Florence-2
Microsoft에서 아주 최근에 발표한 프롬프트 기반 Vision-Langauge foundation모델이다. 굉장히 general한 task에 대해서 높은 수행능력이 있다는 것에서 의의가 있다.

FLD-5B
Florence-2의 특장점 중 하나는 작업 지시로 text prompt를 받아 원하는 결과를 텍스트 형식으로 생성하는 능력이다. 이러한 multi-task에 대한 수행능력은 대규모의 고품질 annotated 데이터가 필요하며, 이를 위해 FLD-5B 데이터셋이 개발되었다. 이 데이터셋은 1억 2천 6백만 개의 이미지에 대한 54억 개의 종합적인 시각 주석을 포함하며, 자동 데이터 엔진을 사용하여 종합적인 시각 주석을 생성하는 방식으로 개발되었다. 데이터 엔진은 핵심적인 두 가지 module이 존재한다.
Automated Annotation Module: 특화된 모델들이 협력하여 자동으로 이미지를 labeling한다.
Iterative Refinement Module: Auto label은 잘 훈련된 기초 모델을 사용하여 반복적으로 정제 및 필터링된다. 이 과정은 데이터셋의 품질과 정확성을 높인다.
Architecture
Vision Encoder: DaViT를 사용하여 입력 이미지를 평탄화된 시각 토큰 임베딩으로 처리한다.
Multi-modality encoder decoder: 시각 및 언어 토큰 임베딩을 처리하는 트랜스포머 기반 아키텍처를 사용한다. 이를 통해 Image input과 text input의 원활한 통합이 가능하다.
Optimization objective: 모든 task에 대해 standard langauge modeling과 cross-entropy loss를 사용하여 일관된 최적화를 보장한다.
Inference
import torch
from transformers import AutoProcessor, AutoModelForCausalLM
from PIL import Image
import requests
# GPU 설정
device = torch.device("cuda:2") # GPU사용 상태 확인(nvidia-smi)하고 GPU 선택
model_id = 'microsoft/Florence-2-large'
model = AutoModelForCausalLM.from_pretrained(model_id, trust_remote_code=True).eval().to(device)
processor = AutoProcessor.from_pretrained(model_id, trust_remote_code=True)
def run_example(task_prompt, text_input=None, image=None):
if text_input is None:
prompt = task_prompt
else:
prompt = task_prompt + text_input
inputs = processor(text=prompt, images=image, return_tensors="pt")
generated_ids = model.generate(
input_ids=inputs["input_ids"].to(device),
pixel_values=inputs["pixel_values"].to(device),
max_new_tokens=1024,
early_stopping=False,
do_sample=False,
num_beams=3,
)
generated_text = processor.batch_decode(generated_ids, skip_special_tokens=False)[0]
parsed_answer = processor.post_process_generation(
generated_text,
task=task_prompt,
image_size=(image.width, image.height)
)
return parsed_answer
url = "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/tasks/car.jpg?download=true"
image = Image.open(requests.get(url, stream=True).raw)
task_prompt = '<DETAILED_CAPTION>'
result = run_example(task_prompt, image=image)
print(result)huggingface를 이용하여 inference해보았다. task_prompt를 바꿔가며 inference해보니 task에 맞는 결과가 잘 출력되었다.
# Using <CAPTION> task_prompt
{'<CAPTION>': '\nA green car parked in front of a yellow building.\n'}
# Using <DETAILED_CAPTION> task_prompt
{'<DETAILED_CAPTION>': '\nThe image shows a blue Volkswagen Beetle parked in front of
a yellow building with two brown doors, surrounded by trees and a clear blue sky.\n'}
Object Detection도 수행을 해보았다.
task_prompt = '<OD>'
results = run_example(task_prompt, image=image)
def plot_bbox(image, data):
# Create a figure and axes
fig, ax = plt.subplots()
# Display the image
ax.imshow(image)
# Plot each bounding box
for obj in data:
# Unpack the bounding box coordinates
x1, y1, x2, y2 = obj['bbox']
label = obj['label']
# Create a Rectangle patch
rect = patches.Rectangle((x1, y1), x2-x1, y2-y1, linewidth=1, edgecolor='r', facecolor='none')
# Add the rectangle to the Axes
ax.add_patch(rect)
# Annotate the label
plt.text(x1, y1, label, color='white', fontsize=8, bbox=dict(facecolor='red', alpha=0.5))
# Remove the axis ticks and labels
ax.axis('off')
# Show the plot
plt.show()
plot_bbox(image, results['<OD>'])
인터넷의 랜덤 데이터에 inference를 진행해보았다.

위 이미지에 대해서 아래와 같이 기대보다 훨씬 좋은 성능의 Object detection 성능을 보여줬다.
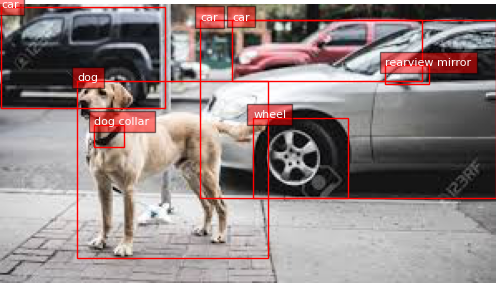
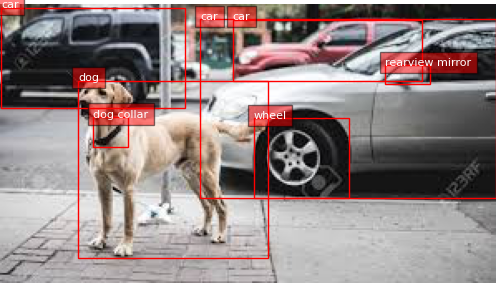
Base model을 사용해도 충분히 좋은 성능이 나오는 것을 볼 수 있다.
Fine-tuning
Downstream task에 fine-tuning하여 적용하니 해당 task에 특화된 모델보다도 좋은성능이 나오는 것을 확인할 수 있다.
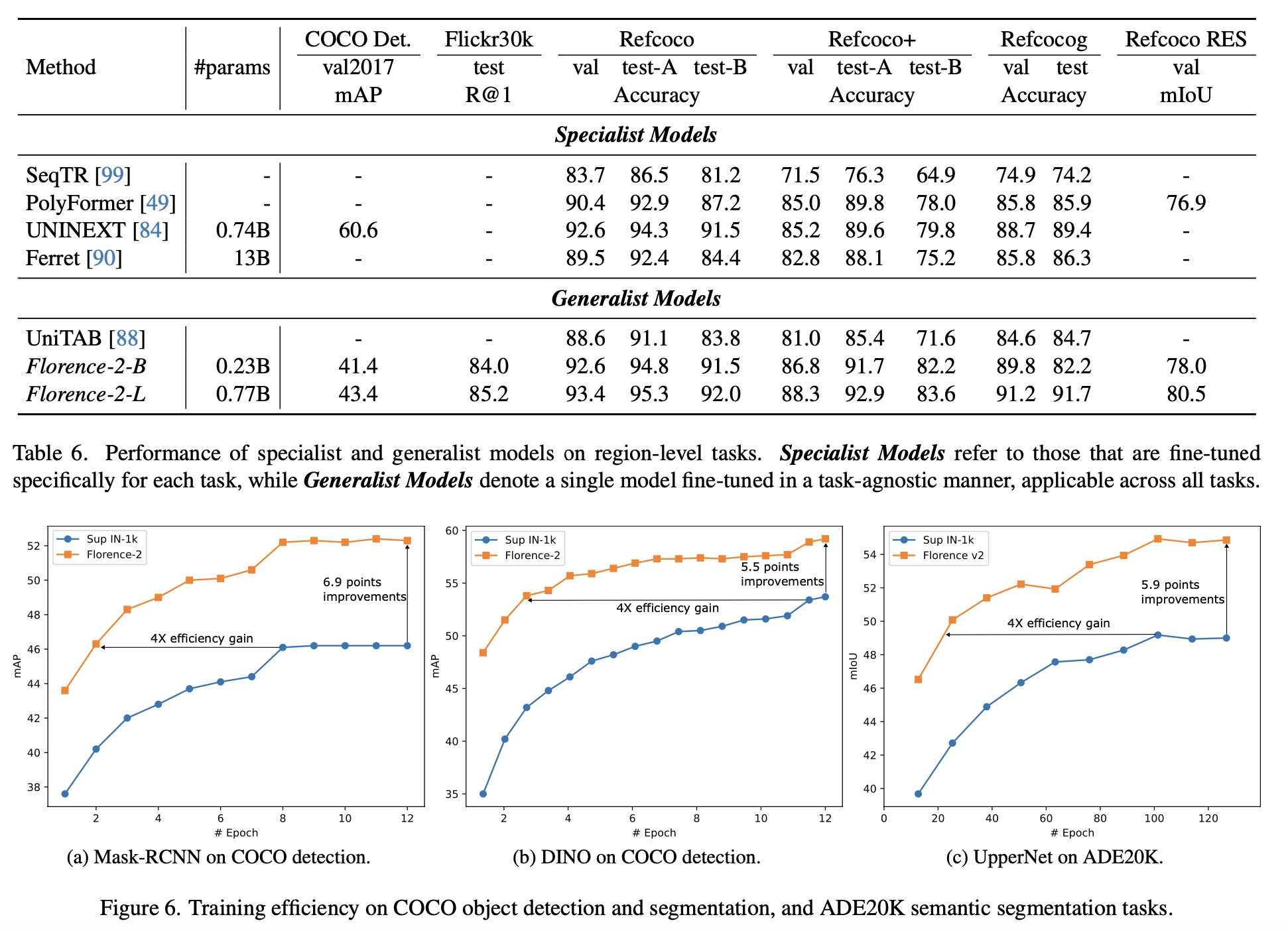
추가로 VQA (Visual Question Answering) task에 대해서 fine-tuning을 한 최근 내용을 살펴보자. 우선 기본 모델에 그대로 VQA task를 zero-shot으로 수행해보기 위해서 "<VQA>", "<vqa>", and "<Visual question answering>"와 같이 prompt를 넣어줘도 제대로된 결과를 출력해내지 못하는 것이 확인 되었다.
Low resource에서 학습시켜보기 위해 비전 인코더를 freeze 시키고, Colab에서는 A100 GPU 하나로 배치 크기 6을 사용하거나 T4로 배치 크기 1을 사용하면 되는 것을 확인했다고 하고 해당 fine-tuning모델 저자는 배치 크기 64로 8개의 H100 GPU가 장착된 클러스터에서 70분 동안 훈련을 진행하여 fine-tuning했다고 한다.

아래는 데모 화면이다.
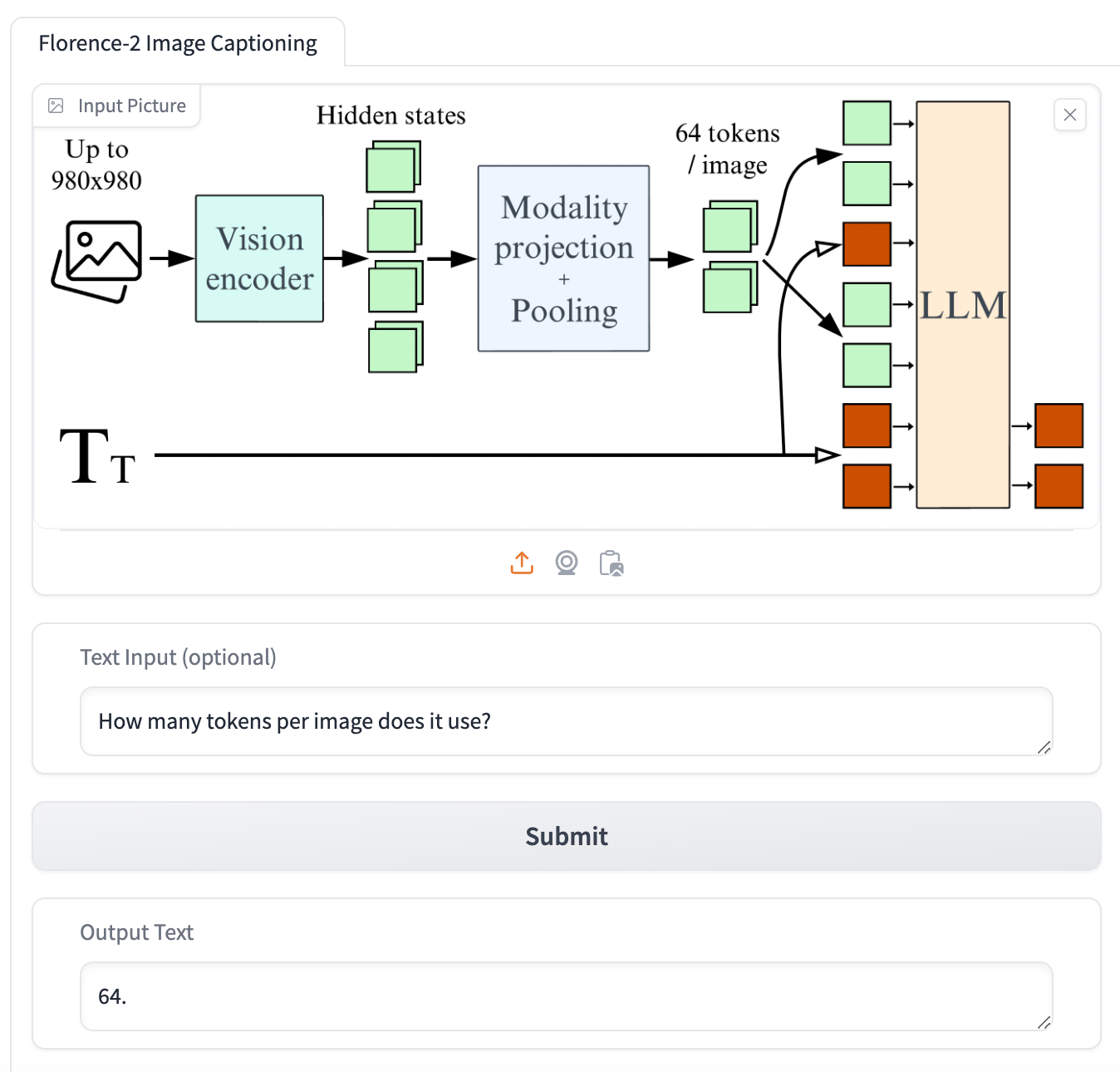
이미지당 몇개의 토큰을 이용하냐는 질문에 그림과 일치하게 64개 라고 답하는 것을 볼 수 있다.
'Coloring (Additional Study) > LAB research' 카테고리의 다른 글
| Building Detection - test result (7/3) (0) | 2024.07.04 |
|---|
