Optimizer
모델이 학습한다는 것은 loss를 최소화하는 최적화과정을 거치는 것이다. 이전에도 optimizer를 직접 구현하며 optimizer의 종류를 알아보고 성능을 비교해봤지만 너무 중요한 내용이고 수업에 나왔기에 다시 한번 수식과 그 의미를 간단히 정리해보고자 한다.
딥러닝 직접 구현하기 - (Optimizer)
SGD 확률적 경사 하강법(stochastic gradient descent)의 줄임말인 SGD는 현재 상태에서 학습률과 미분값에 비례한 값을 빼서 갱신하는 방식을 이용한다. 위 식을 기반으로 파이썬 클래스로 구현하면 아래
canvas4sh.tistory.com

SGD
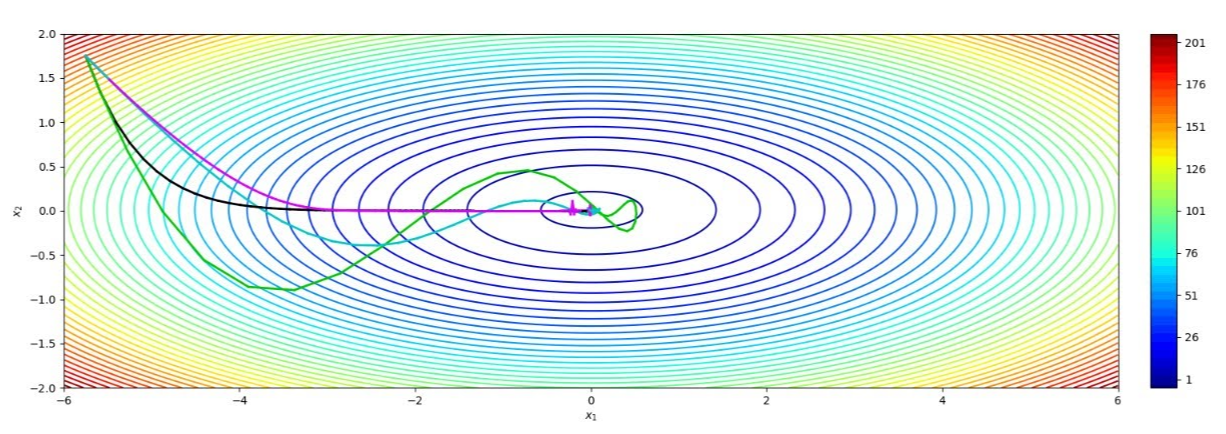
Stochastic Gradient Descent는 확률적 경사 하강법으로 이름 그대로 모든 데이터에 대해서 그래디언트를 계산하는 것이 아니라 랜덤하게 추출된 데이터에 대해서 그래디언트를 계산하고, 경사 하강 알고리즘을 적용하는 방법을 말한다. SGD 방식중 하나인 데이터를 나눠서 그중 일부를 돌아가면서 사용하는 Mini-batch Gradient Descent 알고리즘이 자주 쓰였다. 속도가 좀더 빠르고 나름 최적화가 잘 적용되지만 단점이 명확하여 이후의 개선된 optimizer들이 개발되었다.
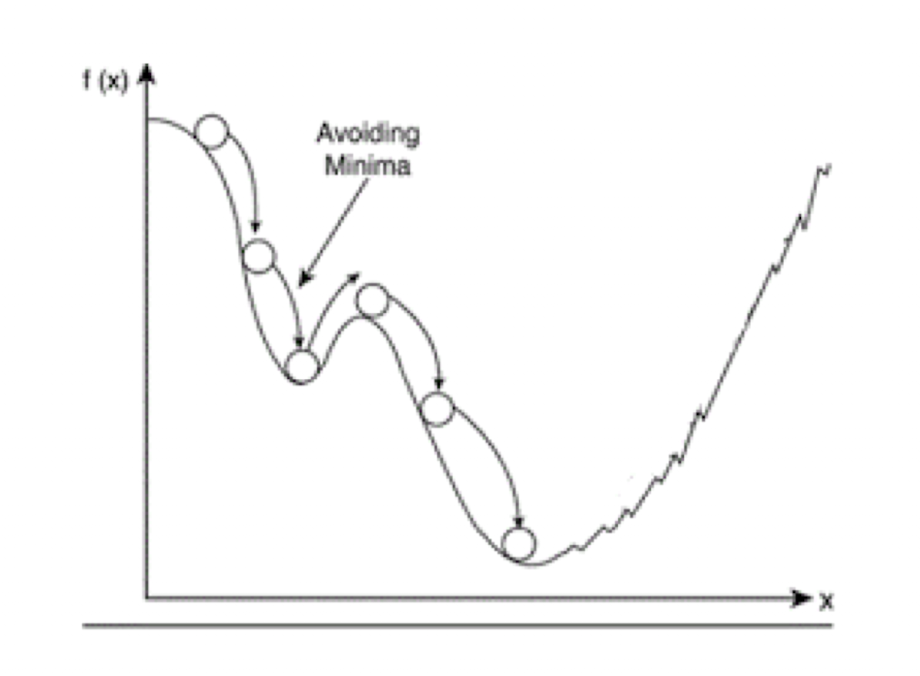
우선 local minimum에 쉽게 빠진다는 것이다. 단순한 convex 형태의 cost function에서는 잘 작동하지만 복잡한 cost function에서는 global minimum을 찾아내는 것이 기적일 정도이다.

다음으로 saddle point에서 학습을 멈추는 문제이다. 아래 그림과 같은 안장점은 미분값이 0이 되는 부분이기 때문에 해당 지점에서 최적화를 끝내버리는 문제가 종종 발생한다.

Momentum
모멘텀은 아래와 같이 local minimum에 빠지는 것을 회피하기 위해 관성을 이용하는 방식이다. Momentum의 사전적 정의는 외부에서 힘을 받지 않는 한 정지해 있거나 운동 상태를 지속하려는 성질이다. 예를 들어, 경사진 곳에서 돌을 굴리면 계속해서 아래로 굴러가려는 성질이다. 이러한 성질을 활용하여 고안된 Momentum은 경사 하강법으로 이동할 때 이동하던 방향으로 빠르게 움직이게 한다.
아래 함수와 같이 이동벡터를 이전 위치에서의 이동벡터와 관성계수를 고려하여 계산된 값과 현재 위치에서의 기울기를 함께 감안하여 갱신되면 그 이동벡터 값 만큼 이동한다.

v(t): t번째 이동 벡터
m: 관성계수(0.9정도)
a: 학습률(learning rate)

위와 같이 현재 이동하던 방향과 기울어진 방향을 고려하여 움직이는 것이다.
Nesterov Accelerated Gradient
Nesterov Accelerated Gradient(NAG)는 기본 Momentum 최적화를 개선한 방법으로, '미리보기' 기능을 통해 더 효과적으로 최적화한다. NAG는 먼저 현재의 모멘텀을 사용해 파라미터를 업데이트할 위치를 미리 본 후, 그 위치에서의 기울기를 계산한다. 이 접근 방식은 파라미터가 과도하게 수정되는 것을 방지하고, 최적화 과정을 더욱 부드럽고 효율적으로 만든다.

Gradient를 계산할때 다음 스텝에서의 상황을 고려하여 구하는 것을 확인할 수 있다.

Adagrad
Adagrad는 adaptive gradient의 약자로 각 파라미터의 업데이트 빈도에 따라 그 파라미터의 학습률을 조정함으로써, 자주 업데이트되는 파라미터의 학습률을 낮추고, 드물게 업데이트되는 파라미터의 학습률을 높인다.
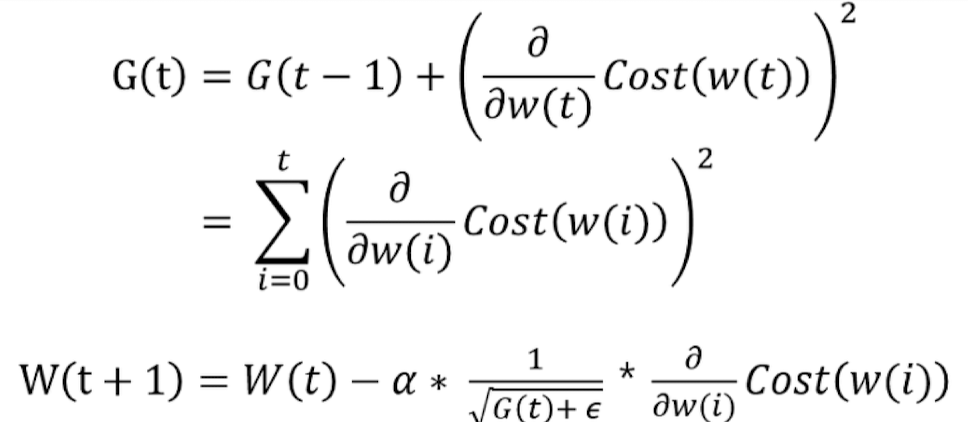
G(t): t번째 time step까지의 기울기 누적 크기
ε: 분모가 0이 되는 것을 방지하기 위한 작은 값 (보통 10^-6)
기울기의 제곱을 누적하여 많이 업데이트가 된 파라미터에 대해서는 학습률을 낮추고 많이 업데이트가 되지 않아서 제곱이 많이 누적되지 않은 파라미터는 학습률이 낮아지지 않는 방식이다.
RMSprop
RMSprop는 딥러닝 최적화 기법 중 하나로써 Root Mean Sqaure Propagation의 약자로 AdaGrad가 기울기를 누적시키는 방식으로 학습이 진행될 때 학습률을 꾸준히 감소시켜서 나중에는 0으로 수렴하여 학습이 더 이상 진행되지 않는 문제가 있어서 이를 개선한 방식이다.
RMSprop은 AdaGrad와 마찬가지로 변수(feature)별로 학습률을 조절하되 기울기 업데이트 방식에서 차이가 있다. 이전 time step에서의 기울기를 단순히 같은 비율로 누적하지 않고 지수이동평균(Exponential Moving Average, EMA)을 활용하여 기울기를 업데이트한다. 가장 최근 time step에서의 기울기는 많이 반영하고 먼 과거의 time step에서의 기울기는 조금만 반영한다는 것이다. Seqeuntial한 데이터를 다루는 딥러닝 기법에서도 좋은 성능을 내는 기술들이 자주 사용한 방식이다.
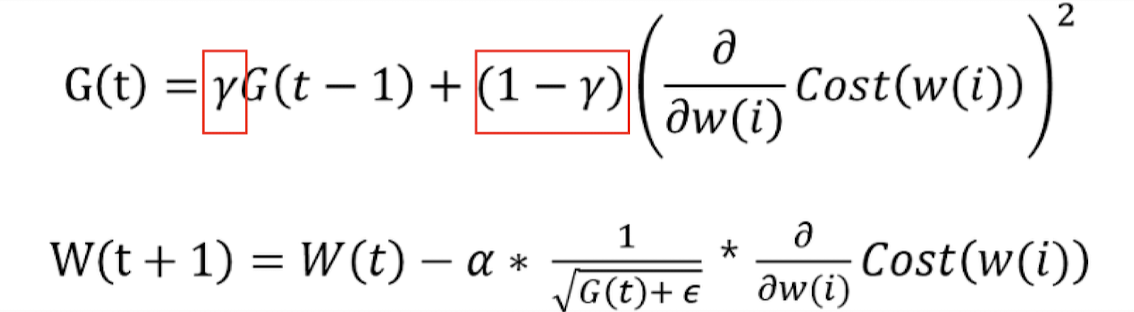
이때 r은 비율을 의미하므로 당연히 0과1 사이의 값이다.
Adam
Adaptive Moment Estimation(Adam)은 딥러닝 최적화 기법 중 하나로써 Momentum과 RMSProp의 장점을 결합한 알고리즘이다. 즉, 학습의 방향과 크기(=Learning rate)를 모두 개선한 기법으로 딥러닝에서 가장 많이 사용되는 최적화 기법으로 알려져 있다.
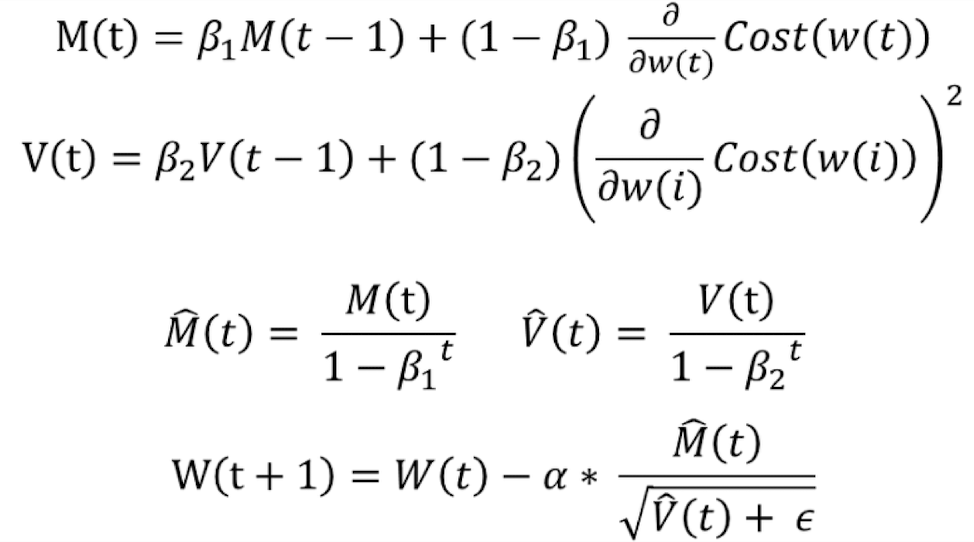
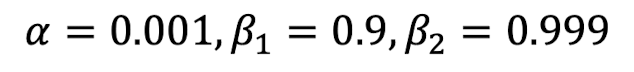
M^(t), V^(t)는 학습 초기에 M(t), V(t)의 값에서 M(t-1), V(t-1)가 0이고 그 뒤에 더해지는 값도 너무 작기 때문에 0에 수렴하는 것을 방지하기 위한 보정값이다. 이 값을 만드는 과정을 편향 보정(bias correction)이라고 한다. 학습이 계속되다보면 (1-b1)과 (1-b2)가 1에 수렴하여 M^(t), V^(t)는 결국 M(t), V(t)와 같은 값이 된다.
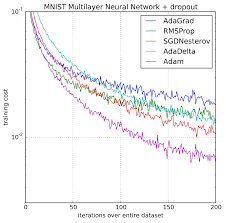
'Univ. Study > AI Applications' 카테고리의 다른 글
| Regularization / Dimensional Reduction and Expansion (0) | 2024.05.04 |
|---|---|
| Computational Graph / Backpropagation (1) | 2024.05.03 |
| 시험 대비 코드 정리(2) (0) | 2024.04.22 |
| 시험 대비 코드 정리(1) (0) | 2024.04.19 |
| Softmax classifier (0) | 2024.03.31 |

