloc[:, :-1].values
y = dataset.iloc[:, -1].values
#Splitting the dataset into the Training set and Test set
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state = 0)
#Training the Simple Linear Regression model on the Training set
from sklearn.linear_model import LinearRegression
regressor = LinearRegression()
regressor.fit(X_train, y_train)
#Predicting the Test set results
y_pred = regressor.predict(X_test)test_size = 0.2는 위의 데이터가 총 30개이니 test는 30*0.2=6 즉, 6개를 test set에 넣겠다는 뜻이다.
fit()함수는 추후 많은 모델에서 사용할 입력 데이터의 형태에 맞춰 데이터를 변환하기 위한 사전 구조를 맞추는 함수이다.
선형회귀 모델 Training이 끝났고 결과를 시각화하여 모델 정확도를 확인하자.
matplotlib.pyplot 라이브러리의 함수를 이용하면 그래프를 쉽게 그려서 시각화할 수 있다.
#Visualising the Training set results
plt.scatter(X_train, y_train, color = 'red')
plt.plot(X_train, regressor.predict(X_train), color = 'blue')
plt.title('Salary vs Experience (Training set)')
plt.xlabel('Years of Experience')
plt.ylabel('Salary')
plt.show()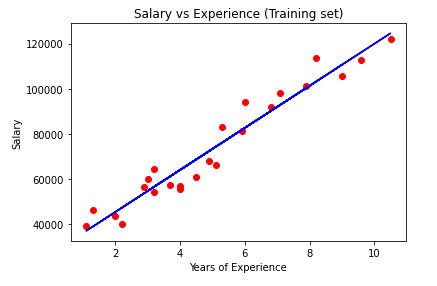
#Visualising the Test set results
plt.scatter(X_test, y_test, color = 'red')
plt.plot(X_train, regressor.predict(X_train), color = 'blue')
plt.title('Salary vs Experience (Test set)')
plt.xlabel('Years of Experience')
plt.ylabel('Salary')
plt.show()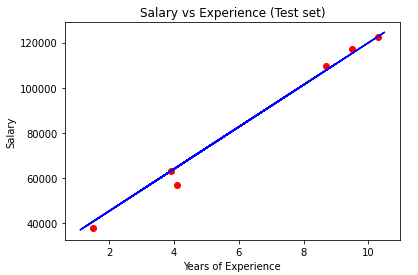
간단하게 matplotlib.pyplot 모듈의 함수에 대해서 알아보면 scatter()함수는 원하는 좌표를 점으로 표현할 수 있다.
plot()함수는 곡선을 그릴수 있는 함수인데 역기서는 단순 선형 회귀 모델이므로 직선으로 표현된 것을 알 수 있다.
728x90
'Drawing (AI) > MachineLearning' 카테고리의 다른 글
| AI스터디자료-1주차 (0) | 2023.02.11 |
|---|---|
| Udemy - 머신러닝의 모든 것 (Multiple Linear Regression-1) (0) | 2023.02.03 |
| Udemy - 머신러닝의 모든 것 (Intro+Data Preprocessing) (0) | 2023.01.15 |
| TensorFlow 2.0 (Operations) (0) | 2023.01.14 |
| TensorFlow 2.0 (Basic) (0) | 2023.01.09 |


