Abstract
Lukas Brunke et al. CoRL 2024 workshop (SAFE-ROL)

인간 중심 환경에서 안전한 상호작용을 보장하기 위해서는 로봇이 사람이 상식으로 여기는 제약(예: 전자 기기 위로 물이 담긴 컵을 움직이지 않기)을 이해하고 준수해야 한다. 본 연구에서는 로봇 입력에 대해 의미적으로 정의된 제약(공간적 관계, 동작 방식, 자세)과 기하학적으로 정의된 제약(환경 충돌, 로봇 자체 충돌)을 함께 certificate하는 semantic safety filter를 제안한다. 시맨틱 맵을 구성하고 대형 언어 모델을 활용해 의미적으로 안전하지 않은 조건을 추론하며 이를 control barrier certification 기법을 통해 안전한 동작으로 연결한다. 이를 통해 단순한 충돌 회피를 넘어, 사람이 직관적으로 위험하다고 느끼는 동작(예: 컵을 기울이거나 전자 기기 위로 이동)을 필터링할 수 있다. teleoperated tabletop manipulation tasks과 pick-and place 작업에서 실험을 진행해, 의미적 제약까지 통합한 안전성 보장을 성공적으로 입증하였다.
Introduction
로보틱스에서 안전은 핵심적인 문제로 오랜 기간 다양한 관점에서 연구되어 왔다. 특히 safety-critical control 분야에서는 로봇이 특정 safe set 안에서만 동작하도록 보장하는 것을 목표로 한다. 이를 위해 최근에는 안전하지 않은 제어 입력을 식별하고, 이를 minimally invasive을 통해 안전한 입력으로 바꾸는 다양한 안전 필터들이 제안된다. 그러나 이들 필터는 주로 충돌 회피와 같은 기하학적으로 명시된 제약에만 초점을 맞추는 경향이 있다.
인간 중심 환경에서 로봇이 작동하려면 단순 물리적 충돌 회피에 그치지 않고 common sense을 반영한 제약도 고려해야 한다. 예를 들어 물이 담긴 컵을 전자 기기 위로 옮기는 것이 위험하다는 점, 혹은 컵을 기울이지 말아야 한다는 점 등, semantic 정보를 이용해 ‘위험 상황’을 정의할 필요가 있다. 본 연구는 이처럼 보이지 않는 위험 요인을 포함하여 3차원 환경 이해와 LLM을 결합해 시맨틱 제약을 추론하고 준수하게 하는 semantic safety filter를 제안한다.
제안된 프레임워크는 3D 환경 맵으로부터 얻은 metric-semantic 정보와 LLM의 추론 기능을 활용하여 로봇이 semantic하게 정의된 제약(예: 공간적 관계, 동작 방식, 물체의 자세 등)을 위반하지 않도록 제어한다. 실제 로봇 하드웨어 실험에서는 텔레오퍼레이션과 피킹 앤 플레이스 작업을 통해 이러한 시맨틱 제약을 충족시키는 모습을 보인다. 이를 통해 단순 충돌 방지를 넘어 인간이 일상적으로 고려하는 위험(예: 물이 들어 있는 컵을 기울이는 행위)을 인지하고 안전하게 동작하도록 로봇 제어를 고도화한다.
Main Contribution
1. 3D 환경 지도에서 얻은 metric-semantic information과 LLM의 추론 능력을 활용하여 안전한 로봇 조작을 수행하는 시맨틱 CBF 안전 필터 프레임워크를 제안한다.
2. 환경 인식과 추론을 기반으로 세 가지 유형의 시맨틱 제약을 정의한다.
(i) 공간적 관계(spatial relationship) 제약 (예: 촛불을 풍선 아래로 움직이지 말 것)
(ii) 행동(behavioral) 제약 (예: 칼을 들고 있을 때는 더 느리거나 조심스럽게 움직일 것)
(iii) 자세(pose)에 기반한 제약 (예: 물이 담긴 컵은 쏟아지지 않도록 기울이지 말 것)
3. Teleoperation과 pick-and-place manipulation 작업에서 실제 하드웨어 실험을 통해 제안 프레임워크를 검증한다. 실험 결과, 본 프레임워크가 시맨틱 제약을 만족하는 데 있어 높은 효능을 보이며 고수준의 시맨틱 이해를 안전한 의사결정에 통합할 잠재력을 지님을 확인하였다.
Related works
A. Safe Robot Manipulation
로봇 제어에서 안전은 주로 상태 제약을 위반하지 않는 것을 의미한다. Set invariance은 이러한 안전을 보장하기 위한 핵심 개념으로, 초기 상태가 안전 집합에 있으면 제어 입력에 따라 그 집합 안에서만 움직이도록 유지한다. 전통적으로는 충돌이 없는 경로를 생성하고 이를 고정밀 추적 제어로 실행함으로써 안전을 달성한다. 최근에는 Contol Barrier Function, Hamilton-Jacobi-reachability analysis, predictive control 등의 안전 필터가 모듈형 솔루션으로 제안되고 있다. 그러나 대부분 기하학적 제약에 집중하며 semantic 제약을 반영하는 연구는 부족하다.
B. Semantic 3D Representation and Spatial Reasoning
로봇의 작업 환경을 semantic하게 표현하기 위한 연구는 object detection and segmentation 기법의 발전과 함께 크게 진전되었다. 이를 통해 3D 맵핑과 SLAM에 semantic 정보를 결합해서 instance 혹은 object 레벨의 일관된 지도를 구성할 수 있다. 또한 LLM과 VLM의 발전으로 open-vocabulary object detection이 가능해져 사전에 정의되지 않은 물체까지 식별할 수 있게 되었다. 이렇게 추출된 시맨틱 정보는 3D 장면 그래프와 같은 스파스 표현으로도 활용할 수 있다. 그러나 안전 제어와 같은 로봇 의사결정 영역에서 시맨틱 정보를 충분히 이용한 사례는 아직 드물다.
C. Language-Conditioned Robot Decision-Making
최근 CLIP, GPT 등 foundation model의 등장은 언어에 기반한 로봇 의사결정을 크게 발전시켰다. 언어를 통해 물체를 인식, 매칭하거나 로봇 조작 및 내비게이션을 자연스럽게 제어할 수 있다. 작업 계획이나 코드 작성, 행동 검증 등에서도 LLM과 VLM의 능력이 적극 활용되고 있다. 특히 오픈 보캐블러리 기능을 통해 사전에 정의하지 않은 객체나 상황에도 유연하게 대응할 수 있다는 점이 중요하다. 본 연구 역시 이러한 언어 기반 추론 기능을 통해 semantic하게 정의된 위험 조건을 자동으로 식별하고자 한다.
Problem Statement
본 연구에서는 평평한 테이블 위에 물체들이 놓여 있는 환경에서 robot manipulator가 teleoperation 명령 또는 상위 레벨 motion policy에 따라 tabletop manipulation 상황을 고려한다. 일반적으로 텔레오퍼레이션 입력이나 모션 폴리시는 안전하지 않을 수 있다. 우리의 목표는 language-aided safety filter를 설계하여 semantic하게 정의된 제약 C_ (공간적 관계, behavior 기반, pose 기반 제약)과 기하학적으로 정의된 제약(환경 충돌 C_, 로봇 자체 충돌 C_) 모두에 대해 안전 운용을 보장하는 것이다. 우리는 시스템이 장면을 촬영한 RGB-D 영상 {I_과 대응하는 카메라 포즈 를 통해 환경을 perceive하고 reason한다고 가정한다. 이때 는 frame index이다. Semantic constraints이라는 용어는 문헌에 따라 시나리오 의존적 정의(예: 로봇 손에 대한 grasp 타입, 궤적 제약 등)를 갖는다. 본 논문에서는 로봇 매니퓰레이터의 end effector에 적용되는 task-space constraints 중 ‘high-level semantic concepts’에 관련된 것들을 시맨틱 제약이라고 칭한다.(“물이 담긴 컵을 전자 기기 위로 옮기지 않기”나 “컵을 과도하게 회전시키지 않아 내용물을 쏟지 않기”) 전형적인 충돌 회피 제약과 달리 Semantic적으로 안전하지 않은 상태는 반드시 visible 상태(물리적으로 객체가 점유하는 부분)일 필요가 없으며 잠재적으로 위험한 구간도 인식을 해야한다. semantic 제약을 구성하려면 조작 대상 물체와 환경에 대한 높은 수준의 이해가 필요하다. 본 연구에서는 perception input, robot system model, LLM을 활용하여 semantic 안전을 보장하면서 동시에 self-collision 및 environment collision을 피할 수 있는 safety filter를 설계한다.
Methodology
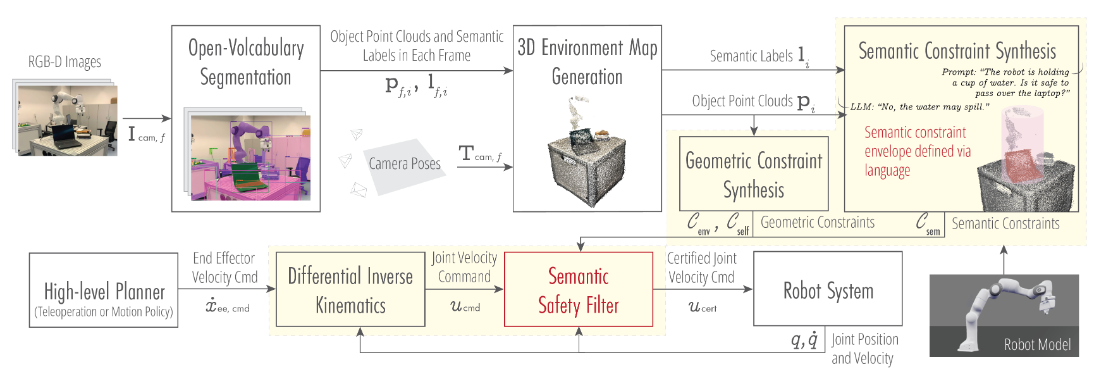
위 figure가 이 논문 architecture 의 핵심을 잘 설명해준다.
1. Perception: 로봇이 RGB-D 등의 시각 데이터를 받아 물체들을 segmentation하고 각 물체의 semantic label과 point cloud를 획득한다.
2. LLM을 통한 semantic 추론: Semantic label 목록과 로봇이 조작할 물체 정보를 LLM에 입력하여 위험한 Spatial, Behavioral, Pose 관련 constraint을 추론한다(Semantic context S 생성).
3. Safe Set 정의: Semantic label과 point cloud 정보를 결합하여 로봇이 위배해서는 안 되는 제약을 safe set 형태로 설정한다.
4. Parameter 조정: 컵을 기울이지 않도록 end effector 회전 각도를 제한하거나 예민한 물체는 천천히 접근하도록 하는 등 semantic context에 맞춰 safe filter의 parameter를 동적으로 업데이트한다.
5. 실시간 safe filtering: High-level 명령이나 teleoperation input을 differential inverse kinematics로 관절 속도(u_cmd)로 변환하고 semantic safe filter로 확인된 최종 명령만 로봇에 전달된다.
3D Environment Map Generation
Semantic constraints synthesis는 3D environment representation에 의존된다. 왜냐하면 3D environment representation이 downstream planning과 control task를 위한 semantic reasoning을 가능케 하기 때문이다. 이 때문에 safety filter를 생성하기 위해 language-embedded representation approach가 필요하여 Conceptgraph나 OpenMask3D와 같은 3D environment의 open-vocabulary object-level representation을 사용한다.
해당 모듈의 입력은 RGB-D 프레임들의 집합 {I_cam,f}과 각 프레임에 대한 카메라 포즈 이다. 우선 RGB-D 이미지를 segmentation하고 이렇게 얻어진 각 segmentation mask를 embedding한다. 그 결과 각 프레임 f에서 객체 i에 해당하는 분할된 포인트 클라우드 p_f,i와 해당 객체의 agnostic embedding f_f,i가 생성된다. 이후에 segmentation된 object-level의 point cloud p_f,i와 이에 대응하는 카메라 포즈 T_cam,f 그리고 feature vector f_f,i를 이용하여 geometric과 semantic similarities에 기반하여 multi-view에서 객체를 연결한다. 프레임별 정보가 누적되어 3D 환경에 대한 일관된 객체 수준의point-cloud 표현이 형성된다.
3D map 생성의 출력은 장면에 존재하는 각 객체에 대해 point cloud(p_i)와 embedding(f_i) 두 가지 정보를 갖춘 형태이다. Conceptgraph나 OpenMask3D에서 사용한 방법과 유사하게 해당 아키텍쳐에서 embedding을 각 객체 클래스 label l_i에 매핑한다. 이때 이는 사전에 정의한 객체 클래스 목록을 임베딩한 뒤 가장 유사도가 높은 쌍을 해당 객체의 label로 선택함으로써 이루어진다.
Semantic Constraint Synthesis
로봇이 조작 중인 object와 scene 내 다른 물체들 간에 존재할 수 있는 세 가지 유형의 semantic safety를 구분한다.
(i) 공간적(spatial) 관계 기반으로 안전하지 않은 경우 (예: ‘풍선을 아래로 촛불을 옮기지 말 것’)
(ii) 로봇이 들고 있는 물체 및 주변 환경에 따라 엔드 이펙터(end effector)의 속도 등을 제한하는 행동(behavioral) 제약 (예: ‘칼을 들고 있을 때는 더 느리게, 더 조심스럽게 움직일 것’)
(iii) 조작 대상 물체에 따라 엔드 이펙터 자세(pose)를 제한하는 제약 (예: ‘물이 담긴 컵은 쏟아지지 않도록 똑바로 유지’)
이러한 Semantic constraint들은 object- and scene-dependent이므로 이를 하나하나 전부 지정하는 것은 매우 번거로울 수 있다. 따라서 해당 논문에서는 LLM을 활용해 Semantic constraint들을 자동으로 synthesize한다.

1) Spatial Relationship Constraints
Semantic constraint set들은 미분 가능한 함수의 super-level set들로 parameterized된다. CBF certification framework는 이 ‘semantically safe set’의 positive invariance을 보장한다. 즉 초기 상태가 semantic constraint들을 위반하지 않으면 미래 어느 시점에도 그 제약을 위반하지 않는다는 것이다.
예를 들어 S_r(o)내의 각 쌍 (l_i, r_i) (장면의 물체 l_i와 위험 관계 r_i)에 대해 해당 물체 l_i의 포인트 클라우드 p_i와 그 관계 r_i를 바탕으로 미분 가능한 함수 gi: R^3를 정의한다. 이는 로봇의 end effector가 침범하면 안 되는 공간을 표현한다. Semantic constraint set은 아래와 같이 표현할 수 있다.
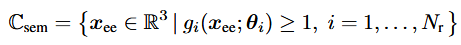
여기서 x_ee=[x,y,z]^T는 end effector 위치이고 θ_i는 객체 포인트 클라우드 p_i와 관계 r_i에 의해 결정되는 파라미터다. 예를들어 ‘laptop, above’ 관계에서는 superquadric을 이용해 g_i를 미분 가능한 근사치로 정의한다. Superquadric은 3D 공간에서 타원체나 직육면체등을 일반화한 형태이다. 지수나 axes scale등을 조정해 다양한 3차원 형상을 근사할 수 있다.
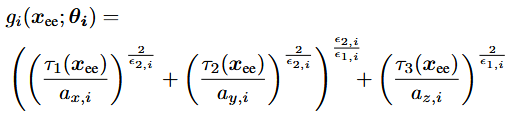
이 되도록 정의하면 이 영역 바깥에 있으면 안전하다는 의미가 된다.
laptop에 대해 above라는 공간적 관계를 표현하기 위해 노트북의 포인트 클라우드를 z축 방향으로 확장하고 원본+확장된 포인트 클라우드의 합집합에 맞춰 superquadric fitting을 진행한다. ‘under’, ‘around’ 등 다른 공간 관계에도 유사하게 슈퍼쿼드릭을 정의한다.
이로써 시맨틱 제약을 유지하려면 엔드 이펙터가 이 미분 가능한 함수의 안전 구역 g_i(x_ee;θi)≥1을 침범하지 않아야 한다. Forward kinematics을 통해 이를 관절 공간 q에서 표현하면 아래와 같이 된다.
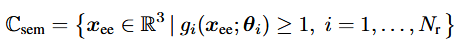
2) Behavioral Constraints
Behavioral constraint는 CBF(Control Barrier Function)의 time derivative에 대한 contraints를 이용하여 구현하였다. Constraint는 아래와 같다.
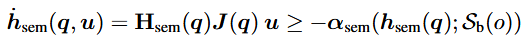
여기서 H_sem(q)은 아래와 같이 정의되고,
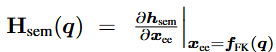
직관적으로 보자면 이 조건은 α_ 설계를 통해 로봇 시스템이 semantic safety boundary에 얼마나 빠르게 접근할 수 있는지를 제한함으로써 h_으로 정의되는 제약이 항상 만족되도록(집합 C_이 forward invariant하도록) 보장한다.
S_b(o)로부터 나온 행동적 시맨틱 제약 b_j에 맞춰 클래스 K_ 함수를 설계함으로써 로봇이 라벨 l_j인 객체의 안전 경계에 더 천천히 접근하도록 하여 원하는 수준의 주의(caution)를 보여주게 한다. 예를 들어 b_j=caution인 경우 α_sem,의 기울기(steepness)를 낮춤으로써 α_sem,j(⋅;caution)=α_sem,cautious,j(⋅)와 같이 표기한다. 해당 reduction은 positive h_에 대해 원래 α_보다 더 작은 값을 갖는 K_ 함수를 택함으로써 구현할 수 있다. 가장 간단한 생성 방법은 α_에 1보다 작은 positive scalar를 곱해주는 것이다.
3) Pose Constraints
Pose constraint는 S_T(o)={rotation locked}일 경우 활성화된다.
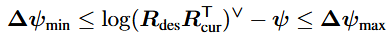
여기서 R_는 end effector의 desired rotation(물체를 들어올릴 때의 초기 자세), R_은 end effector의 current rotation, ψ=Jo(q)uΔt는 다음 시점(t+Δt)에서 end effector가 회전할 것으로 예측되는 값이며 J_o(q)는 joint velocity를 end effector angular velocity로 mapping하는 Jacobian이다.
기호 (·)∨는 skew-symmetric 연산자[(·)∧]의 역연산을 의미한다. 그리고 Δψmin과 Δψmax는 허용 가능한 회전 오차 범위이다. 이 제약을 softened 형태로 적용하여 infeasibility상태가 되어 제어가 불가능해지는 사태를 줄인다. 구체적으로는 아래와 같은 objective function 항을 통해 완화된 pose constraint를 표현한다.
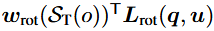
여기서 는 semantic context T in S_T에 따라 결정된다. 만약 T=free rotation(로봇이 물체를 들고 있지 않을 때)라면 w_rot=0이 되어 end effector에 rotation constraint가 걸리지 않는다. 그러나 (물이 담긴 컵을 조작해 쏟아짐을 방지)인 경우 w_가 되어 rotation을 줄이려는 cost를 추가한다.
벡터 L_는 다음과 같은 형태이며
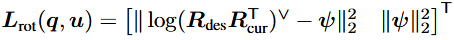
첫 번째 항은 다음 시점에서의 predicted orientation과 end effector의 desired orientation간의 차이를 줄이는 데 사용되고 두 번째 항은 end effecor가 과도하게 빠르게 회전하지 않도록 하여 perturbation이 줄도록 하는 것이다.
Geometric Constraints
Semantic constraints외에도 로봇은 geometric constraints를 준수해야 하는데 여기에는 environment-collision과 self-collision 제약이 포함된다. 이러한 추가 제약들을 두 개의 CBF 벡터인 h_와 h_에 통합한다. Environment-collision constraint는 point cloud p_i에 맞춰 superquadric을 fitting한 뒤 이를 기반으로 CBF를 정의한다. Self-collision constraint는 로봇 몸체를 따라 여러 개의 spherical CBF를 배치함으로써 formulate한다.
Semantic Safety Filter Formulation
Semantic constrait C_과 semantic context 집합 S가 주어졌을 때 목표는 잠재적으로 안전하지 않은 명령을 수정하는 것이다.
End effector의 원하는 속도 명령 을 보내면 differential inverse kinematics을 통해 이 명령이 joint 속도 명령 u_로 변환된다. 이어 Semantic safety filter는 semantic 및 geometric constraint를 만족하면서도 u_에 가장 가깝게 매칭되는 certificate 입력 u_를 계산한다.
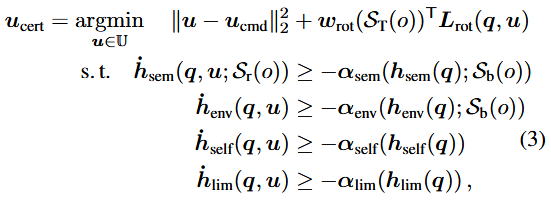
Experiments
Real-world 실험에서 Franka Emika사의 FR3 robot manipulator를 colsed-loop 구조로 구성된 semantic safety filter와 함께 사용하여 non-expert 사용자가 내리는 명령이나 motion policy에서 발생할 수 있는 잠재적으로 위험한 제어 입력을 막도록하며 성능 평가를 진행했다.
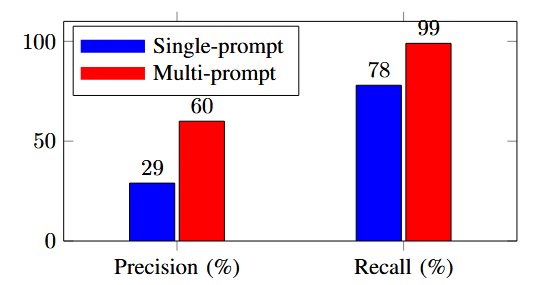
Multi-prompt strategy가 single-prompt method보다 성능이 좋음
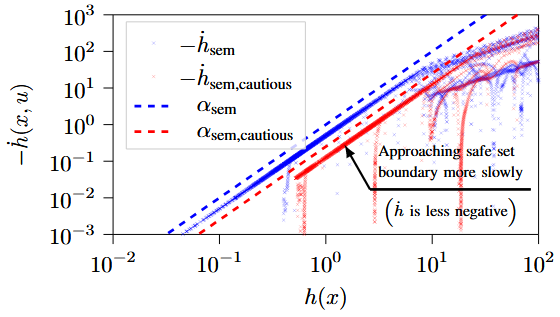
cautious 0에서는 negative time derivatives이 빨간색 점선 아래를 유지하여 CBF 조건을 만족한다. 이는 α_sem,cautious가 α_sem보다 더 작기 때문에 엔드 이펙터가 경계에 더 천천히 다가감을 의미한다.

(1) baseline without a safety filter (2) safety filter accounting for geometric constraints (3) semantic safety filter
세가지를 비교한 표이다.
세 가지 장면과 다섯 가지 조작 사례(네 개의 물체 + 빈 손 상태)를 대상으로 각각 다섯 개의 텔레오퍼레이션 궤적을 수행하여 각 방법마다 총 40개의 궤적을 얻었다.
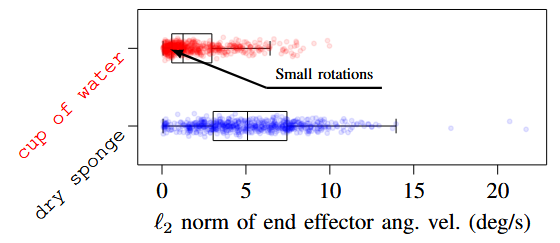
로봇이 책이 놓인 장면에서 물이 담긴 컵(또는 건조 스펀지)을 들고 있을 때 rotate minimization이 active된 경우와 비활성inactive된 경우를 테스트한다. 물컵을 들고 있는 경우의 분포는 더 작은 angular velocity쪽으로 치우쳐 있으며(회전 최소화가 활성됨), 비활성(파란색) 상태에 비해 활성(빨간색) 상태에서는 엔드 이펙터의 회전이 전반적으로 더 줄어든다는 것을 보여준다.
Conclusion
3D 맵에 물리적으로 나타나지 않을 수 있는 의미적 제약도 safety filter로 구현해 실시간으로 로봇 동작을 제어. 기존 충돌 회피와 로봇 자체 관절 제약, semantic 제약 등 모든 안전 요구사항을 하나의 필터로 통했다.

실제 로봇 환경(teleoperation, pick-and-place 등)에서 실험을 통해 효과적임을 입증하였다. 형식적 안전 보장을 유지하면서 semantic 정보를 활용할 수 있음을 보여준 첫 사례로 로봇이 사람과 같은 수준의 ‘common sense’를 지향하는 중요한 진전을 이룬 것으로 평가할 수 있다.



