Linear Regression
귀뚜라미는 더울수록 우는 횟수가 많아지는 경향이 있다고 한다.
이를 예시로 linear regression의 예시를 보면 다음과 같다.

예상한대로 온도와 우는 빈도가 비례함을 알 수 있고 이 관계가 linear한지 보면

물론 한직선이 모든 점이 통과되지는 않지만 경향성을 본다면 충분히 linear하다고 할 수 있다.
위와 같은 linear한 관계를 식으로 표현하면 다음과 같다.
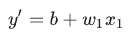
이는 보통 우리가 아는 y=mx+b 또는 y=ax+b라는 일차식을 machine learning model의 표현방식으로 조금 바꾼것이다.
이때 y'은 label(예측되는 output)
b는 bias(y절편, w0로 표현되기도한다)
w1은 weight of feature1 (Weight는 기울기와 같은 개념이다)
x1은 feature(알고있는 input)이다.
여러개의 features를 갖는 경우 다음과 같이 표현할 수 있다.

Training and Loss
Training은 labeled examples로 부터 학습하여 가치있는 weights, bias를 이끌어내도록 하는 과정이다.
Supervised learning에서 machine learning algorithm은 다양한 예시와 시도를 통해 loss를 최소화한 model을 찾고자 한다.
이러한 과정은 empirical risk minimization이라고 한다.
Loss는 정밀하지 못한 예측의 결과물로 하나의 example에서 얼마나 model의 예측이 부정확했는지를 수치화한 것이다.
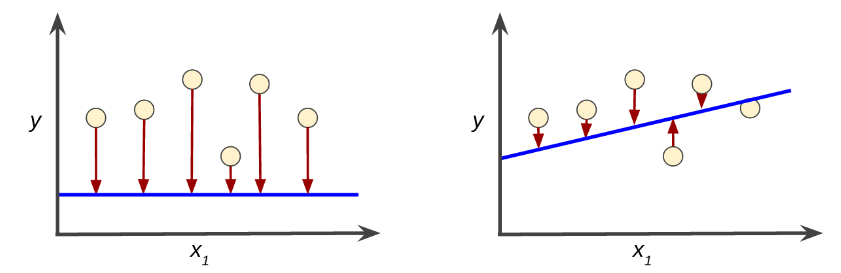
좌측 model: high loss 우측 model: low loss
Squared loss
유명한 loss function으로 L2 loss라고도 불린다.
단순히 loss의 크기를 분석하기 위해 제곱해주는 function이다.
= the square of the difference between the label and the prediction
= (observation - prediction(x))2
= (y - y')2
Mean square loss (MSE)
MSE는 전체 dataset에서 각 example에서의 squared loss의 평균이다.
MSE는 다음과 같이 계산된다.

- (x,y) is an example in which
- x is the set of features (for example, chirps/minute, age, gender) that the model uses to make predictions.
- y is the example's label (for example, temperature).
- prediction(x) is a function of the weights and bias in combination with the set of features x.
- D is a data set containing many labeled examples, which are (x,y) pairs.
- N is the number of examples in D.
'Robotics & AI > Google' 카테고리의 다른 글
| Google ML crash course (6) (0) | 2023.02.27 |
|---|---|
| Google ML crash course (5) (1) | 2023.02.25 |
| Google ML crash course (4) (0) | 2022.12.26 |
| Google ML crash course (3) (0) | 2022.07.23 |
| Google ML Crash Course (1) (0) | 2022.07.20 |



