Dynamic Programming
Dynamic Programming은 동적 계획법이라는 뜻이지만 실제로 그렇게 동적이지는 않다. 오히려 기록해둔 과거 기록을 저장해두고 꺼내서 이용한다는 점에서 Tabular Method라는 이름이 어울린다.
Divide-And-Conquer는 top-down approach로 나누어진 부분들 사이에 서로 상관관계가 없는 문제를 해결하는데 적합하다. 반면Dynamic programming은 bottom-up approach로 큰 문제를 작은 문제로 나눈 다는 점은 Divide-And-Conquer와 동일하나 작은 문제를 먼저 해결하고, 그 결과를 저장한 다음, 후에 그 결과가 필요할 때마다 다시 계산하는 것이 아니고 그 저장된 결과를 이용한다는 점이 다르다. 해답을 구축하는데 배열을 사용한다는 뜻이기도 하다.
DP방식의 해결법은 최적화 문제와 같은 경우에 사용하기 적합하다.
최소치 또는 최대치를 구하는 최적화 문제에서 최적해는 여러 개가 있을 수 있지만 그 중의 어느 하나를 구하면 된다. 최적해는 기본적인 소문제의 최적해로부터 더 큰 크기의 소문제의 최적해를 구하는 과정을 거치기에 DP방식을 적용하기에 매우 적합하다.
최적성의 원리(principle of optimality)는 주어진 문제의 부분의 해가 전체 문제의 해를 구성하는데 사용한다는 것이 핵심이다. 동적 계획법으로 문제를 해결하려면, 그 문제가 최적성의 원리를 만족해야 한다.
일반적인 DP문제의 풀이 방식은 아래와 같다.
① 문제의 특성을 분석하여 최적성의 원리가 적용되는지 확인
② 주어진 문제를 소문제로 분해하여 최적해를 제공하는 점화식 도출
③ 입력 크기가 작을 때 도출된 점화식의 해를 구함
④ 이 해를 이용하여 점차적으로 입력 크기가 클 때의 점화식의 최적해를 구함
최적의 원칙이 적용되지 않는 예시를 살펴보자. 아래는 최장경로 문제이다.

v 1에서 v 4로의 최장경로는 [v1, v3, v2, v4]가 된다.
그러나, 이 경로의 부분 경로인 v1에서 v3으로의 최장경로는 [v1, v3]이 아니고, [v1, v2, v3]이다.
따라서 최적의 원칙이 적용되지 않는다.
Dynamic Programming 예제
우선 아주 단순한 예제들을 살펴보자.
1과 2의 합
정수 n(2<= n<=100)이 주어져있을때 이 n을 1과 2의 합만으로 나타낼 수 있는 방법의 수를 구하시오.
예를 들어 n=4인 경우는 아래와 같이 5가지 임.
4 = 1+1+1+1
= 2+1+1
= 1+2+1
= 1+1+2
= 2+2
n을 만드는 방법은 n-1에 1을 더하거나 n-2에 2를 더하는 것이다. 따라서 n-1을 만드는 방법과 n-2를 만드는 방법의 가지수의 합이 n을 만드는 방법의 가지수가 될 것이다.
따라서 f(n)=f(n-1)+f(n-2) (초기값 f(2)=2, f(3)=3)
숫자판 놀이
숫자들이 2차원 배열에 있다. 가장 윗 행에서 가장 아래 행까지 내려올때 걸쳐지는 길에 있는 숫자의 합이 가장 높은것을 찾아보자. 이 때 어느 한 cell에서 다음 cell로 내려올 경우에는 바로아래, 왼쪽대각선아래, 오른쪽대각선 아래로만 이동이 가능하다.

이러한 아래로 전파하는 문제는 아래와 같은 방식을 이용한다.
| i-1, j-1 | i-1, j | i-1, j+1 |
| i, j |
i, j 지점에서 위의 세 값중 가장 큰값을 수용하여 더하고 본인의 값을 갱신한다. 이를 수식화 하면 아래와 같다.
A[i, j] = max(A[i-1, j-1], A[i-1, j], A[i-1, j-1]) + A[i, j]
치즈
어떤 쥐가 p[n][m]로 구성된 미로에 있을 때 왼쪽 아래 즉, p[0][0]에서 시작하여 출구가 있는 p[n-1][m-1]에 도달하려고 한다.
단, 이 쥐는 항상 오른쪽 또는 위쪽으로만 움직일 수 있으며 치즈를 최대한 많이먹으면서 출구로 이동하여야 한다.
이 문제의 recursive property를 제시하고 치즈의 최대값을 구하시오.
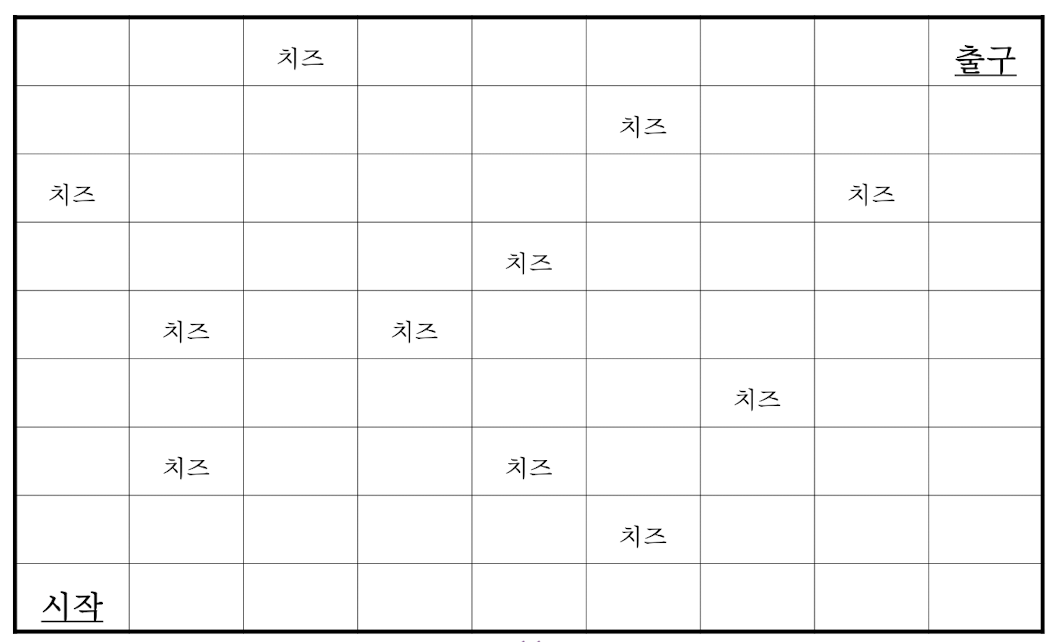
위의 숫자판 놀이 문제와 굉장히 유사한 방법을 이용한다.
| i, j-1 | i, j |
| i-1, j |
A[i, j] = max(A[i-1, j], A[i-1, j]) + A[i, j]
스트링 편집 거리
이번에는 스트링 편집 거리 문제를 살펴보자. 흔히 Levenshtein Distance(LD)라고도 불린다. 두 스트링의 유사도를 측정하기 위해 사용하는 거리이다.
원래 스트링을 S, 목표 스트링을 T라고 두고 S를 T로 변환하는데 필요한 삽입, 삭제, 대치 연산의 최소 비용을 계산하는 것이다.
S = “test”, T=“test” => LD(S, T) = 0 이와 같이 source와 target이 같으면 거리가 0이 된다.
S = “test”, T=“tent” => LD(S, T) = 1 그러나 이와 같이 하나의 텍스트가 바뀌면 변환의 비용이 1이라고 했을 때 1이 나오는 것이다.
편집 거리가 커질수록, 두 스트링의 유사도는 낮아지게 된다.
점화식은 아래와 같이 비용을 가정하고 구할 수 있다.
- 삽입 연산의 비용 : δI
- 삭제 연산의 비용 : δD
- 대치 연산의 비용 : δS
D[i,j] : S = s1s2…si와 T = t1t2…tj 사이의 편집 거리
D[i,j] = min(D[i,j-1] + δI, D[i-1,j] + δD, D[i-1,j-1] + 0/δS)
(여기서 0/δS는 si = tj이면 0이고, 그렇지 않으면 δS임을 의미한다.)
δI = δD = δS = 1인 경우의 점화식은 다음과 같다.
D[i,j] = min(D[i,j-1] + 1, D[i-1,j] + 1, D[i-1,j-1] + 0/1)
Source값인 GUMBO를 Target인 GAMBOL 로 변경하는 스트링 편집 거리를 구하는 과정을 살펴보자.


G에서 A를 insert하면 GA가 되기 때문에 1이 채워지는 모습이다.
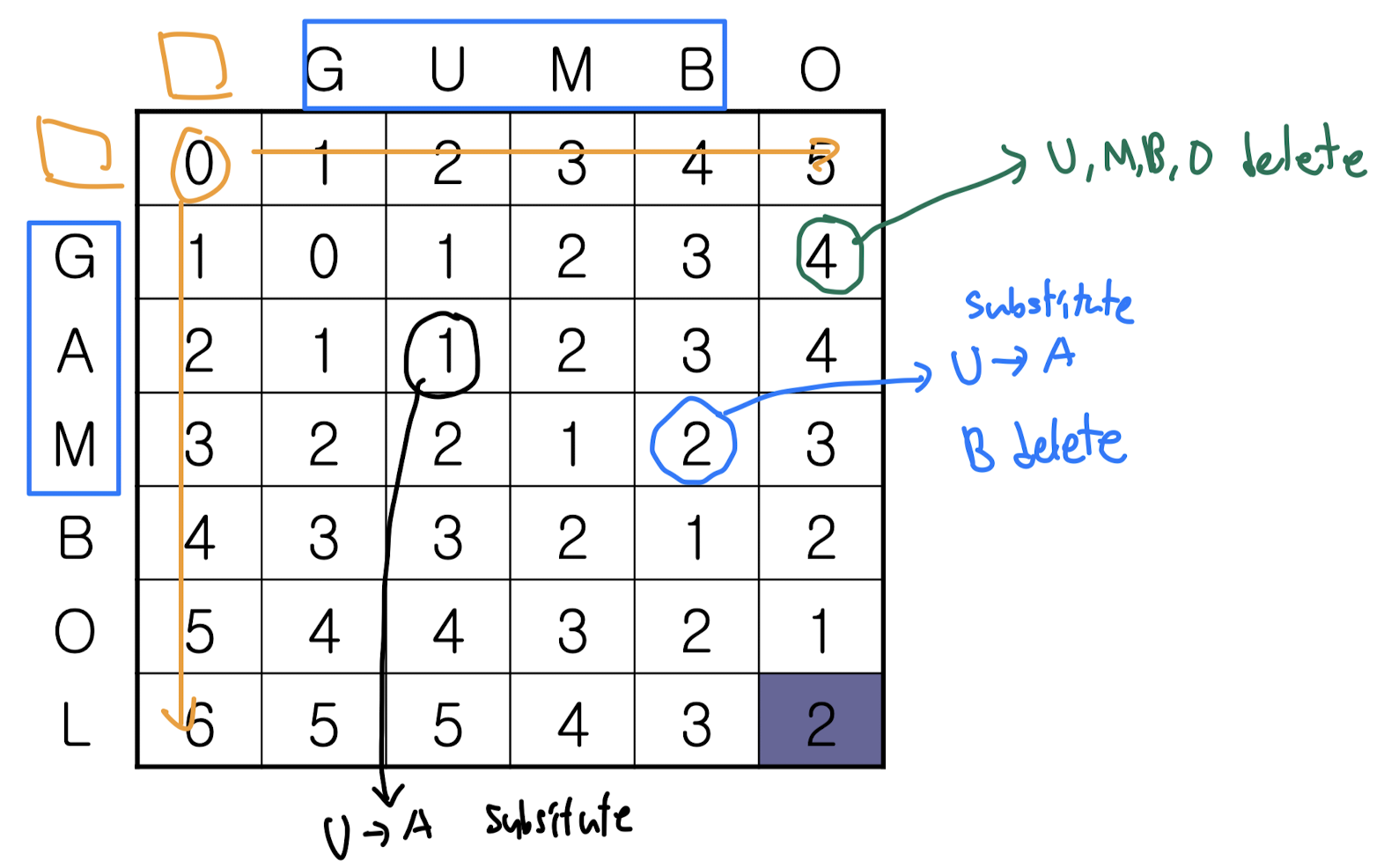
다양한 케이스들을 따져보며 표를 채우면 원하는 LD를 모두 찾을 찾을 수 있다.
δI = δD = δS = 1인 경우 알고리즘의 pseudo code는 아래와 같이 구조가 짜여질 것이다.
EditDistance(s[], t[], m, n)
// 문자 배열 s[1,m], t[1,n]
D[0,0] ← 0;
for (i ← 1; i ≤ n; i ← i + 1) do
D[i,0] ← D[i-1,0] + 1;
for (j ← 1; j ≤ m; j ← j + 1) do
D[0,j] ← D[0,j-1] + 1;
for (i ← 1; i ≤ n; i ← i + 1) do
for (j ← 1; j ≤ m; j ← j + 1) do {
if (s[i] = t[j]) then cost ← 0;
else c ← 1;
D[i,j] ← min(D[i,j-1] + 1, D[i-1,j] + 1, D[i-1,j-1] + cost);
}
return D[n,m];
end EditDistance()'Univ. Study > Algorithm Design' 카테고리의 다른 글
| 알고리즘 설계 실습 - 삼각분할 (0) | 2024.05.08 |
|---|---|
| Algorithm design - Matrix-chain Multiplication (0) | 2024.05.07 |
| 알고리즘 설계 실습 - Fibo_counter (4) | 2024.05.01 |
| Algorithm Design - Huffman encoding / Encryption / RSA (1) | 2024.04.18 |
| 알고리즘 설계 실습 - KMP (0) | 2024.04.17 |


