Abstract
기본적으로 해당 논문은 이미지와 텍스트 학습의 새로운 접근으로 이미지+텍스트 Multi-Modal분야의 입문 논문으로 많이들 얘기한다.
컴퓨터 비전 기법은 사전에 정해진 일련의 객체 카테고리를 예측하도록 훈련된다. 이러한 제한적인 감독은 시스템의 일반성과 사용성을 제한하며, 다른 시각적 개념을 명시하려면 추가적인 레이블이 필요하다. 이미지에 대한 원시 텍스트로부터 직접 학습하는 것은 훨씬 더 넓은 감독 소스를 활용하는 좋은 대안이다. 이 연구에서는 어떤 캡션과 어떤 이미지가 일치하는지 예측하는 간단한 사전 훈련 과제가 인터넷에서 수집된 4억 개의 (이미지, 텍스트) 쌍 데이터셋에서 처음부터 최신 이미지 표현을 학습하는 효율적이고 확장 가능한 방법임을 보여준다. 사전 학습 후, 자연어를 사용하여 학습된 시각적 개념을 참조하거나 새로운 개념을 설명함으로써 모델을 downstream task에 제로샷으로 transfer할 수 있다. 이 접근 방식의 성능을 OCR, 비디오 내 액션 인식, 지리적 위치 파악, 다양한 종류의 세밀한 객체 분류 등 30개 이상의 다양한 기존 컴퓨터 비전 데이터셋에서 벤치마킹하여 연구하였다.
Intro
최근 몇 년간 raw text data로부터 직접 학습하는 pre-train기법이 자연어 처리(NLP) 분야에 혁명을 일으켰다. 이러한 방법들은 작업에 구애받지 않는 목표를 사용하여 모델의 용량과 데이터 처리량을 크게 확장시키면서 기능을 지속적으로 향상시켰다. 특히, "Text-to-text"라는 표준화된 Input-Output 인터페이스가 개발되어 데이터셋 특화된 구성 없이도 downstream 데이터셋으로의 제로샷 transfer가 가능하게 되었다. 이러한 성과를 바탕으로, GPT-3와 같은 주요 시스템들은 맞춤형 모델과 경쟁하면서 거의 또는 전혀 데이터셋 특화 훈련 데이터 없이 여러 작업에서 경쟁력을 보여주고 있다.
그러나 컴퓨터 비전 분야에서는 아직도 사전 훈련 모델을 ImageNet과 같은 군중 레이블이 붙은 데이터셋을 사용하는 것이 일반적이다. 웹 텍스트에서 직접 학습하는 확장 가능한 사전 훈련 방법이 컴퓨터 비전에서도 유사한 혁신을 이룰 수 있다는 가능성을 선행 연구들이 시사하고 있다.
이러한 연구들은 NLP의 supervised learning을 사용하는 이미지 표현 학습에 대한 유망한 가능성을 제시하고 있지만, 일반적인 벤치마크에서의 성능은 대체 방법들보다 훨씬 낮은 경우가 많다. 그럼에도 불구하고, 인스타그램 이미지에서 ImageNet 관련 해시태그를 예측하는 것과 같이 좁은 범위에서 타겟팅된 약한 supervised learning은 성능을 향상시키는 데 효과적입니다. 최근에는, VirTex, ICMLM, ConVIRT와 같은 연구들이 트랜스포머 기반의 언어 모델링, 마스크된 언어 모델링, 대조적 목표를 사용하여 텍스트로부터 이미지 표현을 학습하는 잠재력을 입증하고 있습니다.
본 연구에서는 NLP supervising을 통해 대규모로 이미지 분류기를 훈련하는 방법을 연구한다. 인터넷에서 공개적으로 이용 가능한 대량의 데이터를 활용하여 4억 개의 (이미지, 텍스트) 쌍으로 구성된 새로운 데이터셋을 만들고, ConVIRT의 단순화된 버전인 CLIP을 통해 자연어 감독에서 학습하는 방법을 보여준다. CLIP은 다양한 task에서 transfer learning을 수행하며, 30개 이상의 기존 데이터셋에서 제로샷 transfer 성능을 벤치마킹하여 tansfer task 특화 supervised 모델과 경쟁력이 있음을 확인했다.
Training Architecture
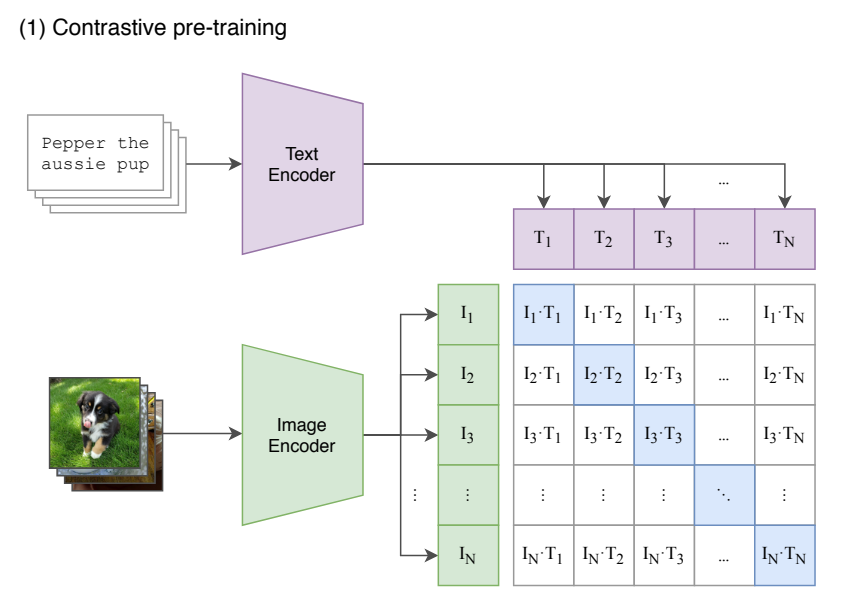
기본적으로 위와 같은 구조로 CLIP은 contrastive learning을 수행한다. Constarstive Learning은 매칭되는 데이터 Feature들은 가까워지고, 나머지 Feature들끼리는 멀어지도록 학습하는 방법을 의미한다. 이러한 Constrastive Learning은 Self Supervised Learning 에서 성능이 잘나온다. Label 정보가 없어도, 어떠한 기준으로 나와 매칭되는지만 설정해주면 학습을 진행할 수 있기 때문이다. 대표 사례로는 SimCLR이 있는데, 입력이미지에 Augmentation을 적용 해 동일한 이미지 버전끼리는 가까워지도록, 다른 이미지 버전과는 멀어지도록 학습했다.
위 그림을 좀더 자세히 보면 CLIP의 Constrastive Learning을 설명한 그림으로, 파란색으로 칠해져 있는 부분이 Positive Pair를 의미한다. 나머지는 Negative Pair를 의미한다. 데이터셋은 이미지와 이 이미지에 매칭되는 자연어로 구성되어 있고, 이미지는 Image Encoder로, 자연어는 Text Encoder 로 Feature를 추출한다. T는 텍스트를 의미하고, I는 이미지를 의미하며, N은 배치 개수를 의미한다.
총 N개의 Image Feature가 있고, 마찬가지로, N개의 Text Feature가 추출되며, N X N 조합이 나오는것을 알 수 있다. Constrastive Learning 은 나와 매칭되는 조합은 가까워지도록, 그외의 조합은 멀어지도록 학습하는 방법이라고 했는데 여기서, 가깝다는 의미는 두 Feature의 Cosine Similiarity가 커지는 방향을 의미한다. 두개의 Feature가 공간상에서 가까운 각도에 위치할수록 Cosine Similarity는 큰 값을 갖기 때문이다. 반대로 나머지 쌍과는 멀어지도록 모델을 학습한다. 여기서 모델은 Image Encoder와 Text Encoder를 의미한다.

위의 그림은 이미지 분류를 위한 Zero-shot transfer를 위한 과정이다. 이미지가 주어지면 데이터셋의 모든 class와의 (image, text) 쌍에 대해 유사도를 측정하고 가장 그럴듯한(probable) 쌍을 출력합니다. 구체적으로는 위 그림과 같이, 각 class name을 "A photo of a {class}." 형식의 문장으로 바꾼 뒤, 주어진 이미지와 유사도를 모든 class에 대해 측정하는 방식을 활용한다.

이번엔 encoder에 대해서 알아보자.
Image encoder : 2개의 architecture를 사용한다. ResNet-50에서 약간 수정된 버전인 ResNet-D 버전을 사용한다. Global Average Pooling을 Attention Pooling으로 대체하였다는 점이 특징이다. 또한 ViT도 사용한다. Layer Norm 추가 외에는 기존과 동일하게 사용한다. 총 5개의 ResNet과 3개의 ViT를 downstream model로 선정하여 training을 하였다. 이미지 하나하나를 Image Encoder에 통과시키며, 이미지를 하나의 벡터값으로 표현한다. 다음으로 추출된 벡터에 가중치 행렬을 한번 더 곱하고, L2-normalization을 수행하여 각 벡터들을 임베딩(embedding)을 진행한다.
Text encoder : 기존 Transformer를 사용했다. max_length=76인데, 실제 구현체에서는 마지막 token을 고려하여 77로 설정되어있다. 여기서도 각 이미지를 설명하는 텍스트를 Text Encoder에 통과시킨다. 이 때 텍스트 토큰 중 문장의 끝을 나타내는 [EOS] 토큰의 벡터값을 텍스트 전체의 벡터로 학습시킨다. Encoder의 역할은 이미지, 텍스트로부터 각각의 특성벡터를 추출하는 역할을 수행한다. 이미지와 마찬가지로 추출된 벡터에 가중치 행렬을 한번더 곱하고, L2-normalization을 수행하여 각 벡터들을 임베딩(embedding)을 진행한다.

위는 CLIP의 implementation code이다.
그 결과 아래와 같이 다른 방법들보다 압도적인 성능을 냈다고 주장한다.

Experiment

CLIP 모델과 이전의 Visual N-Grams 방법을 비교하여 제로샷 전이 이미지 분류에서의 성능을 보여주고 있다. 세 개의 데이터셋 aYahoo, ImageNet, SUN에서 모두 성능이 굉장히 많이 개선된것을 볼 수 있다.

"Contextless class names" 방법과 "Prompt engineering and ensembling" 방법을 비교하여 각 방법의 성능을 다양한 모델 크기에 따른 계산량 (GFLOPs)과 함께 평가한다. 모델 크기가 커질수록 성능이 향상되지만, 상대적으로 완만한 성장을 보여준다. 기존 방법에 비해 전반적으로 높은 성능을 보여주며, 특히 모델의 계산량이 증가할수록 그 성능 차이가 두드러진다. 프롬프트 엔지니어링과 앙상블 기법은 제로샷 분류 작업에서 기존의 컨텍스트 없는 클래스 이름 방법보다 뛰어난 성능을 제공한다. 특히, 더 많은 계산 리소스를 사용할 때의 성능 향상은 중요한 의미를 가지며, 이러한 방법들이 제로샷 분류에서의 효율성과 정확성을 크게 향상시킬 수 있음을 보여준다.
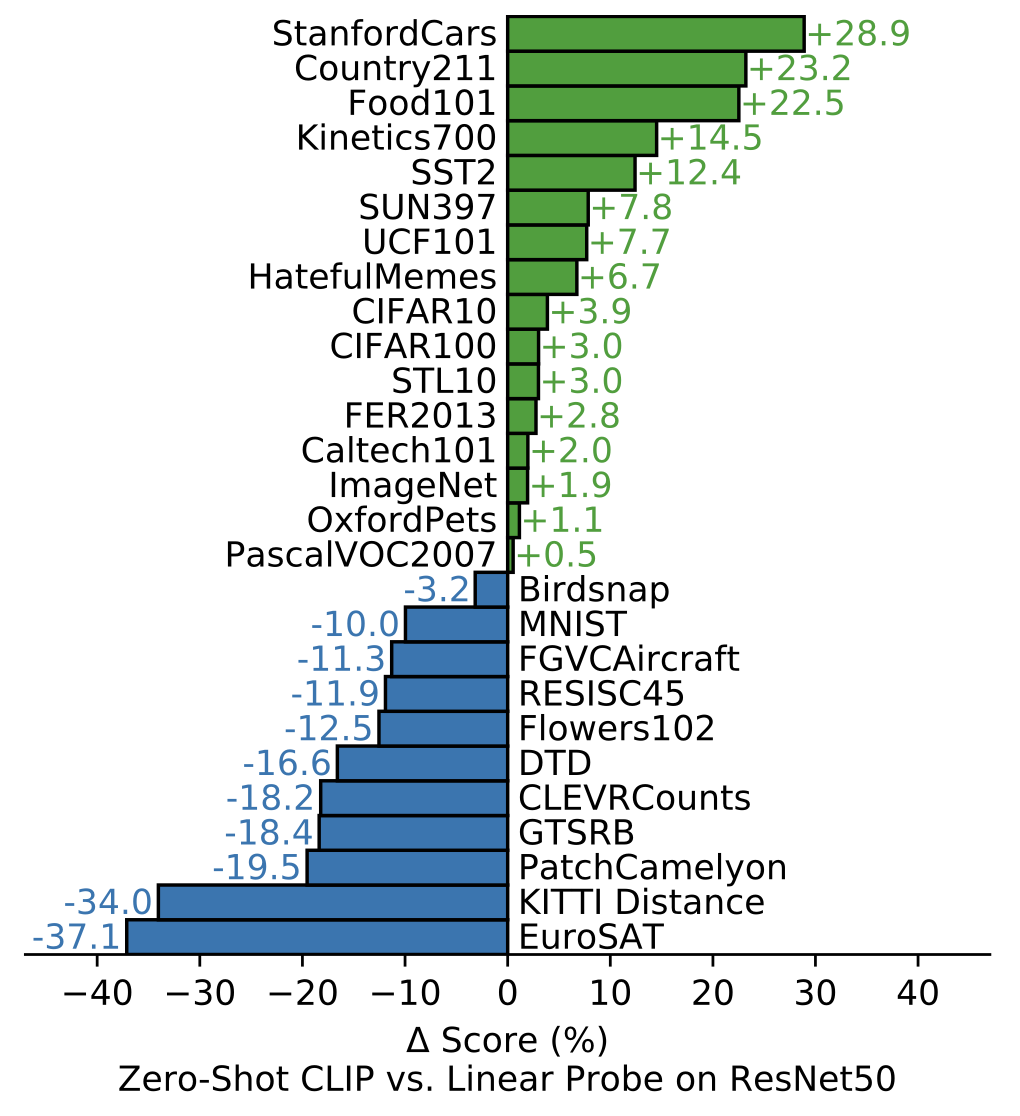
27개 데이터셋 평가 모음을 통해, 제로샷 CLIP 분류기는 ImageNet을 포함한 16개 데이터셋에서 ResNet-50 특성에 적합한 fully-supervised baseline의 성능을 능가하는 것을 확인할 수 있다.
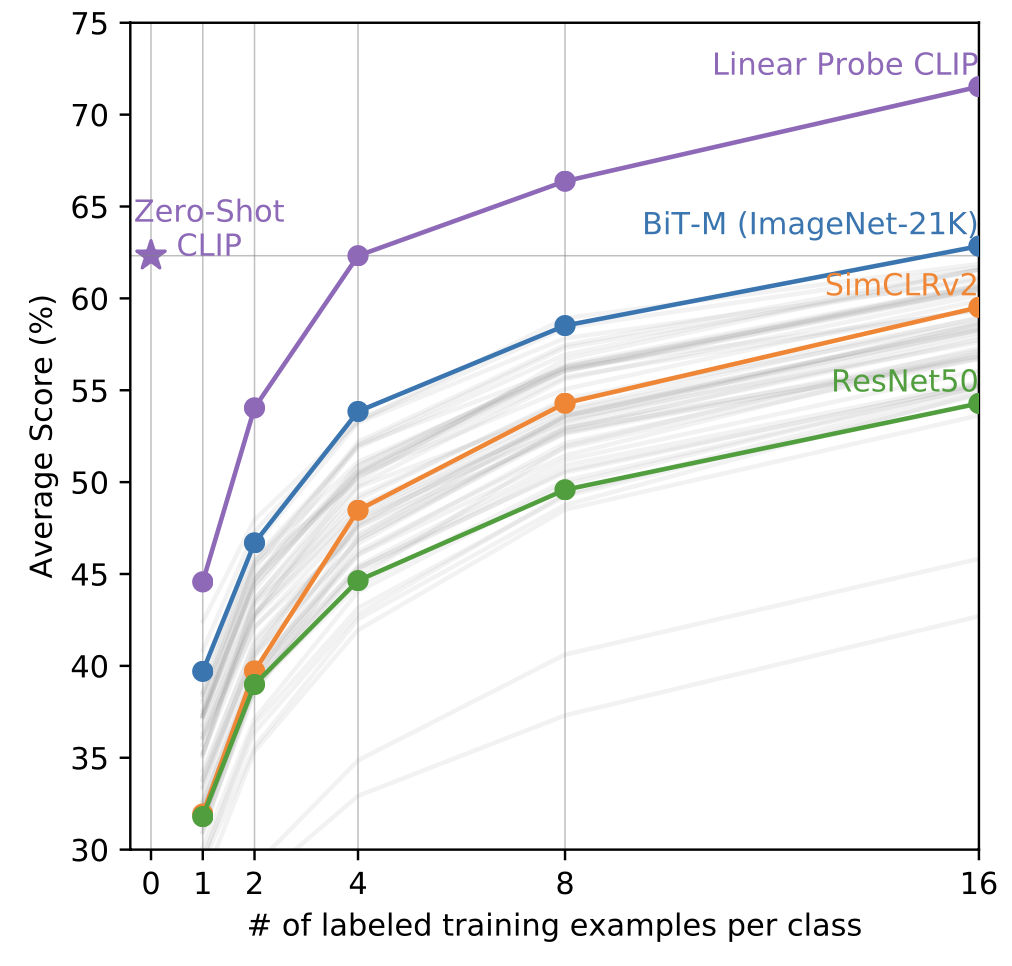
Zero-shot CLIP은 few-shot linear probing의 성능을 능가한다. Zero-shot CLIP은 동일한 feature space에서 훈련된 4-shot linear classifier의 평균 성능과 일치하며, 공개적으로 이용 가능한 모델들 중 최고 결과를 내는 16-shot linear classifier의 결과에 거의 근접한다.
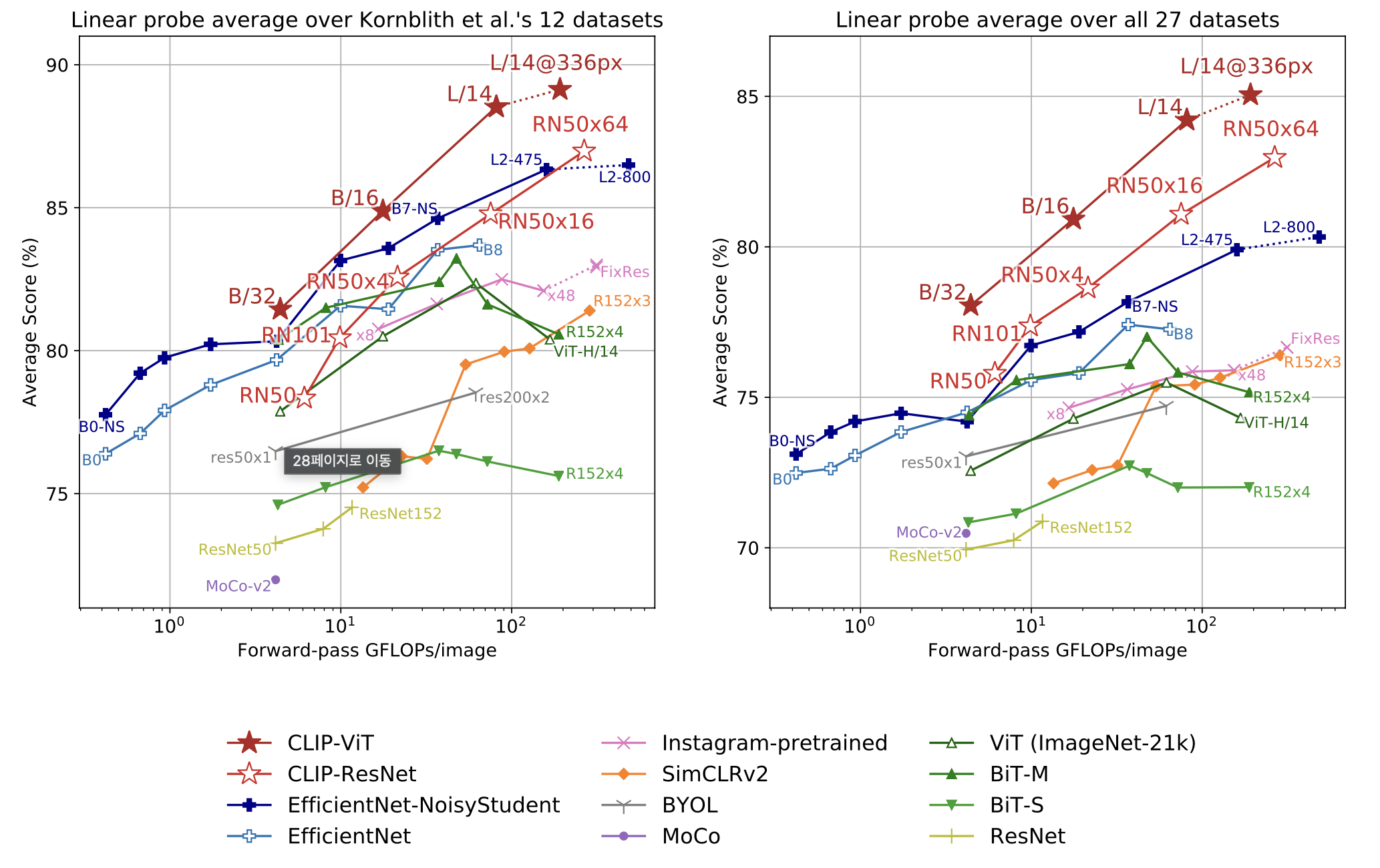
논문의 70%정도가 성능 평가 테스트 결과일 정도로 성능을 보여주는 지표는 많지만 마지막으로 기존의 SOTA CV model들과 성능 비교를 하며 글을 마치려고 한다.
추후 Multi-modal을 이어서 공부하는데 큰 도움이 될 것 같은 논문을 접하게되는 좋은 기회였다.



