728x90
Tensorflow
Machine Learning용 E2E 오픈소스 플랫폼이다.
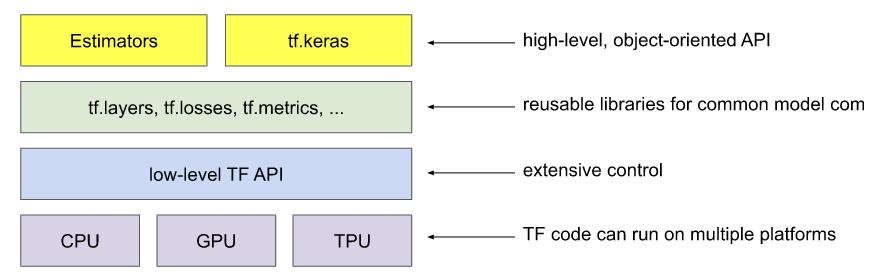
Tensorflow API는 하위 수준 API를 기반으로 하는 상위 수준 API를 사용하여 계층적으로 정렬된다.
ML 연구원 수준에서는 하위수준의 API를 사용하여 새로운 머신러닝 알고리즘을 만들고 연구하지만
우선 내가 따라가고자하는 ML crash course에서는 tf.keras라는 상위수준의 API를 사용하여 진행된다.
Google colab
Google colab을 이용하여 NumPy와 pandas라는 오픈소스에 대한 학습을 진행하는 것이 기본 과정이다.
Google colab은 google colaboratory의 줄임말로 Jupitor Notebook 같은 브라우저에서 Python 스크립트를 작성하고 실행시켜볼 수 있는 기능이다. 그러나 실행 내용과 코드를 기록하기 위해 가능한 내용은 VScode를 이용하고자한다.
이를 이용하여 학습할 내용들인 NumPy는 배열 표현과 선형 대수 연산을 단순화하는 오픈소스이고
pandas는 메모리에서 데이터 세트를 쉽게 나타낼 수 있는 방법을 제공하는 오픈소스이다.
NumPy
Numpy의 기초적인 기능들을 실행 시켜봤다.
import numpy as np
#1차원 배열
one_dimensional_array = np.array([1.2, 2.4, 3.5, 4.7, 6.1, 7.2, 8.3, 9.5])
print(one_dimensional_array)
#2차원 배열
two_dimensional_array = np.array([[6, 5], [11, 7], [4, 8]])
print(two_dimensional_array)
#범위 설정하여 정수열 return
sequence_of_integers = np.arange(5, 12)
print(sequence_of_integers)
#범위와 갯수를 설정하고 random 정수값 return
random_integers_between_50_and_100 = np.random.randint(low=50, high=101, size=(6))
print(random_integers_between_50_and_100)
#0과 1사이의 random한 소수를 설정한 갯수만큼 return
random_floats_between_0_and_1 = np.random.random([6])
print(random_floats_between_0_and_1)
#연산을 이용하여 2와 3사이의 random한 소수 return
random_floats_between_2_and_3 = random_floats_between_0_and_1 + 2.0
print(random_floats_between_2_and_3)
#연산을 이용하여 150과 300사이의 random한 정수 return
random_integers_between_150_and_300 = random_integers_between_50_and_100 * 3
print(random_integers_between_150_and_300)
다음으로 두개의 단순한 Task를 진행해봤다.
#Task 1: Create a Linear Dataset
# Your goal is to create a simple dataset consisting of a single feature and a label as follows:
# 1. Assign a sequence of integers from 6 to 20 (inclusive) to a NumPy array named feature.
# 2. Assign 15 values to a NumPy array named label such that:
# label = (3)(feature) + 4
import numpy as np
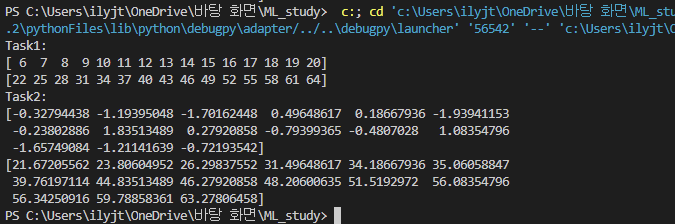
print("Task1:")
feature = np.arange(6, 21)
print(feature)
label = (feature * 3) + 4
print(label)
#Task 2: Add Some Noise to the Dataset
# To make your dataset a little more realistic, insert a little random noise into each element of the label array you already created.
# To be more precise, modify each value assigned to label by adding a different random floating-point value between -2 and +2.
#Don't rely on broadcasting. Instead, create a noise array having the same dimension as label.
print("Task2:")
noise = (np.random.random([15]) * 4) - 2
print(noise)
label = label + noise
print(label)다음 결과를 통해 Task를 제대로 수행하였음을 알 수 있다.
Pandas
pandas의 기초적인 기능들을 실행 시켜봤다.
import numpy as np
import pandas as pd
# 5x2 NumPy array 생성
my_data = np.array([[0, 3], [10, 7], [20, 9], [30, 14], [40, 15]])
# Create a Python list that holds the names of the two columns.
my_column_names = ['temperature', 'activity']
# Create a DataFrame.
my_dataframe = pd.DataFrame(data=my_data, columns=my_column_names)
# Print the entire DataFrame
print(my_dataframe)
# Create a new column named adjusted.
my_dataframe["adjusted"] = my_dataframe["activity"] + 2
# Print the entire DataFrame
print(my_dataframe)
#Pandas provide multiples ways to isolate specific rows, columns, slices or cells in a DataFrame.
print("Rows #0, #1, and #2:")
print(my_dataframe.head(3), '\n')
print("Row #2:")
print(my_dataframe.iloc[[2]], '\n')
print("Rows #1, #2, and #3:")
print(my_dataframe[1:4], '\n')
print("Column 'temperature':")
print(my_dataframe['temperature'])결과
temperature activity
0 0 3
1 10 7
2 20 9
3 30 14
4 40 15
temperature activity adjusted
0 0 3 5
1 10 7 9
2 20 9 11
3 30 14 16
4 40 15 17
Rows #0, #1, and #2:
temperature activity adjusted
0 0 3 5
1 10 7 9
2 20 9 11
Row #2:
temperature activity adjusted
2 20 9 11
Rows #1, #2, and #3:
temperature activity adjusted
1 10 7 9
2 20 9 11
3 30 14 16
Column 'temperature':
0 0
1 10
2 20
3 30
4 40
Name: temperature, dtype: int64다음으로 간단한 Task를 하나 진행해봤습니다.
# Task 1: Create a DataFrame
# Create an 3x4 (3 rows x 4 columns) pandas DataFrame in which the columns are named Eleanor, Chidi, Tahani, and Jason.
# Populate each of the 12 cells in the DataFrame with a random integer between 0 and 100, inclusive.
# Output:
# 1.the entire DataFrame
# 2.the value in the cell of row #1 of the Eleanor column
# Create a fifth column named Janet, which is populated with the row-by-row sums of Tahani and Jason.
my_data = np.random.randint(low=0, high=101, size=(3, 4))
my_column_names = ['Eleanor', 'Chidi', 'Tahani', 'Jason']
my_dataframe = pd.DataFrame(data=my_data, columns=my_column_names)
print(my_dataframe)
print("\nrow #1 of the Eleanor column: %d\n" % my_dataframe['Eleanor'][1])
my_dataframe['Janet'] = my_dataframe['Tahani'] + my_dataframe['Jason']
print(my_dataframe)결과
Eleanor Chidi Tahani Jason
0 5 49 12 70
1 80 22 3 88
2 11 48 71 23
row #1 of the Eleanor column: 80
Eleanor Chidi Tahani Jason Janet
0 5 49 12 70 82
1 80 22 3 88 91
2 11 48 71 23 94Extra Task
#pandas provides two different ways to duplicate a DataFrame:
# Referencing: If you assign a DataFrame to a new variable,
# any change to the DataFrame or to the new variable will be reflected in the other.
# Copying: If you call the pd.DataFrame.copy method, you create a true independent copy.
# Changes to the original DataFrame or to the copy will not be reflected in the other.
# Referencing을 통한 복사
print("Experiment with a reference:")
reference_to_df = df
# 복사한 내용 출력
print(" Starting value of df: %d" % df['Jason'][1])
print(" Starting value of reference_to_df: %d\n" % reference_to_df['Jason'][1])
# modify 진행후에 다시 출력
df.at[1, 'Jason'] = df['Jason'][1] + 5
print(" Updated df: %d" % df['Jason'][1])
print(" Updated reference_to_df: %d\n\n" % reference_to_df['Jason'][1])
# true copy를 통한 복사
print("Experiment with a true copy:")
copy_of_my_dataframe = my_dataframe.copy()
# 복사한 내용 출력
print(" Starting value of my_dataframe: %d" % my_dataframe['activity'][1])
print(" Starting value of copy_of_my_dataframe: %d\n" % copy_of_my_dataframe['activity'][1])
# modify 진행후에 다시 출력
my_dataframe.at[1, 'activity'] = my_dataframe['activity'][1] + 3
print(" Updated my_dataframe: %d" % my_dataframe['activity'][1])
print(" copy_of_my_dataframe does not get updated: %d" % copy_of_my_dataframe['activity'][1])결과
Experiment with a reference:
Starting value of df: 3
Starting value of reference_to_df: 3
Updated df: 8
Updated reference_to_df: 8
Experiment with a true copy:
Starting value of my_dataframe: 7
Starting value of copy_of_my_dataframe: 7
Updated my_dataframe: 10
copy_of_my_dataframe does not get updated: 7
728x90
'Robotics & AI > Google' 카테고리의 다른 글
| Google ML crash course (6) (0) | 2023.02.27 |
|---|---|
| Google ML crash course (5) (1) | 2023.02.25 |
| Google ML crash course (3) (0) | 2022.07.23 |
| Google ML Crash Course (2) (0) | 2022.07.23 |
| Google ML Crash Course (1) (0) | 2022.07.20 |



