[논문 리뷰] Attention is all you need (2)
Attention is all you need
NIPS 2017
Decoder
이전 글에서 다뤘던 Encoder의 결과 텐서가 Decoder에서 이된다고 보면 된다.

Decoder는 Encoder와 구조적으로 굉장히 유사하다.
코드로 차이를 살펴보면 아래와 같이 빨간 표시가된 부분에만 차이가 있다.
self attention layer가 decoder에서는 두번 반복되고 두번째 layer는 input에서 차이가 있음을 볼 수 있다. 또한 마스크로 encoder에서는 source mask를 이용한 반면 decoder에서는 target mask를 이용한다.
Masking
인코더에서는 아래와 같이 padding에 대해서 masking을 진행하기 때문 padding masking이라고도 불리지만 디코더에서는 다르다.
디코더에서는 삼각행렬의 윗부분 또한 masking 해주는 것을 볼 수 있다.
그 이유는 Transformer에서는 sequential하게 데이터를 input 받지 않고 한번에 input이 들어온다. 이때 위와 같이 masking을 하면 첫번째 줄에서는 I만 확인할 수 있고 그 다음 줄에서는 I, love 그 다음 줄에서는 I, love, Hodu... 이런식으로 입력이 되어 한번에 attention을 주는 문제를 방지할 수 있다.
decoder에서도 multi-head를 이용하기 때문에 아래의 과정을 거치고 concat을 해준다.
이때 결과는 decoder의 input과 동일한 크기의 tensor이다.
두번째 multi-head attention layer
위의 코드를 살펴볼때 발견한 붉게 표시된 코드에 해당하는 부분이다. 구조는 같지만 forward 시킬때 들어가는 input의 key와 value가 encoder의 output을 이용했다. 이용될 input들은 아래와 같은 방식으로 추출된다.
이후의 방식은 동일하다.
지금까지의 구조의 흐름을 살펴보면 아래와 같이 됨을 알 수 있다.

Regularization
전체적인 구조에서 Drop-out과 Label-Smoothing이 적극 적으로 쓰이는데 이를 간단하게 살펴보자. 우선 Drop-out은 우리가 알고 있는 drop-out이 맞고 forward의 끝부분에서 자주 사용한다. 이를 통해 random하게 node중 몇 %를 제거해서 다양성을 확보한다.

다음으로 Label-Smoothing은 레이블에서의 오류와 overconfidence를 방지하기 위해 아래와 같은 수식을 이용하여 smoothing을 진행한다.

위의 두 방식을 이용하면 실험적으로도 성능이 향상됨을 볼 수 있다.
Last Layers
최종 레이어를 이미지 처리 과정에서 최종적으로 얻은 feature map을 fully connected layer를 통과 시키고 softmax로 결과를 뽑듯이 같은 과정을 거친다.

Inference
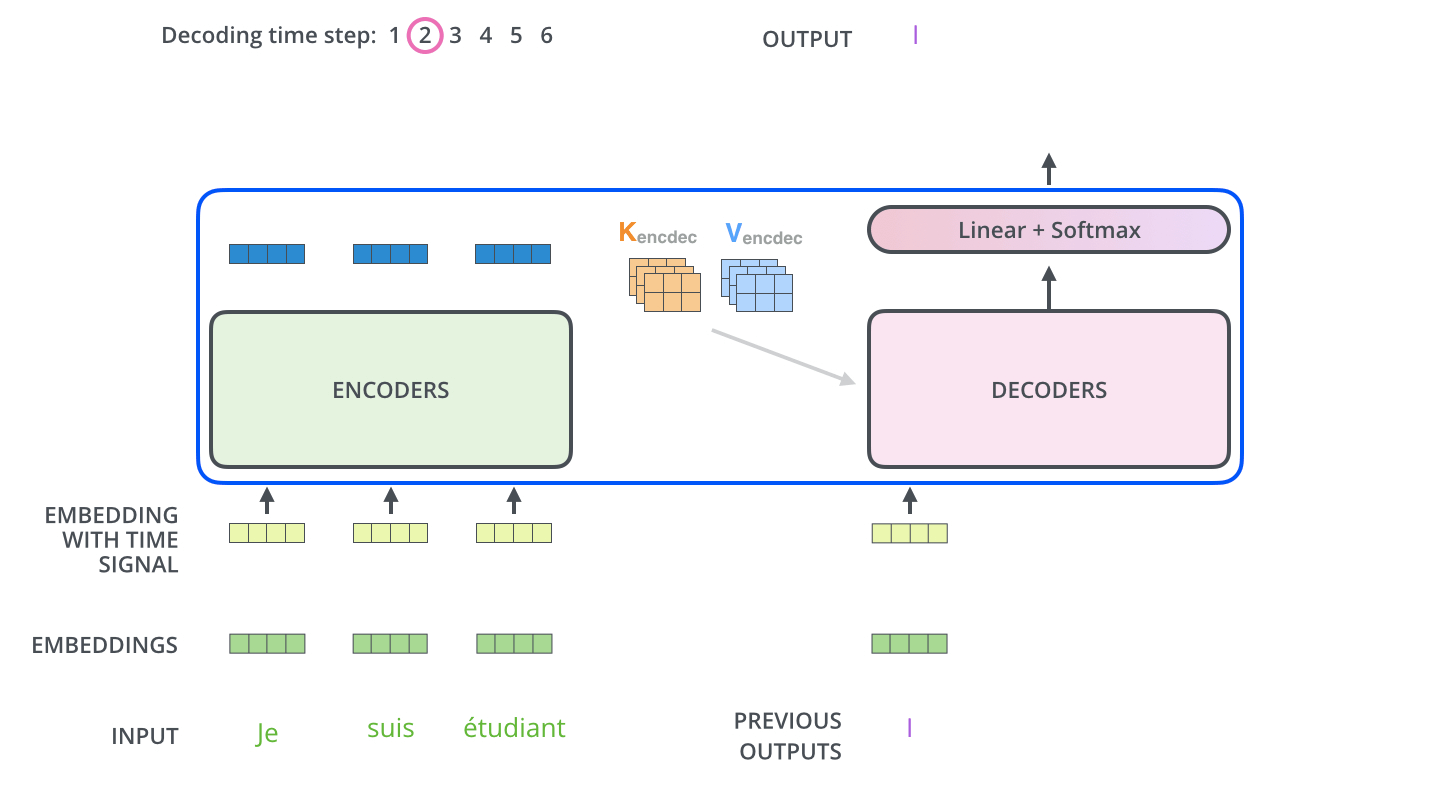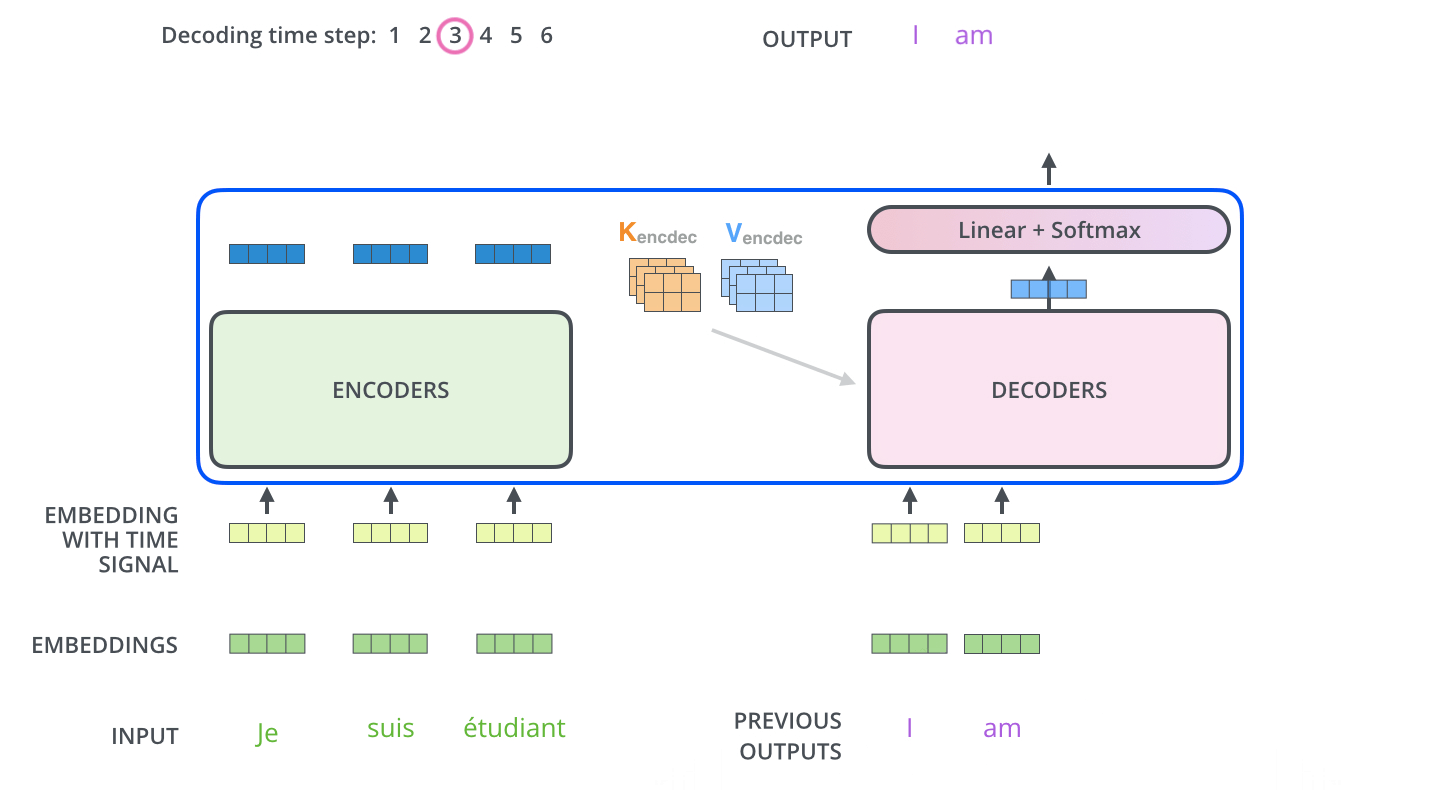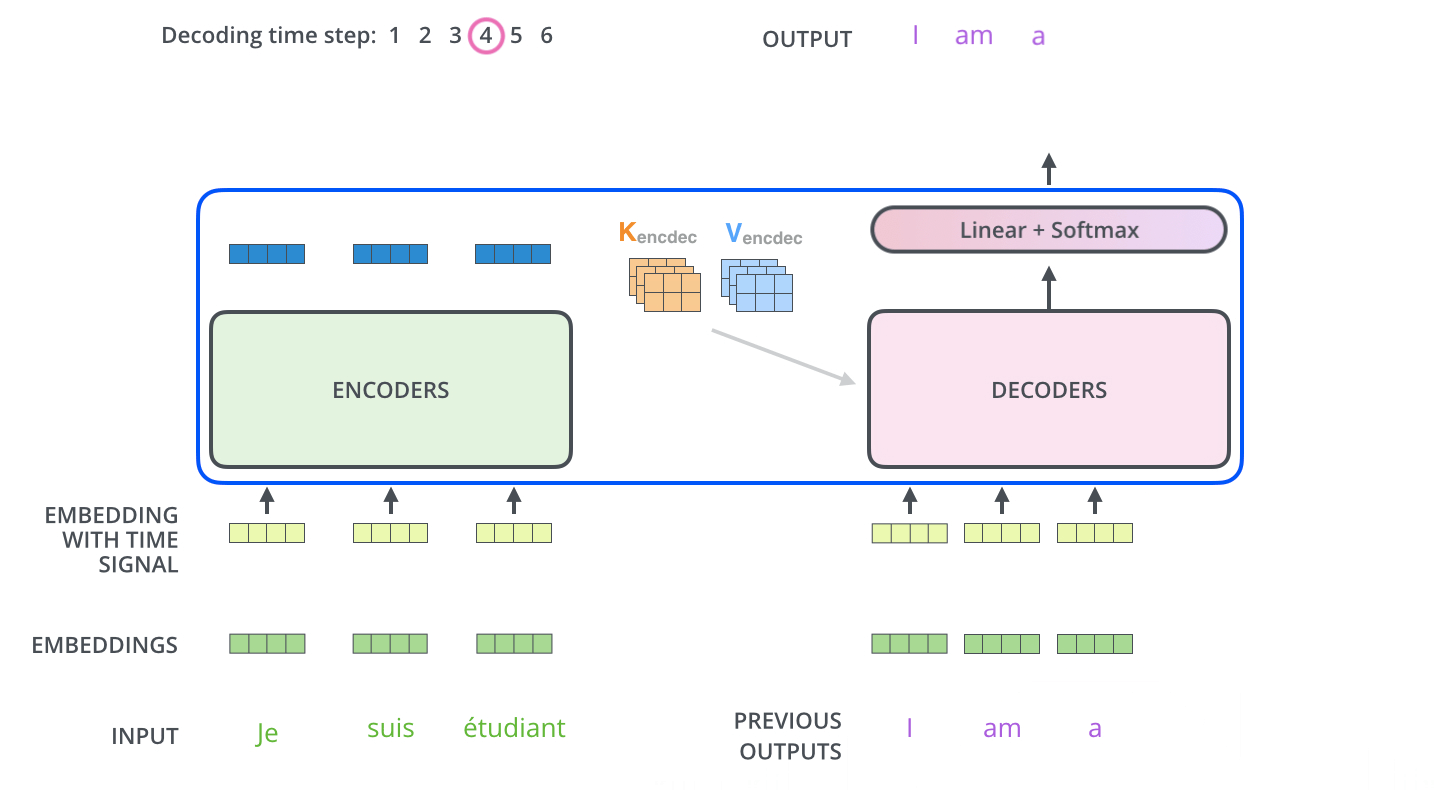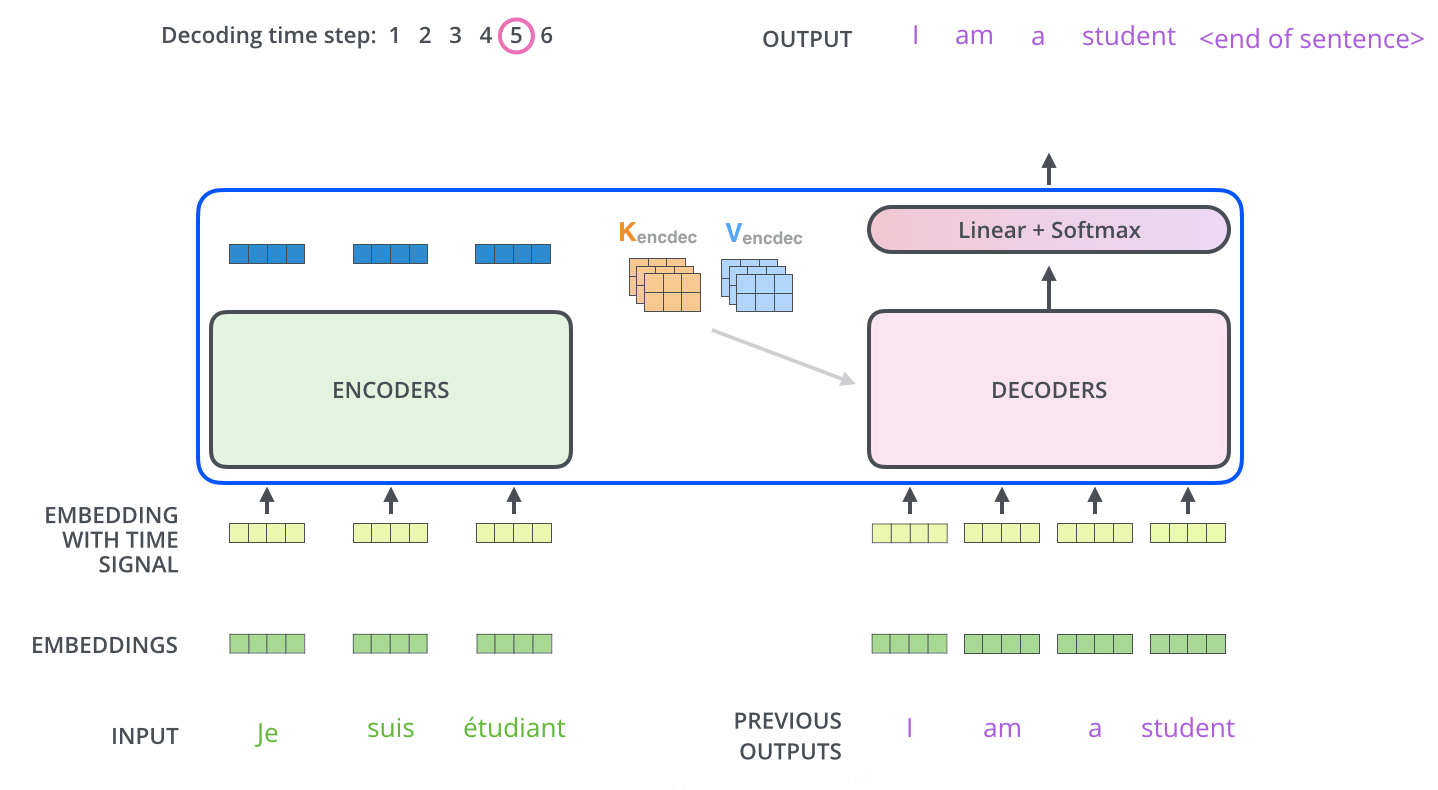
위의 동영상에서 inference 과정을 아주 명확하게 이해할 수 있다.

위의 코드를 보면 _get_the_best_score_and_idx 함수에서는 beam search를 이용하는 것을 볼 수 있다. Beam search는 평가값이 우수한 일정 개수의 확장 가능한 노드만을 메모리에 관리하면서 최상 우선 탐색을 적용하는 기법이다. 즉, best first search에서 기억 노드의 수를 제한하는 방법이다.
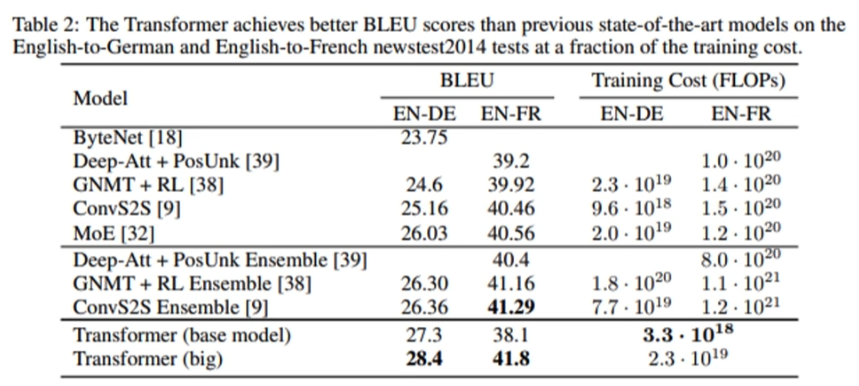
Results
기존의 SOTA model들에 비해서 BLEU score가 높음에도 Training Cost가 낮은 것을 확인할 수 있다.
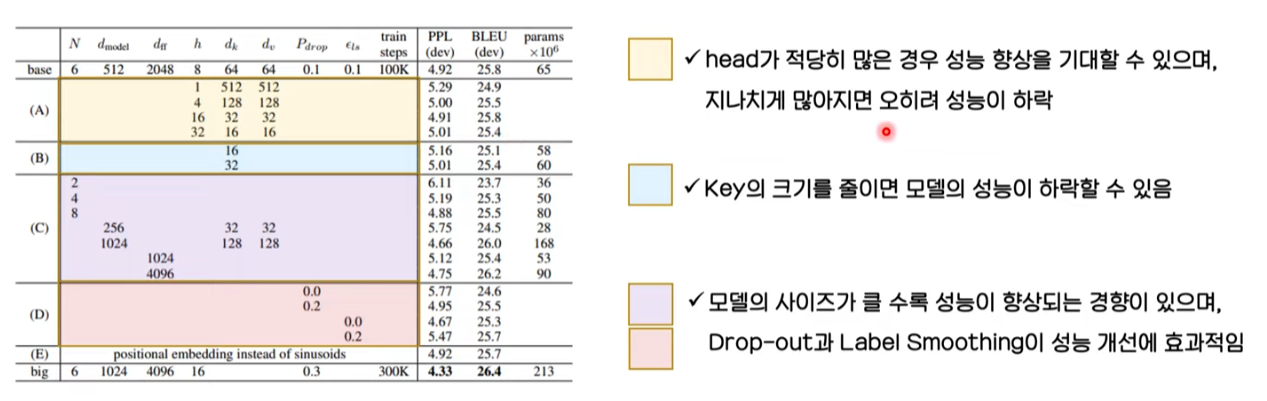
Parameter를 변형해가며 결과를 도출해본 내용이다.