Concurrency Control
DB는 여러 사용자가 접근할 수 있다. 동시 공용(Concurrent Sharing)의 이점은 공용도(sharability)의 증가, 응답 시간(response time)의 단축, 시스템 활용도(system utilization) 증대와 같은 점들이 있다.

위와 같이 serial schedule보다 병행 실행일때 효율적이다.
그러나 병행실행을 control하지 못하고 그저 실행하기만 하면 아래와 같은 문제가 발생하여 Concurrency Control이 필요하다.
Dirty read문제는 commit되지 않은 데이터를 읽을때 발생하는 문제로 아래와 같은 경우가 있다.
A와 B가 각각 5와 3이라면 T1에서는 A와 B가 각각 10과 6으로 바뀌었지만 해당사실을 알지 못하는 T2에서는 sum(A,B)의 결과가 8로 나오게 된다.
Non-repeatable Read문제는 Unreapetable Read라고도 불리고 똑같은 값을 두번 불렀는데 그 값이 다르게 출력되는 현상을 이야기한다.
A의 초기값이 5였는데 T1에서 A=10으로 update되면 T2의 첫번째 read와 두번째 read가 달라진다.
Phantom Read 문제는 다른 트랜잭션에서 생성한 데이터 때문에 원래 없던 phantom tuple이 생성되는 문제이다.
무제어 동시 공용의 문제점
갱신 분실(Lost Update) - 탐지 불가능
모순성(inconsistency) - DB의 출력 내용과 모순
연쇄 복귀 (Cascading Rollback) - 상호 의존(tangled dependencies), 연쇄 회복(cascade recovery)
Serializable
직렬 가능성을 판단할때 필요한 개념을 가볍게 살펴보자.
스케줄
- 실행 순서
- 트랜잭션 연산들의 순서
직렬 스케줄(serial schedule)
- 트랜잭션의 순차적 실행
- 인터리브드되지 않은 스케줄
- 스케줄의 각 트랜잭션의 모든 연산이 연속적으로 실행
- n! 가지의 방법
- 트랜잭션들이 서로 독립적이라면, 어떠한 직렬 스케줄도 모두 정확하다
비직렬 스케줄(nonserial schedule)
- 인터리브된 스케줄
- 트랜잭션 {T1 ,...,Tn }의 병렬 실행
n개의 트랜잭션 T1 ,...,Tn에 대한 스케줄 S가 똑같은 n개의 트랜잭션에 대한 어떤 직렬 스케줄 S’과 동등하면 스케줄 S는 직렬 가능 스케줄이라고 한다. 아래의 예시를 통해 살펴보자.

위와 같이 두개의 트랜잭션이 있을 때 아래와 같이 진행된다면 직렬 스케줄이다.

하지만 아래와 같이 진행된다면 비직렬 스케줄이다.

직렬 가능성을 검사할때는 선행 그래프(precedence graph)를 구성하여 선행 그래프에 사이클이 없는 경우 직렬이 가능하다고 할 수 있다.
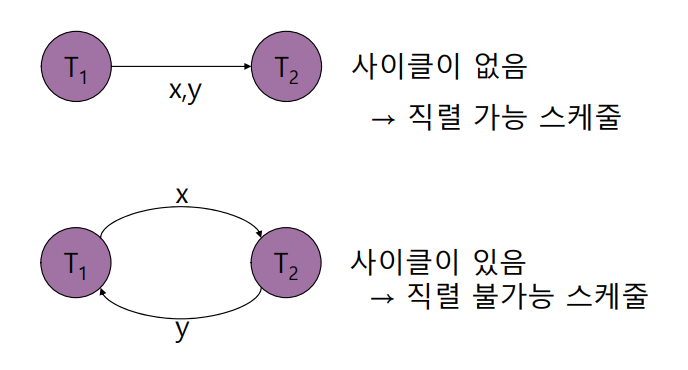
아래의 경우를 보면 사이클이 형성되어 직렬 불가능한 스케줄이다.

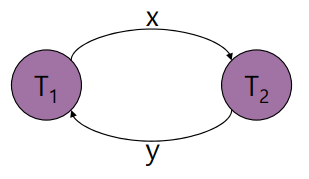
결과는 직렬 스케줄때와 동일하지만 연산이 교환적이어서 직렬 불가능한 스케줄이다.
Locking
로킹은 상호 배제(독점 제어)의 과정 다시 말해 잠금이 된 데이타 집합을 생성하는 과정이다. 데이타 객체에 배타적으로 할당하여 무간섭을 보장한다.
로킹 규약은 다음과 같은 것들이 있다.
① 트랜잭션 T가 read(x)나 write(x) 연산을 하려면 반드시 먼저 lock(x) 연산을 실행해야 한다.
② 트랜잭션 T가 실행한 lock(x)에 대해서는 T가 모든 실행을 종료하기 전에 반드시 unlock(x) 연산을 실행해야 한다.
③ 트랜잭션 T는 다른 트랜잭션에 의해 이미 lock이 걸려 있는 x에 대해 다시 lock(x)를 실행시키지 못 한다.
④ 트랜잭션 T는 x에 lock을 자기가 걸어 놓지 않았다면 unlock(x)를 실행시키지 못 한다.
로킹모드는 크게 두가지가 있다. Shared-lock인 lock-S는 read 연산을 허용해주는 모드이고 exclusive-lock인 lock-X는 read와 write연산을 모두 불허하는 모드이다.
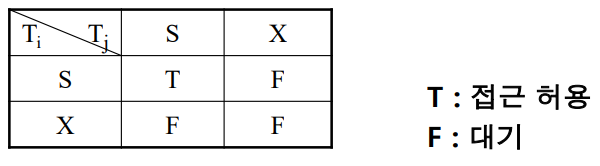
공용 로킹 규약
① 트랜잭션 T가 데이타 아이템 x에 대해 read(x) 연산을 실행하려면 먼저 lock-S(x)나 lock-X(x) 연산을 실행해야 한다.
② 트랜잭션 T가 데이타 아이템 x에 대해 write(x) 연산을 실행하려면 먼저 lock-X(x) 연산을 실행해야 한다.
③ 트랜잭션 T가 lock-S(x)나 lock-X(x) 연산을 하려 할 때 x가 이미 다른 트랜잭션에의해양립될 수 없는 타입으로 lock이 걸려 있다면 그것이 모두 풀릴 때까지 기다려야 한다.
④ 트랜잭션 T가 모든 실행을 종료하기 전에는 T가 실행한 모든 lock(x)에 대해 반드시 unlock(x)를 실행해야 한다.
⑤ 트랜잭션 T는 자기가 lock을 걸지 않은 데이타 아이템에 대해 unlock을 실행할 수 없다.

그러나 위와 같이 locking을 해도 여전히 직렬가능이 아니고 직렬일때와 결과가 다르다.
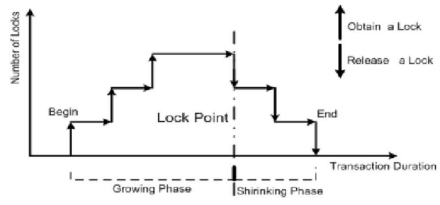
2단계 로킹 규약
2PLP는 확장 단계(growing phase)와 축소 단계(shrinking phase) 두 단계로 구성된다. 확장 단계는 트랜잭션은 lock만 수행하고 unlock은 수행할 수 없는 단계이고 축소 단계는 트랜잭션은 unlock만 수행하고 lock은 수행할 수 없는 단계이다.
이전에는 직렬이 안되던 스케줄을 2PLP를 이용하니 아래와 같이 직렬 가능 스케줄이 되었다.
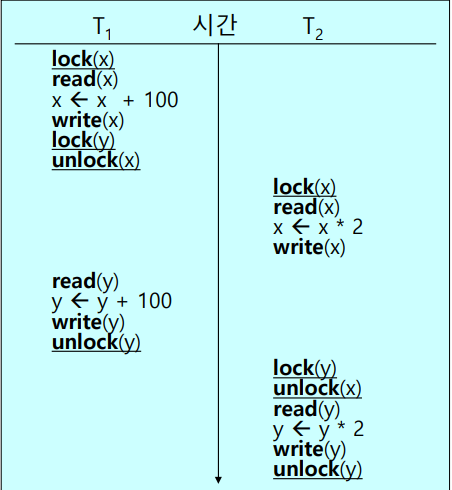
Deadlock
교착 상태는 모든 트랜잭션들이 실행을 전혀 진전시키지 못하고 무한정 기다리고 있는 상태로 다음과 같은 상황이 있을 수 있다. T1은 T2가 데이타 아이템 x를 unlock하기를 기다리고 T2는 T1이 데이타 아이템 y를 unlock하기를 기다리는 상황이다.
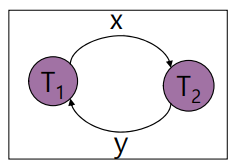
교착 상태는 다음 네가지 조건을 만족할 때 발생한다.
① 상호 배제(mutual exclusion)
② 대기(wait for)
③ 선취 금지(no preempt)
④ 순환 대기(circular wait)
이를 해결하기 위해서 다음의 3가지 방식이 있다.
탐지(detection) : 교착 상태가 일단 일어난 뒤에 교착 상태 발생 조건의 하나를 제거한다.
회피(avoidance) : 자원을 할당할 때마다 교착 상태가 일어나지 않도록 실시간 알고리즘을 사용하여 검사한다.
예방(prevention) : 트랜잭션을 실행시키기 전에 교착 상태 발생이 불가능 하게 만드는 방법이다.
'Univ. Study > Database Design' 카테고리의 다른 글
| Big data (2) | 2023.12.06 |
|---|---|
| NoSQL (0) | 2023.11.28 |
| Transaction (3) | 2023.11.21 |
| Query Optimization (0) | 2023.11.16 |
| INDEX 실습 (0) | 2023.11.14 |



